

05 | 调度系统:如何把握分布式计算的精髓?

角色划分与斯巴克建筑集团
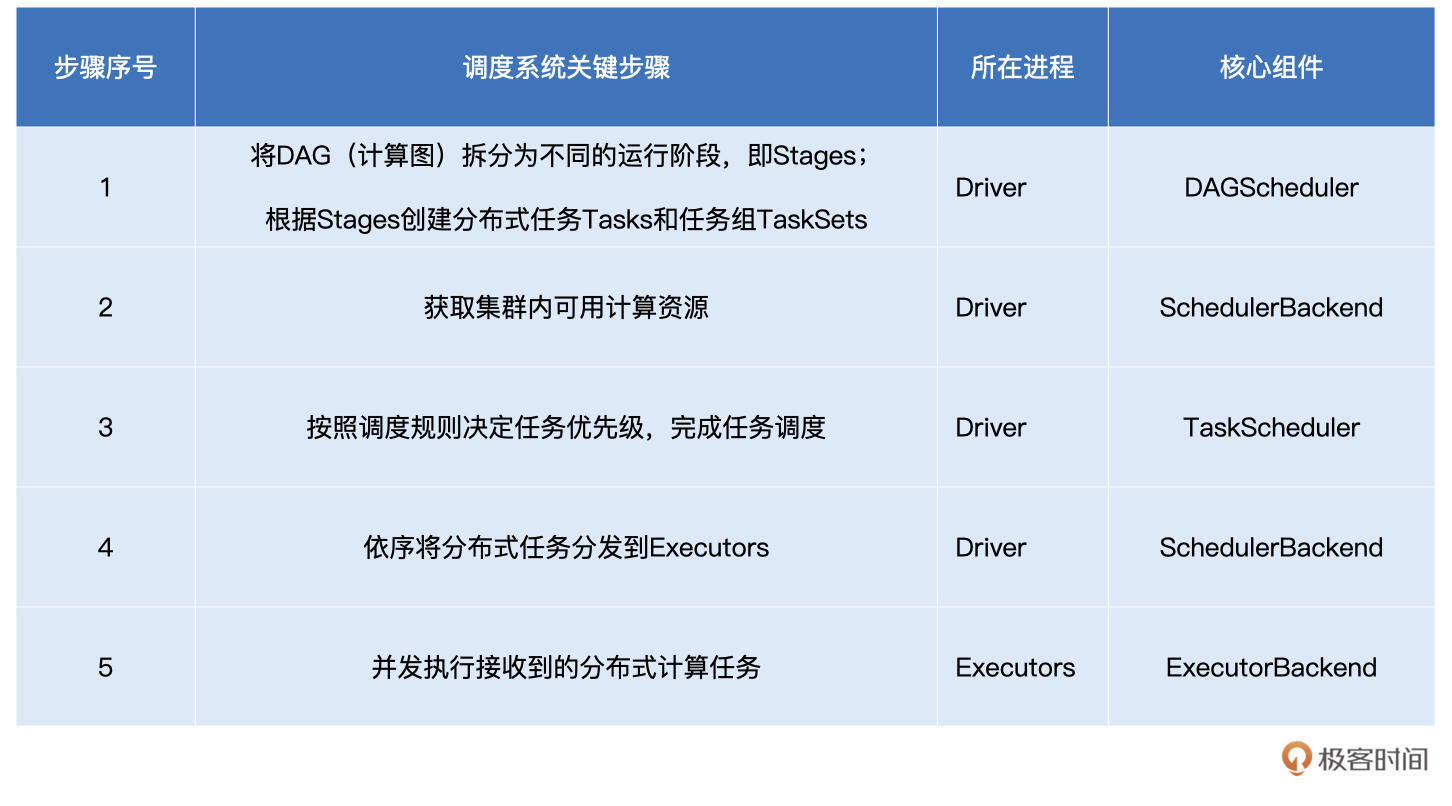
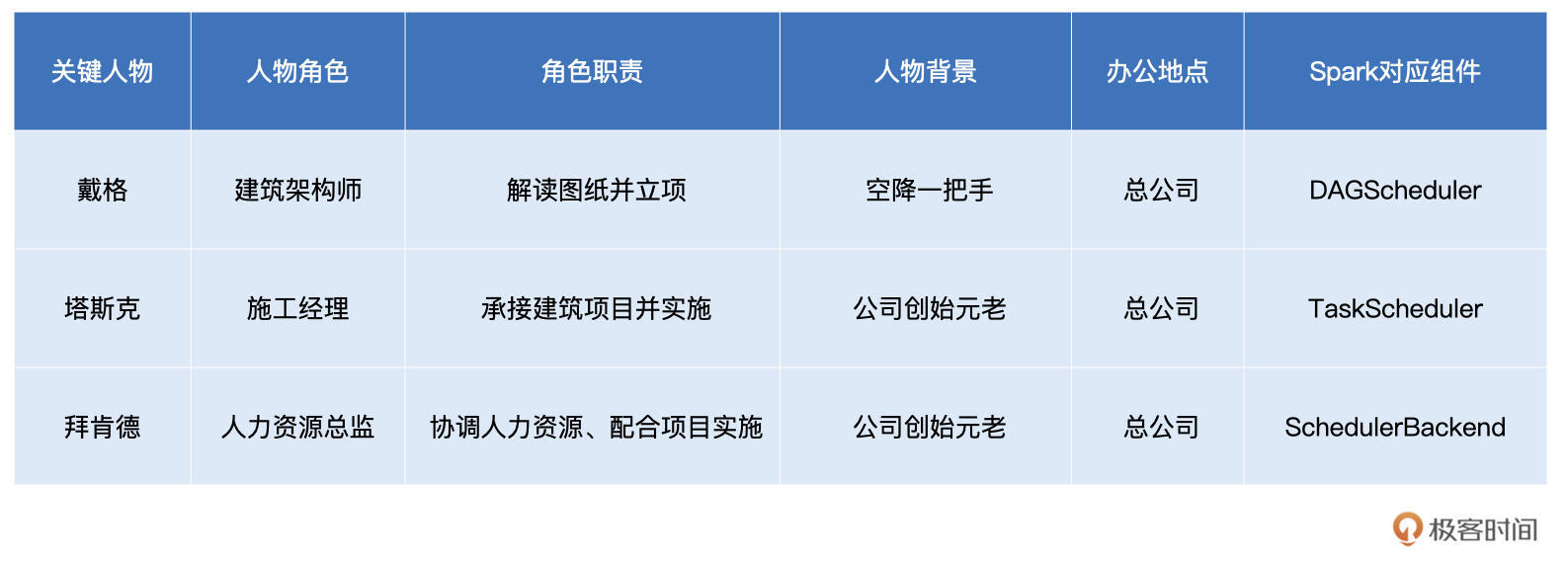
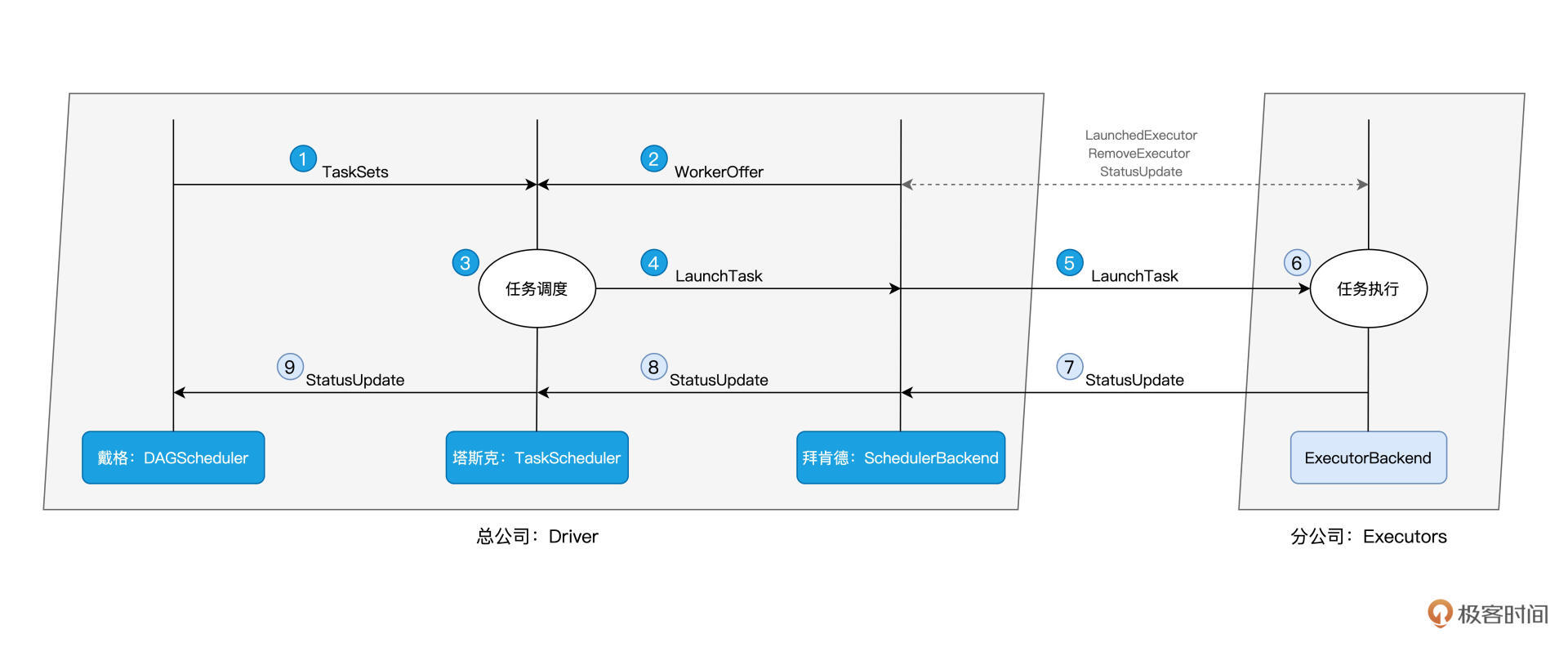
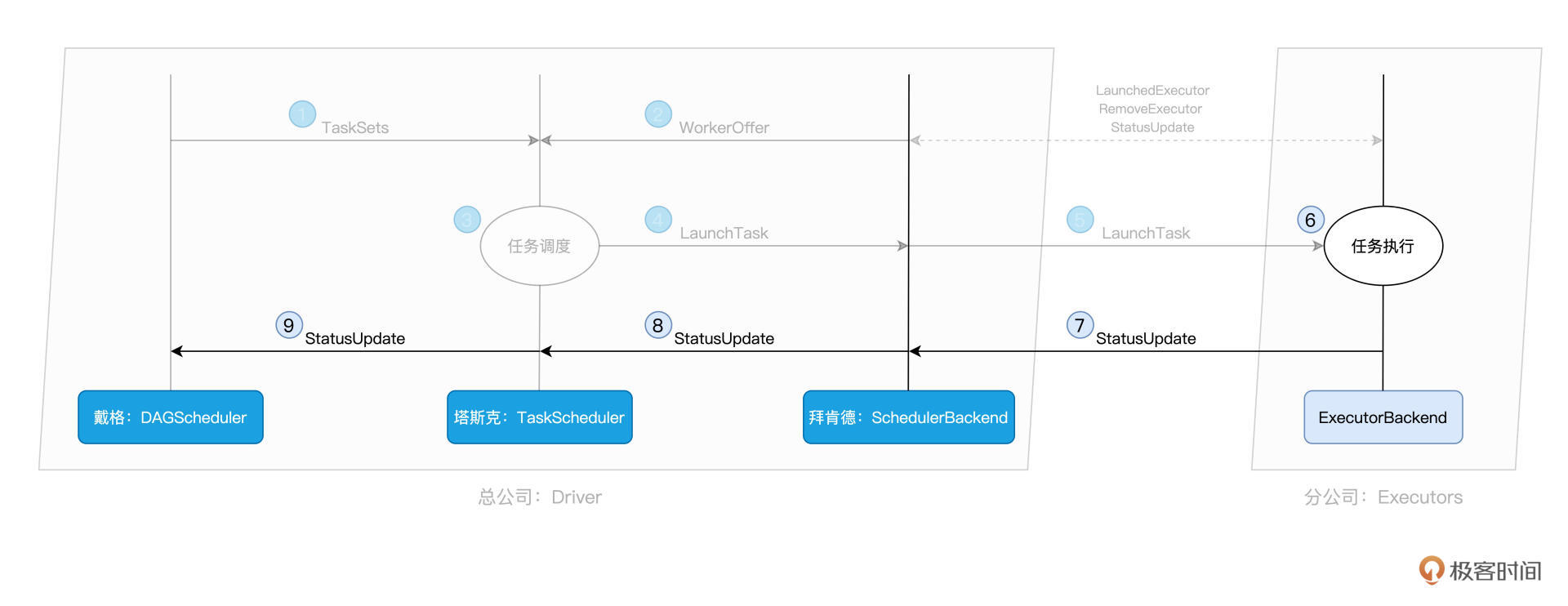
总架戴格:DAGScheduler
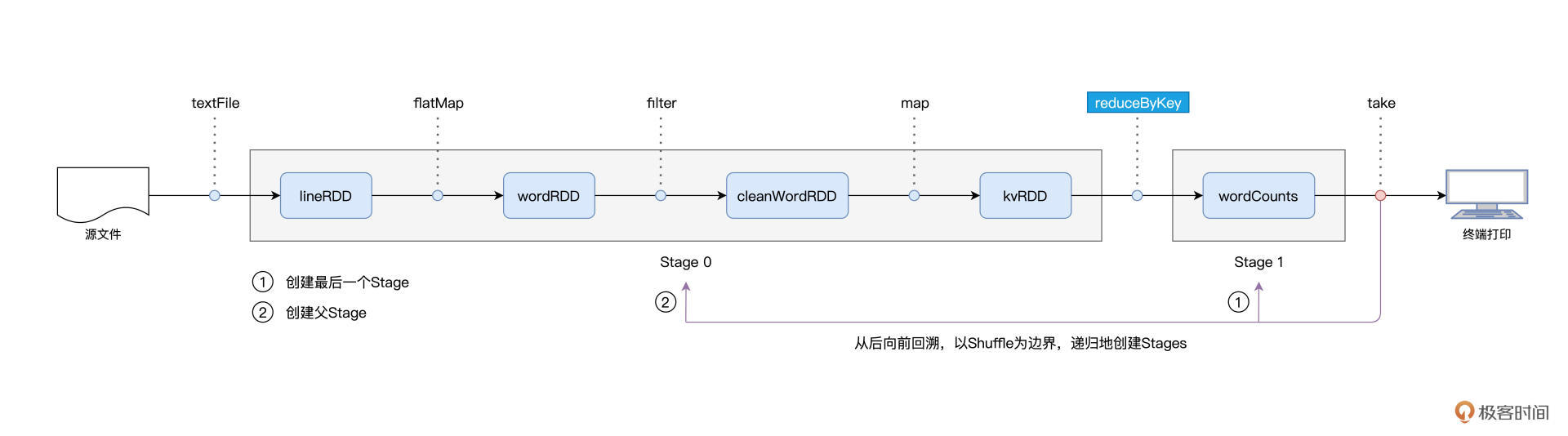
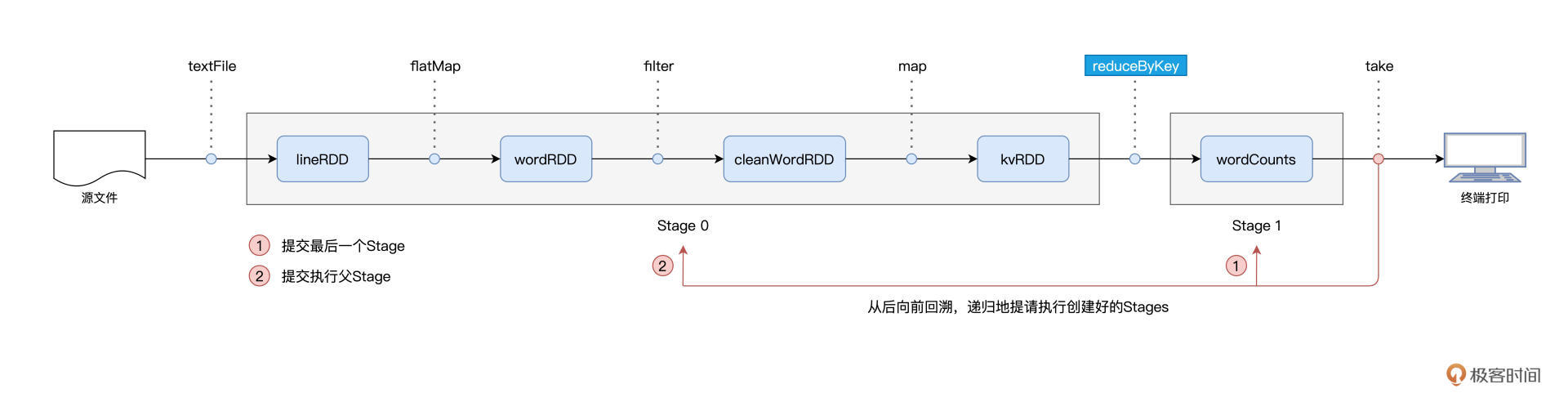

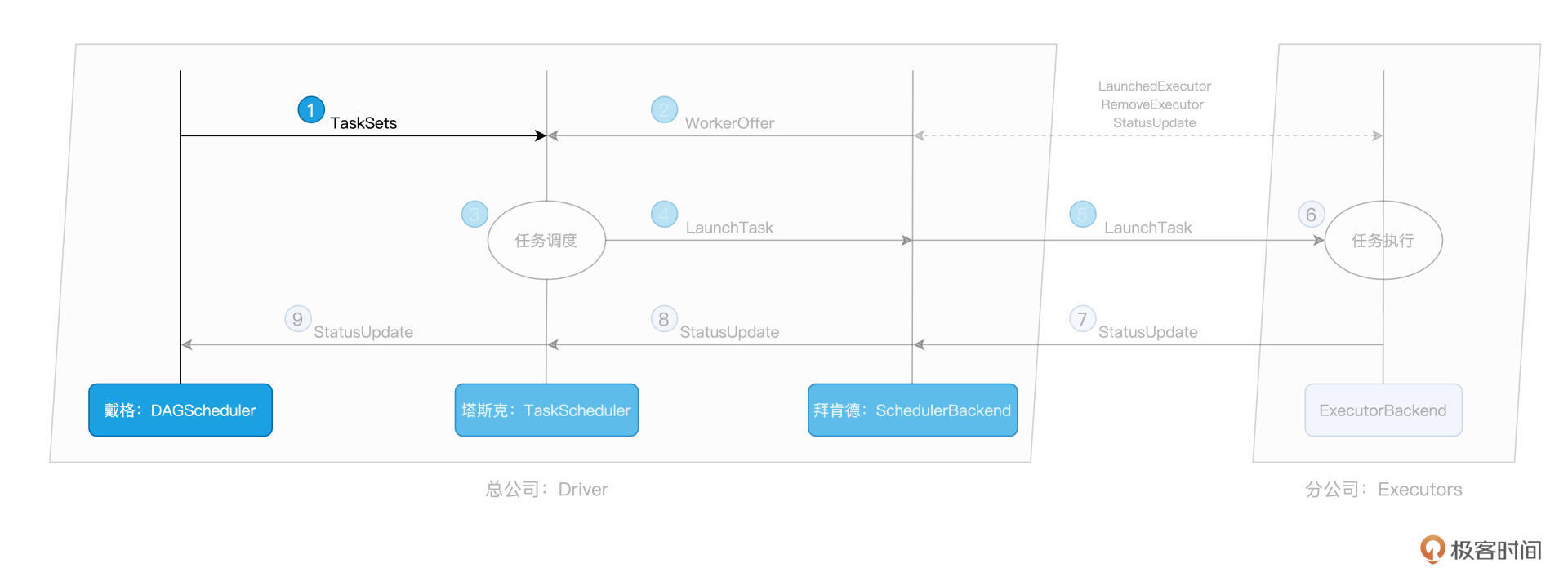
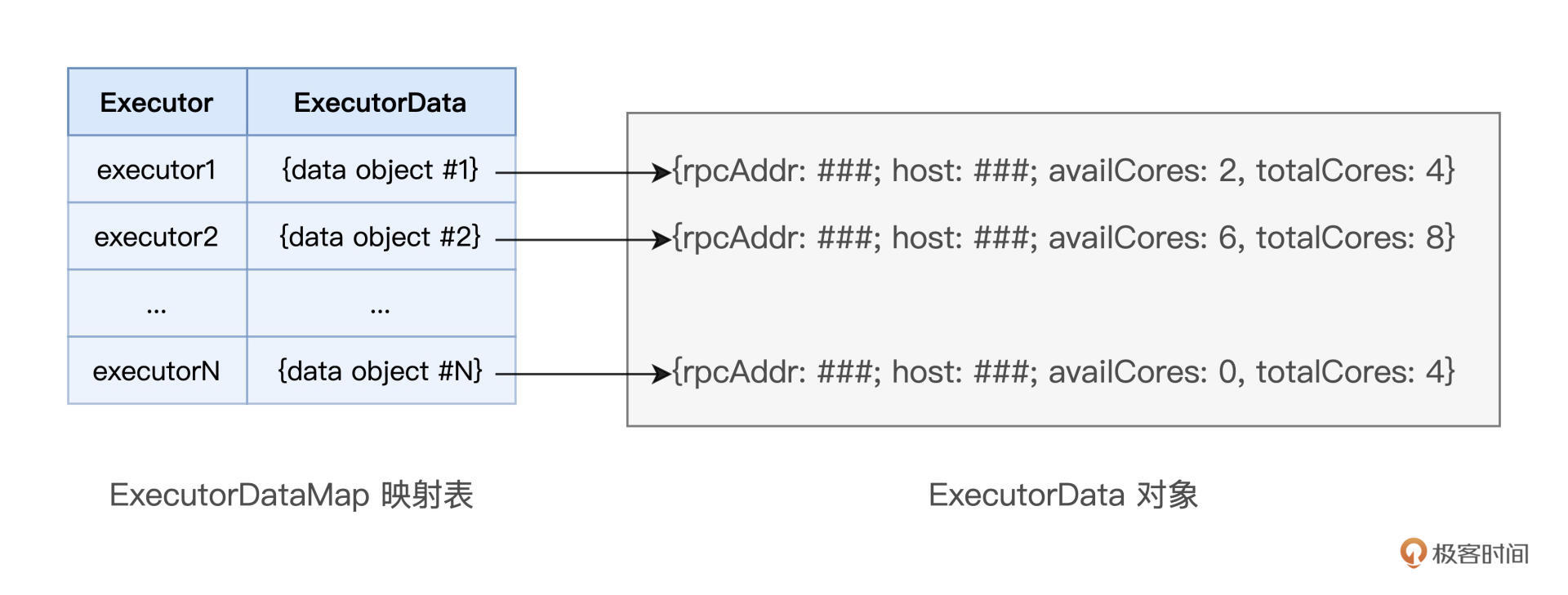
拜肯德:SchedulerBackend

塔斯克:TaskScheduler
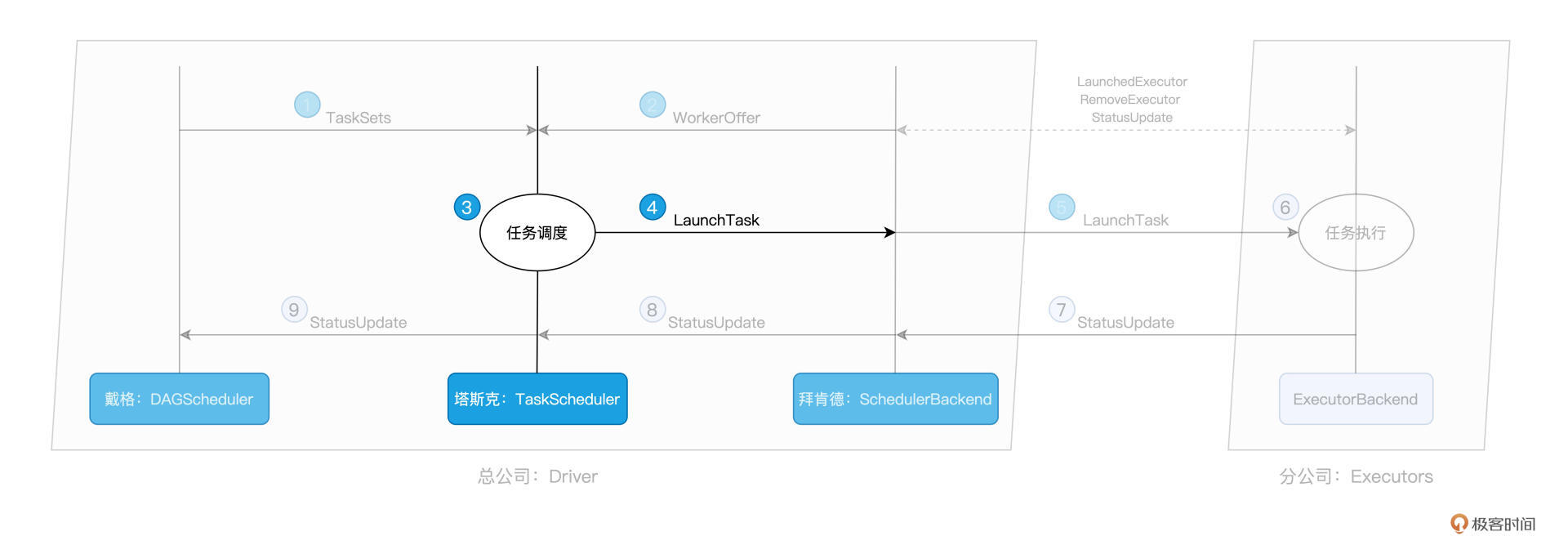
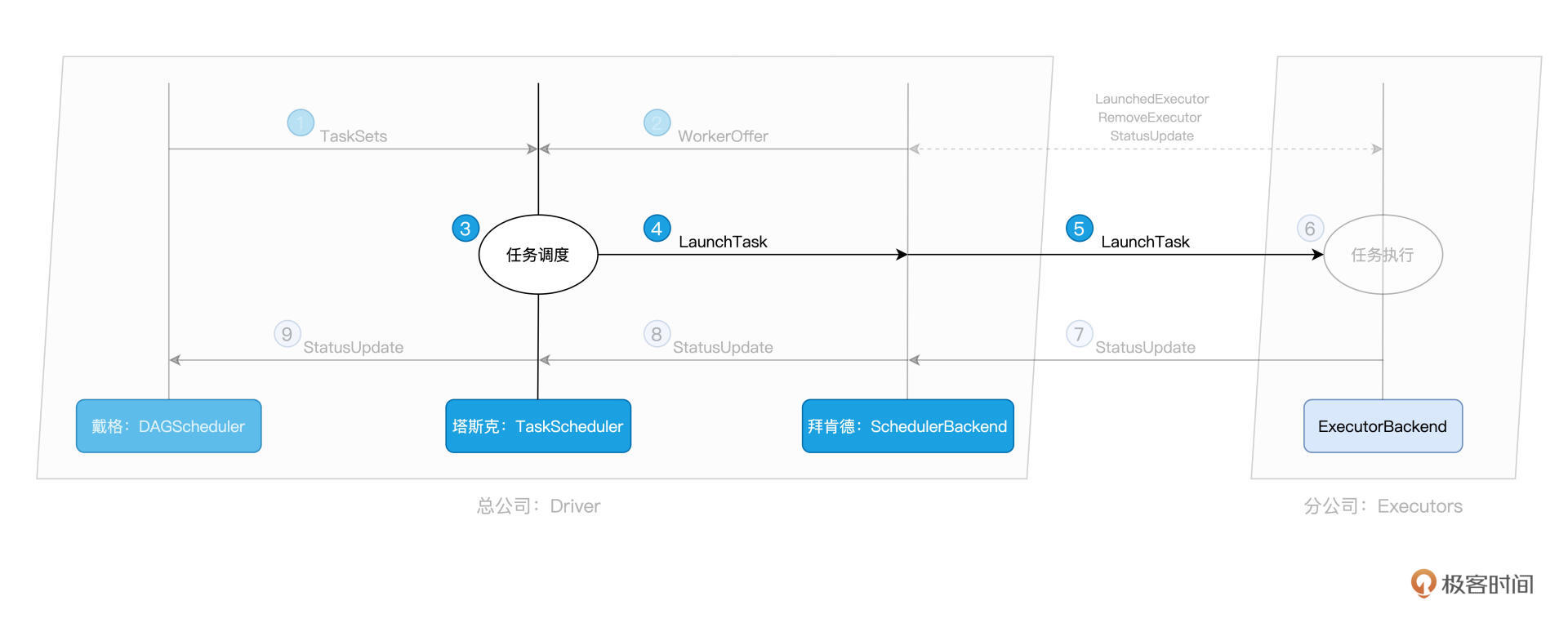
付诸执行:ExecutorBackend
重点回顾
每课一练
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

本文以“斯巴克建筑集团”为比喻,深入探讨了Spark调度系统的核心环节与关键步骤。通过比喻,将Driver比作总公司,Executors比作分公司,DAGScheduler、TaskScheduler和SchedulerBackend则分别扮演重要角色。DAGScheduler负责提交任务调度请求,TaskScheduler负责将任务派发给合适的Executor,而SchedulerBackend则与资源管理器强绑定,提供WorkerOffer并协调人力资源。文章生动有趣地介绍了Spark调度系统的核心概念和工作流程,为读者提供了一次深入了解分布式计算的机会。 文章通过生动的比喻,将Spark调度系统的核心环节比喻为斯巴克建筑集团的运作模式,将复杂的技术概念形象化,使读者更容易理解。通过对DAGScheduler、TaskScheduler和SchedulerBackend的角色和工作流程的详细解释,读者能够清晰地了解Spark调度系统的工作原理。此外,文章还介绍了任务调度的关键步骤,包括DAGScheduler的拆分阶段、SchedulerBackend的资源获取、TaskScheduler的任务调度规则等,为读者提供了全面的知识体系。 总的来说,本文通过生动的比喻和详细的技术解释,为读者呈现了Spark调度系统的工作原理和关键步骤,使读者能够快速了解分布式计算的核心概念,为开发高性能的Spark分布式应用打下坚实基础。
2021-09-2036人觉得很赞给文章提建议
《零基础入门 Spark》,新⼈⾸单¥59

全部留言(29)
- 最新
- 精选
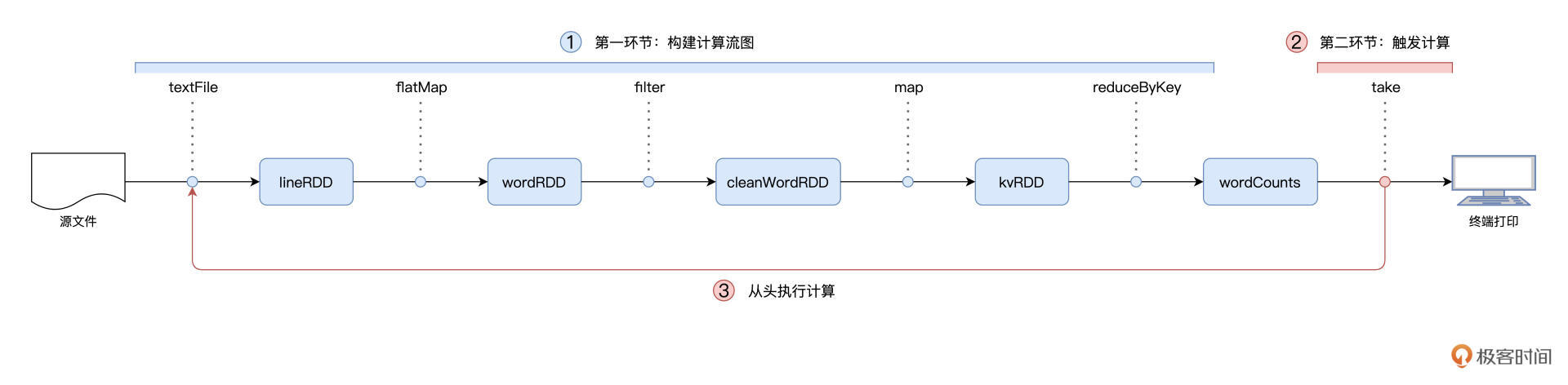
- Geek_2dfa9a置顶回答这个流程比较长哈,没有点开源源码阅读经验还真不好答哈,我这里都是自己的理解,如有异议欢迎讨论。 以老师的WordCount为例,首先stage分为两种:ResultStage,ShuffleMapStage。 ResultStage是啥呢就是处理Action动作的,一般也就是最后一个Stage(当然一个driver里也可能有多个Action,所以ResultStage也可能有多个, 这里简单点,WordCount例子里就是Stage1)。 ShuffleMapStage是啥呢,就是产生一个shuffle文件的stage,对应WordCount的Stage0。 为啥要分这么两类呢,因为你DAGScheduler就是根据是否shuffle倒推出来的stage嘛。这里多提一句,多个Job会共享Stage,这样就可以避免重复计算提升效率。 再根据老师讲的每个Stage里会根据RDD的partitions创建Task这段结合源码发现Task也有两种:ResultTask和ShuffleMapTask,对应的是Stage的两种类型。 接下来分析下DAGScheduler怎么感知Task的执行状态,DAGScheduler内部有一个线程eventProcessLoop,线程使用了生产者消费者模式, 里面有一个LinkedBlockingDeque队列,生产者TaskSetManager(可以忽略,理解为一个线程即可)发送给DAGScheduler的各种Task的event, 消费者eventProcessLoop把event取出来然后委托给DAGScheduler处理,其中对应Task完成的逻辑在方法handleTaskCompletion(event: CompletionEvent)中。既然问的是怎么知道当前Stage已经运行完成,可以运行下一个Stage,那当前Stage肯定不是ResultStage, 因此在handleTaskCompletion找到处理ShuffleMapTask的event的逻辑,具体逻辑为:先找到executor的ID标志execId, 校验execId是否为下发的Executor(以防伪造的event)然后标记ShuffleMapTask的结果可用,然后检查当前ShuffleMapStage是否还有没处理的Task, 如果没有的话说明该Stage完成,最后submitWaitingChildStages提交等待中的后续Stage。 这里使用的eventProcessLoop生产者消费者模式比较巧妙,生产者可能有多个线程(没进一步确认,有可能是1/n个),但是消费者是单线程的, 生产者也不直接修改DAGScheduler内部的成员,只通过丢event给线程安全的LinkedBlockingDeque,这样就保证了没有数据竞争。 最后,老师讲的非常清楚,看了这门课后我买了老师的另一门Spark性能调优,在这里感谢老师。最后提一句,您配图里的字能调大点嘛,字太小了。
作者回复: 满分💯 + 置顶🔝,👍👍👍 分析得相当到位/深入!赞赞赞! 感谢老弟认可~ 没问题,后续把字体调大些~
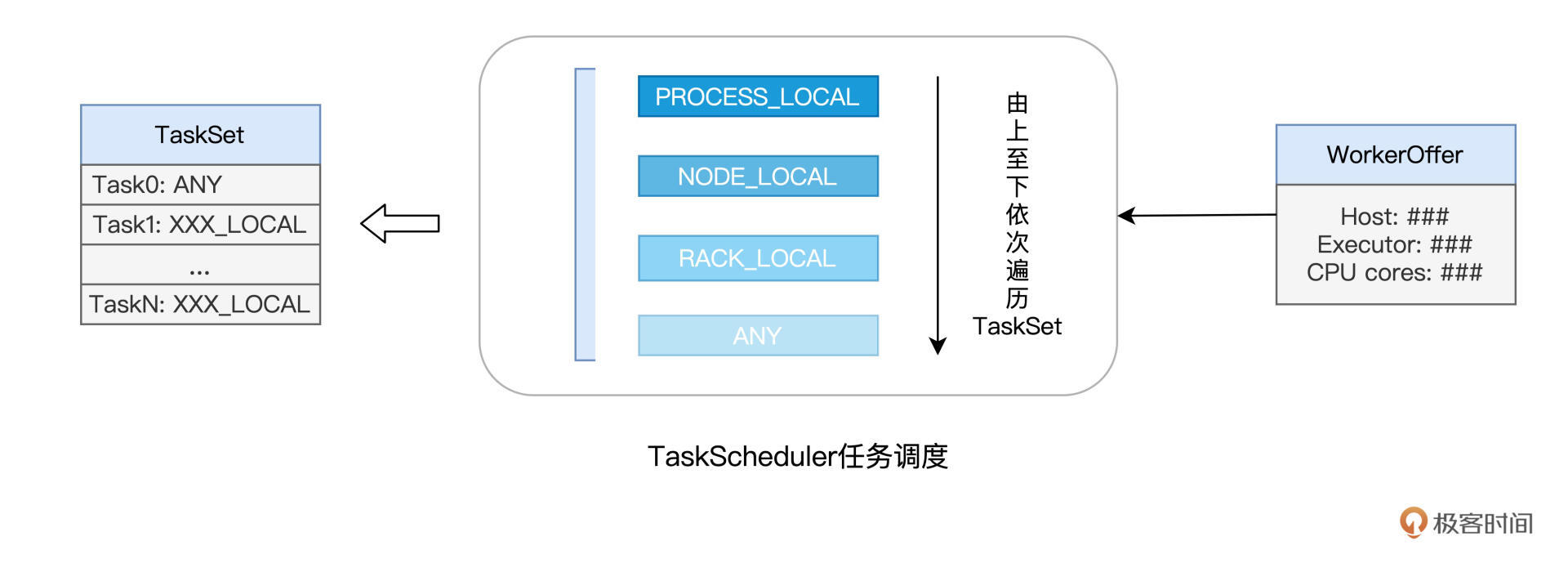
2021-09-20438  welldo老师, 根据“当 TaskScheduler 需要调度 Task0 这个任务时,根据 Task0 的 locs 属性,它就知道。。。”这段话, 和你回复unknown同学的“仅仅知道数据在某个机架内(一个机架包含多台机器)”这段话, 结合起来,意思是不是: task对于它要处理的数据在哪里, 有时候精确知道(在某个进程内或某个节点内); 有时候模糊知道(在某个机架内);有时候不知道(any), 并且标注在它的locs属性里, “精确知道的”task,就只挑选符合要求的offer; “模糊知道的”task,就挑选大致符合要求的offer; “不知道的”task,就随便选一个offer。 老师,请问我的理解对吗?
welldo老师, 根据“当 TaskScheduler 需要调度 Task0 这个任务时,根据 Task0 的 locs 属性,它就知道。。。”这段话, 和你回复unknown同学的“仅仅知道数据在某个机架内(一个机架包含多台机器)”这段话, 结合起来,意思是不是: task对于它要处理的数据在哪里, 有时候精确知道(在某个进程内或某个节点内); 有时候模糊知道(在某个机架内);有时候不知道(any), 并且标注在它的locs属性里, “精确知道的”task,就只挑选符合要求的offer; “模糊知道的”task,就挑选大致符合要求的offer; “不知道的”task,就随便选一个offer。 老师,请问我的理解对吗?作者回复: 老弟头像不错~ 回答你的问题:理解得简直太到位了!非常对!就是这个意思~
2021-10-2725- pythonbug老师好,TaskScheduler调度优先级那里是不是可以这样理解: for 优先级 <- PROCESS_LOCAL to ANY { for task <- task0 to taskn{ if task0.locs == workoffer 分配 else 跳过 } }
作者回复: 精辟!!!赞👍,逻辑上就是这个意思~
2021-11-134  Jordan·李威总公司和分公司的工作任务和人力资源分配调度的例子太匹配了。
Jordan·李威总公司和分公司的工作任务和人力资源分配调度的例子太匹配了。作者回复: 喜欢就好~
2021-09-204 艾利特-G> 2.SchedulerBackend 通过与 Executors 中的 ExecutorBackend 的交互来实时地获取集群中可用的计算资源,并将这些信息记录到 ExecutorDataMap 数据结构。 这一步中,假如数据是存放在HDFS中,那么SchedulerBackend通过读取HDFS的元数据就知道了某个task所需要的数据分片在哪个DataNode(YARN/Spark worker node)。 这个时候为了知道该DataNode的计算资源,不需要实际地启动一个executor,只需要向YARN NodeManager(或者别的资源调度框架中的worker daemon)询问一下就知道了吧?
艾利特-G> 2.SchedulerBackend 通过与 Executors 中的 ExecutorBackend 的交互来实时地获取集群中可用的计算资源,并将这些信息记录到 ExecutorDataMap 数据结构。 这一步中,假如数据是存放在HDFS中,那么SchedulerBackend通过读取HDFS的元数据就知道了某个task所需要的数据分片在哪个DataNode(YARN/Spark worker node)。 这个时候为了知道该DataNode的计算资源,不需要实际地启动一个executor,只需要向YARN NodeManager(或者别的资源调度框架中的worker daemon)询问一下就知道了吧?作者回复: 这里的关键,还是要区分“资源调度”和“任务调度”,这两个是相对独立的系统。资源调度与Yarn,只关心CPU、内存资源是否充足,从而决定是否在NodeMgr中启动Executors;而数据分片位置,Task倾向性,这些是任务调度系统关系的内容。两个系统相互独立,保持松耦合的关系,是比较好的设计。如果在资源调度阶段,就引入与任务相关的信息,比如分片位置,这样的系统设计会很复杂、很难维护,MapReduce V1实际上就是这样的设计,后来在V2的时候,就把YARN单独拆出来了。
2022-02-073 赌神很低调老师好,文中说task任务分发通过数据本地性找到合适的executor,想了解executor进程是根据数据所在的节点创建的吗?否则不是很大几率都找不到合适的executor?
赌神很低调老师好,文中说task任务分发通过数据本地性找到合适的executor,想了解executor进程是根据数据所在的节点创建的吗?否则不是很大几率都找不到合适的executor?作者回复: 好问题,是这样的,资源调度和任务调度是分开的。 资源调度主要看哪些节点可以启动executors,是否能满足executors所需的cpu数量要求,这个时候,不会考虑任务、数据本地性这些因素。 资源调度完成之后,在任务调度阶段,spark负责计算每个任务的本地性,效果就是task明确知道自己应该调度到哪个节点,甚至是哪个executors。最后scheduler Backend会把task代码,分发到目标节点的目标executors,完成任务调度,实现数据不动代码动。 所以,二者是独立的,不能混为一谈哈~
2022-01-223 D.C一个taskSet下的不同task,可以分配到同一个executors么?
D.C一个taskSet下的不同task,可以分配到同一个executors么?作者回复: 可以的~ 优先根据locality preference来, PROCESS_LOCAL -> NODE_LOCAL -> RACK_LOCAL,wait时间超时之后,就随机分发了,变成ANY
2021-11-053- 花生耿老师,我是spark零基础。这个例子中的一堆中文名字反而增加了理解的难度,我建议直接把里面的角色直接替换成真实的组件更容易理解,要不然还得一边看中文名字,一边跟那个组件对应。
作者回复: 抱歉老弟~ 多一些拟人、类比,主要是为了增加学习的趣味性,多一些生活化联想,很多复杂的概念,也会记得更牢靠一些~
2022-02-2822 - bian这章真的是将执行流程讲的棒极了
作者回复: 喜欢就好哈~
2021-10-222  加乘老师好,有个基础的问题,没太明白,就是文中说到“当我们调用 textFile API 从 HDFS 文件系统中读取源文件时,Spark 会根据 HDFS NameNode 当中记录的元数据......”时,数据和Executors应该不在一个物理机器上吧,那么Executors执行的时候,是到数据节点的机器上读取数据再进行处理吗? 后面又提到“数据不动,代码动”,感觉应该是把代码发到数据节点,然后在数据节点上进行计算处理。然后再返回给Executors执行结果,这样理解对吗?
加乘老师好,有个基础的问题,没太明白,就是文中说到“当我们调用 textFile API 从 HDFS 文件系统中读取源文件时,Spark 会根据 HDFS NameNode 当中记录的元数据......”时,数据和Executors应该不在一个物理机器上吧,那么Executors执行的时候,是到数据节点的机器上读取数据再进行处理吗? 后面又提到“数据不动,代码动”,感觉应该是把代码发到数据节点,然后在数据节点上进行计算处理。然后再返回给Executors执行结果,这样理解对吗?作者回复: 好问题,通常来说,Spark与HDFS都是部署在同一个集群,所以Executors和HDFS是分散在同一个集群。但是,Executors所需的数据分区,不见得是在同一个计算节点。 而这,就是调度系统的价值之一,把task代码,分发到数据分区所在的节点上的Executor,从而保证node_local的本地性级别。 而不是把task随意分发到任意资源充足的节点,然后再把对应的所需数据拉过来。 这个就是所谓的:数据不动代码动~
2021-09-2832

