

03 | RDD常用算子(一):RDD内部的数据转换

创建 RDD
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

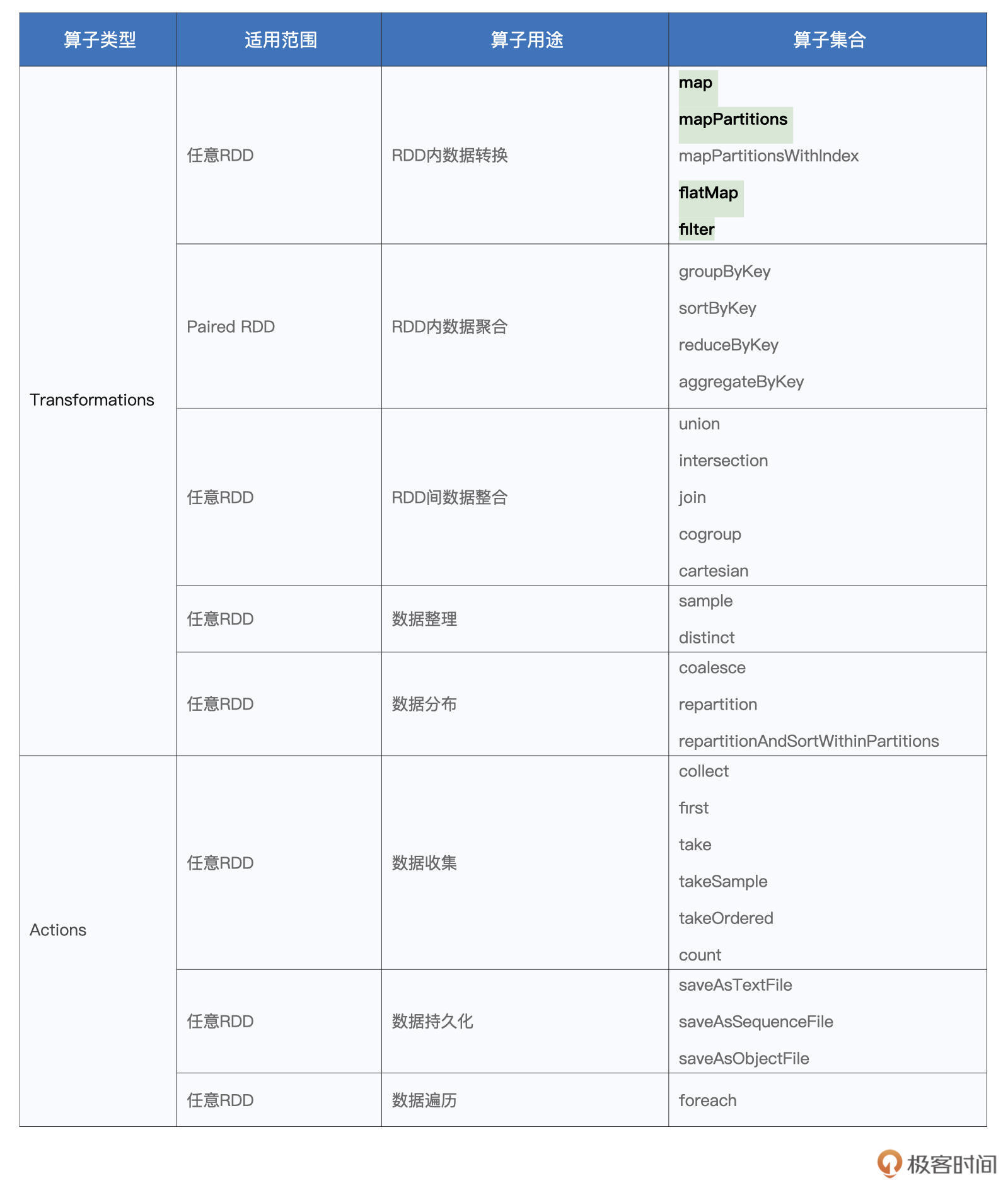
本文深入介绍了RDD常用算子中的数据转换部分,以厨房用具为比喻,强调了掌握RDD算子对于Spark应用开发的重要性。文章首先详细介绍了创建RDD的两种典型方式,然后重点讲解了map算子的用法和注意事项,并通过示例代码展示了其灵活性。作者指出了在某些计算场景下,map算子以元素为粒度进行数据转换可能影响执行效率的问题,并提到了mapPartitions和mapPartitionsWithIndex这对“孪生兄弟”算子,用来解决map算子粒度过细的问题。接着,文章介绍了flatMap算子的功能和使用方法,以及filter算子的过滤功能和判定函数的应用。通过实例和图示,深入浅出地解释了这些算子的使用场景和优化效果。整体而言,本文内容深入浅出,适合读者快速了解RDD常用算子中的数据转换部分,为Spark应用开发提供了重要参考。 文章通过生动的比喻和清晰的示例,深入介绍了RDD常用算子中的数据转换部分,强调了对于Spark应用开发者掌握这些算子的重要性。特别地,map算子、mapPartitions和mapPartitionsWithIndex被重点讲解,以及flatMap和filter算子的功能和使用方法也得到了详细阐述。通过本文,读者可以快速了解并掌握这些常用算子,为Spark应用开发提供了重要参考。
《零基础入门 Spark》,新⼈⾸单¥59

全部留言(23)
- 最新
- 精选

 qinsi不是很懂spark。mapPartitions()那里,光从代码上来看的话,在map()的闭包里可以访问到外面mapPartitions()闭包里的同一个md5实例,从而达到共享实例的效果。那么有没有可能在最外层创建一个全局的md5实例,这样就算只用map(),在闭包里访问的也是这同一个实例?这样会有什么问题吗?或者说在这种情况下mapPartitions()相比map()还有什么优势?
qinsi不是很懂spark。mapPartitions()那里,光从代码上来看的话,在map()的闭包里可以访问到外面mapPartitions()闭包里的同一个md5实例,从而达到共享实例的效果。那么有没有可能在最外层创建一个全局的md5实例,这样就算只用map(),在闭包里访问的也是这同一个实例?这样会有什么问题吗?或者说在这种情况下mapPartitions()相比map()还有什么优势?作者回复: 非常好的问题~ 先赞一个 👍 先说结论,你说的没错,通过在Driver端创建全局变量,然后在map中进行引用,也可以达到mapPartitions同样的效果。原理就是你说的函数闭包,其实本质上,它就是个对象,包含了外部数据结构的函数对象。 但是,需要注意的是,通过这种方式创建的闭包,一定要保证Driver端创建的全局变量是可以序列化的,也就是实现了Serializable接口。只有满足这个前提,Spark才能在这个闭包之上创建分布式任务,否则会报“Task not serializable”错误。 这个错误其实很好理解,要把Driver创建的对象带到Executors,这个对象一定是要可序列化的才行。不过遗憾的是,很多共享对象,比如咱们本讲的MD5,都没有实现Serializable接口,所以Driver端创建的MD5实例,Spark“带不动”(没法从Driver带到Executors),这一点你不妨动手试一试~ 不过这个点提得非常好,对于那些自定义的Class,我们可以让它实现Serializable接口,从而可以轻松地在Driver创建Spark可以“带的动”的全局变量。 说到这里,我追问老弟一句:在Driver创建MD5实例,map中直接引用,Spark会报“Task not Serializable”;那为什么在mapPartitions里面创建MD5实例,map引用这个对象,Spark却没有报“Task not Serializable”错误呢? 老弟不妨再想一想,咱们评论区继续讨论~
2021-09-161141 Unknown element老师您回答一楼的问题时提到的序列化意思是不是对象在不同节点间传输的时候只能序列化为字符串传输?如果是的话那我觉得 在mapPartitions里面创建MD5实例,map引用这个对象,Spark却没有报“Task not Serializable”错误 是因为driver把这段代码分发到了各个executor,而创建对象这个工作是由executor完成的,所以不会报错?
Unknown element老师您回答一楼的问题时提到的序列化意思是不是对象在不同节点间传输的时候只能序列化为字符串传输?如果是的话那我觉得 在mapPartitions里面创建MD5实例,map引用这个对象,Spark却没有报“Task not Serializable”错误 是因为driver把这段代码分发到了各个executor,而创建对象这个工作是由executor完成的,所以不会报错?作者回复: Perfect,正解!就是这么回事~
2021-09-2419- Geek_eb2d3d老师,我在 map 里面使用 SparkContext 或 SparkSession 创建新的 RDD,这样是可以的么?
作者回复: 不可以,严禁这么做。 RDD里面,禁止嵌套定义新的RDD,这个是Spark分布式开发的大忌。 Spark的开发模式、或者是开发规范,是利用transformation,来完成分布式数据集之间的转换,从而达到处理数据的目的~ RDD内嵌套RDD,这种属于单机思维哈,必须要跳出来~
2021-09-288  Alvin-LPython版,虽然能跑,但是不知道对不对: #哈希值计数 ``` from hashlib import md5 from pyspark import SparkContext def f(partition): m = md5() for word in partition: m.update(word.encode("utf8")) yield m.hexdigest() lineRDD = SparkContext().textFile("./wikiOfSpark.txt") kvRDD = ( lineRDD.flatMap(lambda line: line.split(" ")) .filter(lambda word: word != "") .mapPartitions(f) .map(lambda word: (word, 1)) ) kvRDD.foreach(print) ``` #相邻+过滤特殊字符 ``` from pyspark import SparkContext # 定义特殊字符列表 special_char_list = ["&", "|", "#", "^", "@"] # 定义判定函数f def f(s): words = s.split("-") b1 = words[0] in special_char_list b2 = words[1] in special_char_list return (not b1) and (not b2) # 定义拼接函数word_pair def word_pair(line): words = line.split(" ") for i in range(len(words) - 1): yield words[i] + "-" + words[i + 1] lineRDD = SparkContext().textFile("./wikiOfSpark.txt") cleanedPairRDD = lineRDD.flatMap(word_pair).filter(f) cleanedPairRDD.foreach(print) ```
Alvin-LPython版,虽然能跑,但是不知道对不对: #哈希值计数 ``` from hashlib import md5 from pyspark import SparkContext def f(partition): m = md5() for word in partition: m.update(word.encode("utf8")) yield m.hexdigest() lineRDD = SparkContext().textFile("./wikiOfSpark.txt") kvRDD = ( lineRDD.flatMap(lambda line: line.split(" ")) .filter(lambda word: word != "") .mapPartitions(f) .map(lambda word: (word, 1)) ) kvRDD.foreach(print) ``` #相邻+过滤特殊字符 ``` from pyspark import SparkContext # 定义特殊字符列表 special_char_list = ["&", "|", "#", "^", "@"] # 定义判定函数f def f(s): words = s.split("-") b1 = words[0] in special_char_list b2 = words[1] in special_char_list return (not b1) and (not b2) # 定义拼接函数word_pair def word_pair(line): words = line.split(" ") for i in range(len(words) - 1): yield words[i] + "-" + words[i + 1] lineRDD = SparkContext().textFile("./wikiOfSpark.txt") cleanedPairRDD = lineRDD.flatMap(word_pair).filter(f) cleanedPairRDD.foreach(print) ```作者回复: 两份代码都是满分💯,👍 感谢老弟分享、贡献Python代码,后面我们一起把它整理到GitHub里面去~ 感谢!!!
2021-09-2137- Geek_a30533对scala的函数定义格式不是很清楚,那边绕了好几次,有一个小疑问,在flatMap里的匿名函数f line => { val words: Array[String] = line.split(" ") for (i <- 0 until words.length - 1) yield words(i) + "-" + words(i+1) } 只定义了形参是line,那出参是整个花括号么?主要是没有return,让我一下迷了,难道是最后一个是Array[String]所以返回值就是这个?不用声明吗?
作者回复: 对的~ 确实,Scala的语法比较简洁(偷懒),return不是必须的,如果函数体没有return,那么最后一行代码的输出,就是整个函数的返回值~ 具体到这个匿名函数,它的返回结果就是你说的Array[String],后续flatMap再把这里的Array展平
2021-10-144 - DMY数据做map映射是以元素为粒度,执行f函数; 这里业务场景中,f函数需要调用rpc,每个数据调一次rpc+数据量大就会非常耗时。 所以想把一组数据打包成一个list减少rpc调用,来提高效率,这里要怎么处理呢
作者回复: 可以参考下面的方式来实现: import scala.collection.mutable.ArrayBuffer def f(iter: Iterator[Int]) : Iterator[Int] = { val dataSeq: ArrayBuffer[Int] = new ArrayBuffer() while (iter.hasNext) { val cur = iter.next; dataSeq += cur } // 你的处理逻辑 val res = yourRPCFunction(dataSeq) // 以迭代器的形式,返回计算结果 res.iterator } // 处理RDD的时候,用mapPartitions调用f即可 data.mapPartitions(f)
2021-10-2033  大叮当同问老师,AIK问的问题,什么时候用小括号什么时候用花括号啊,感觉scala实在有点过于灵活
大叮当同问老师,AIK问的问题,什么时候用小括号什么时候用花括号啊,感觉scala实在有点过于灵活作者回复: Scala语法确实比较灵活,一般来说,简单表达式用(),复杂表达式用{}。 比如,简单函数体:(x => x + 1)、(_ + 1),等等; 复杂函数体:{case x: String => “一大堆关于x的转换” }
2021-09-1643 木之上老师,在学习这些算子的时候,像map,flatmap是否可以类比JAVA8的lambda表达式+stream流去学习
木之上老师,在学习这些算子的时候,像map,flatmap是否可以类比JAVA8的lambda表达式+stream流去学习作者回复: 是的,没有问题~ JAVA8开始支持函数式编程,它的stream本质上和咱们这里的算子是一样的~
2022-02-232 孙浩有疑问,吴老师,PariedRDD中的(K,V),1.对应的数据类型应该是scala中的元组吧?2.reduceByKey为啥不支持元素是map类型?或者如果我存在一个RDD[Map[String,Int]],我想做reduceByKey操作,应该怎么实现?
孙浩有疑问,吴老师,PariedRDD中的(K,V),1.对应的数据类型应该是scala中的元组吧?2.reduceByKey为啥不支持元素是map类型?或者如果我存在一个RDD[Map[String,Int]],我想做reduceByKey操作,应该怎么实现?作者回复: 好问题, 1)(K,V)可以理解成是元组,这个没有问题 2)关于reduceByKey为啥不支持RDD[Map[String,Int]],这个其实老弟需要充分理解PairRDD,就RDD[Map[String,Int]]这种类型来说,本质上,他其实是RDD[KeyType],而不是RDD[(KeyType,ValueType)]。也就是说,RDD[Map[String,Int]]不是PairRDD,所以不仅reduceByKey不支持,其他*ByKey类操作也不支持。如果把它变换一下,比如RDD[(String,Map[String,Int])],这样是可以的,因为这个类型属于PairRDD,KeyType是String,而ValueType是Map[String,Int]~
2021-11-052- Geek_390836参考map和mapPartitions,为什么mapPartitions中的map,是对record进行getbytes而不是word.getbytes操作,刚学spark,求老师解答
作者回复: 好问题~ 你说的对,这里笔误了,已经让编辑帮忙改成了“word.getbytes”哈~ 感谢纠正~
2021-09-162

