

25 | 特征工程(下):有哪些常用的特征处理函数?

特征工程
离散化:Bucketizer
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

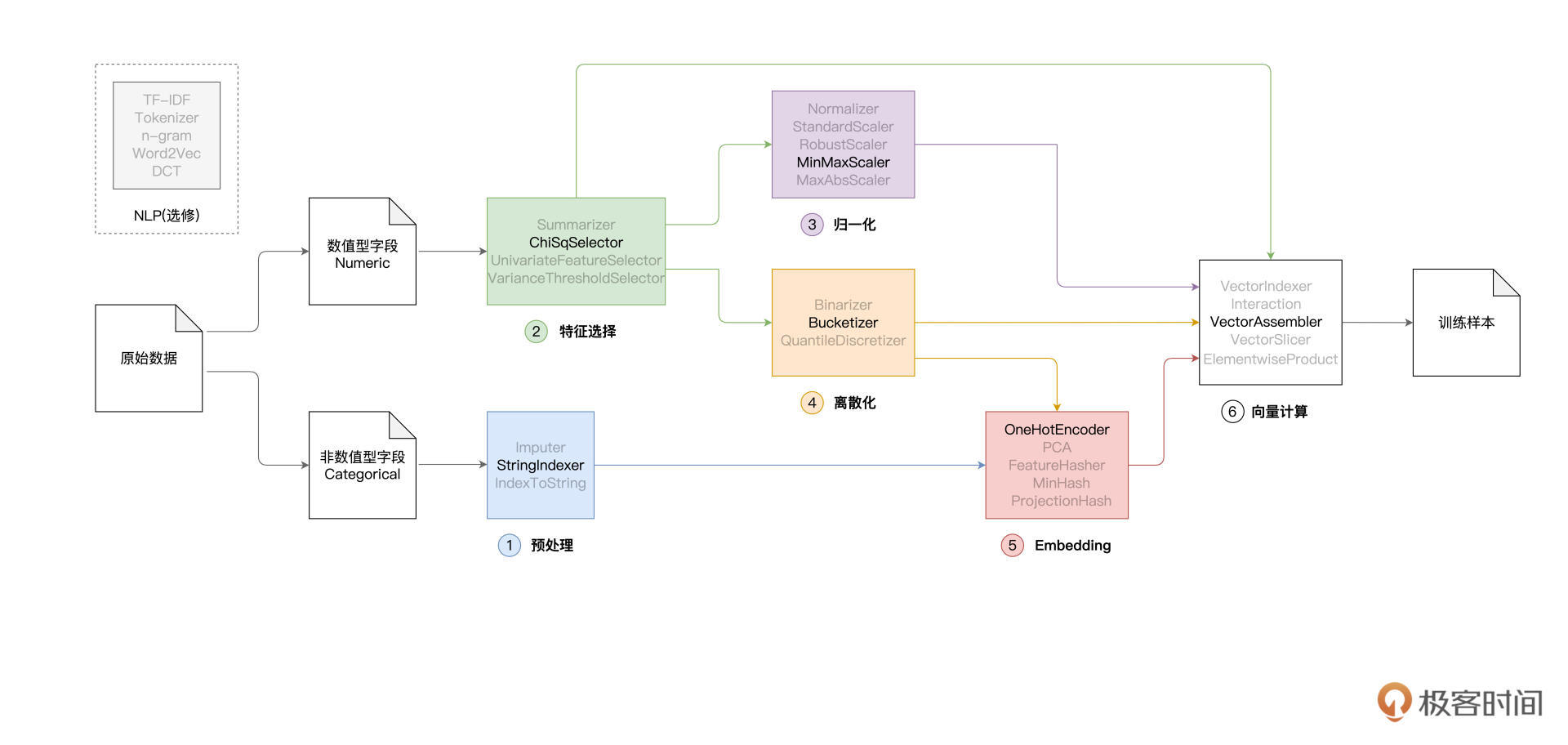
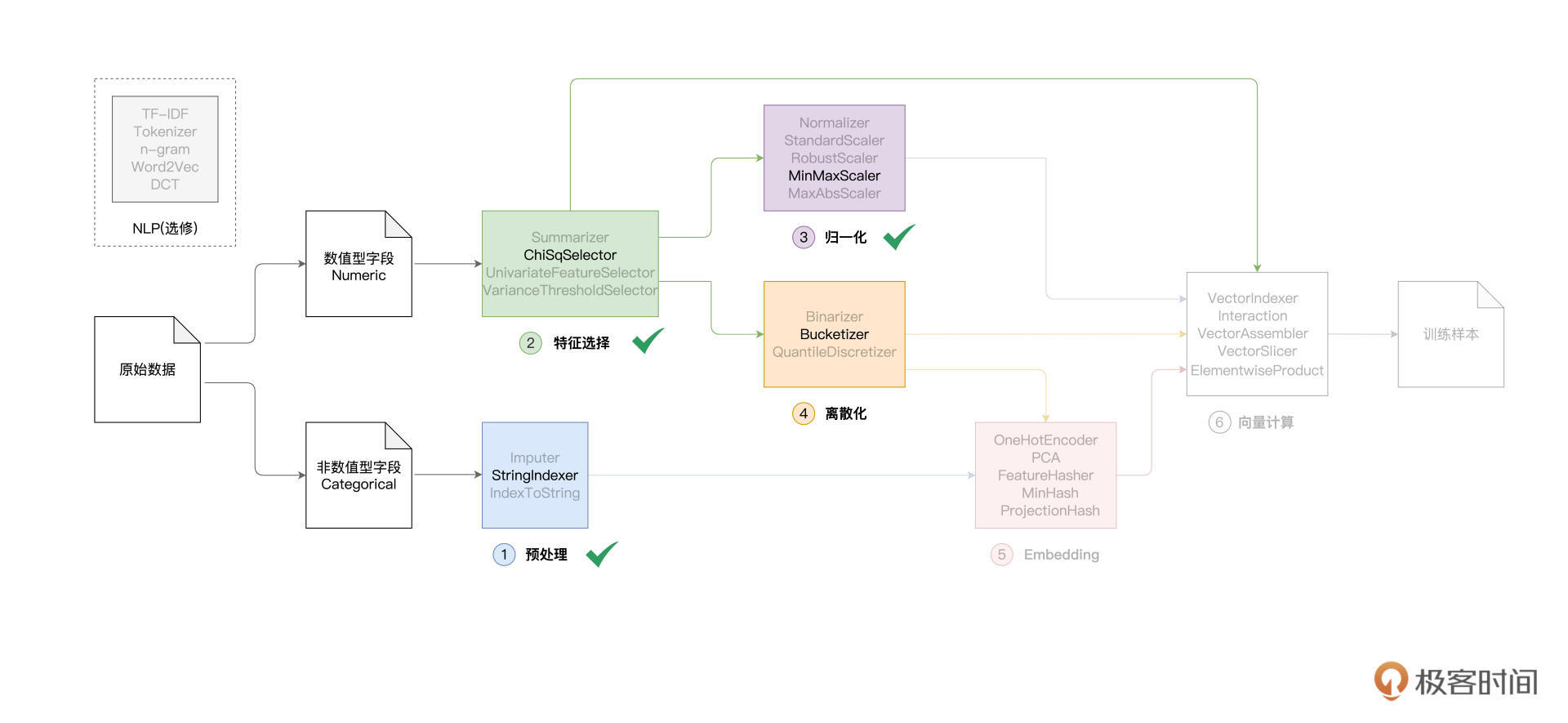
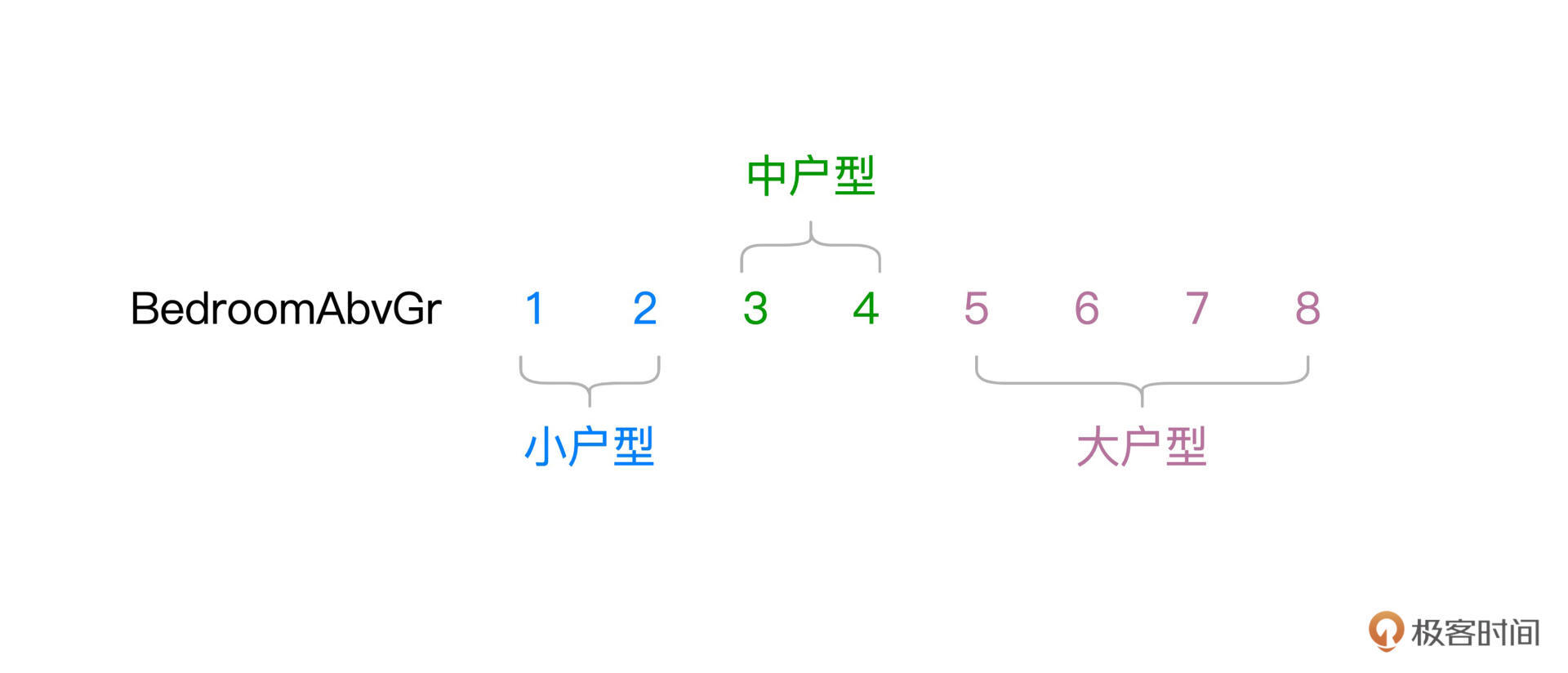
本文深入介绍了特征工程中的离散化处理函数及其在Spark MLlib框架中的应用。通过详细讲解Bucketizer函数的使用方法,阐述了离散化处理对提升特征数据区分度与内聚性的重要性。此外,文章还涵盖了Embedding方法和向量计算在特征工程中的应用,并通过代码示例和数据对比展示了离散化处理的实际操作及效果。值得一提的是,文章还提到了Spark MLlib框架中的Embedding方法OneHotEncoder的具体用法,以及向量计算在特征工程中的重要性。总的来说,本文内容深入浅出,适合技术人员快速了解特征工程中离散化处理的方法和应用。文章内容涵盖了特征工程的关键环节,为读者提供了全面的技术指导。文章还通过对比不同特征处理方法对应的模型效果,强调了特征工程对模型性能提升的重要性。整体而言,本文对特征工程中的关键概念和方法进行了全面而深入的介绍,为读者提供了宝贵的学习资源。
《零基础入门 Spark》,新⼈⾸单¥59

全部留言(3)
- 最新
- 精选
- Geek_d4ccac老师好!我印象中如果优化用到了梯度下降(比如说linear regression)那一定要做归一化,但这一节里面最后的model里把特征选择后的top20(没归一化)都放到了特征向量里,这样不会使优化不稳定么, 实际工作中是不是还是要尽量都归一化或者离散化呢?还有一个问题就是如果归一化和离散化包含了特征选择剔除的原始特征,这样会不会引入额外的noise呢,换句话说,归一化和离散化是不是要基于特征选择之上呢?谢谢!
作者回复: 好问题,其实坦白说,这样的问题,没有唯一的答案,或者说,就没有标准答案。特征工程也好,模型训练也罢,其实都是为模型效果服务的。而模型效果,其实很多时候并不取决于单一因素,往往是多种因素的叠加。咱们的入门篇,其实更多地,是给大家介绍,Spark MLlib子框架,都能提供哪些能力,允许开发者自由地选择、搭配。 回答你的问题,至于先归一化、再特征选择,还是先特征选择、再归一化,我更倾向于后者,就是先特征选择,然后再考虑归一化、离散化。当然,其实这并不绝对,很多时候,离散化与否,决定了特征本身的区分度,也许离散化之前,特征不会入选,但离散化之后,特征因为区分度的变化,可以入选。 机器学习本身,更偏向于实践科学,我们往往会有一些大面上的理论指导或者说方向,然后以效果为导向去做特征工程、模型调优。所以说,还是那句话,关于特征工程中的顺序问题,我觉得没有标准答案。咱们课程中按顺序介绍,其实仅仅是方便大家在逻辑上理解特征工程的不同环节,不同环节通常情况下确实会有先后之分,但是并不绝对,可能我在原文补充上这句话,更好一些~
2021-11-0823  千里马老师好,我想问下,中间的“特征选择”、“归一化”、“离散化”、“Embedding”是不是都可以根据实际情况选择性进行,但最后一步“向量计算”是必须进行的?
千里马老师好,我想问下,中间的“特征选择”、“归一化”、“离散化”、“Embedding”是不是都可以根据实际情况选择性进行,但最后一步“向量计算”是必须进行的?作者回复: 没错~ 老弟概括的极为精辟,就是这么回事!向量计算是必须的,因为模型只能消费这样的数据。而至于特征工程中的各个环节,如你提到的“特征选择”、“归一化”、“离散化”、“Embedding”,实际上都是结合实践与效果有选择地进行取舍
2021-11-101- AlexoheEncoder 对象只有 transformSchema 方法,没有transform(engineeringData)这个方法。。。。2022-12-30归属地:广东2

