

27 | 模型训练(中):回归、分类和聚类算法详解

房屋预测场景
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

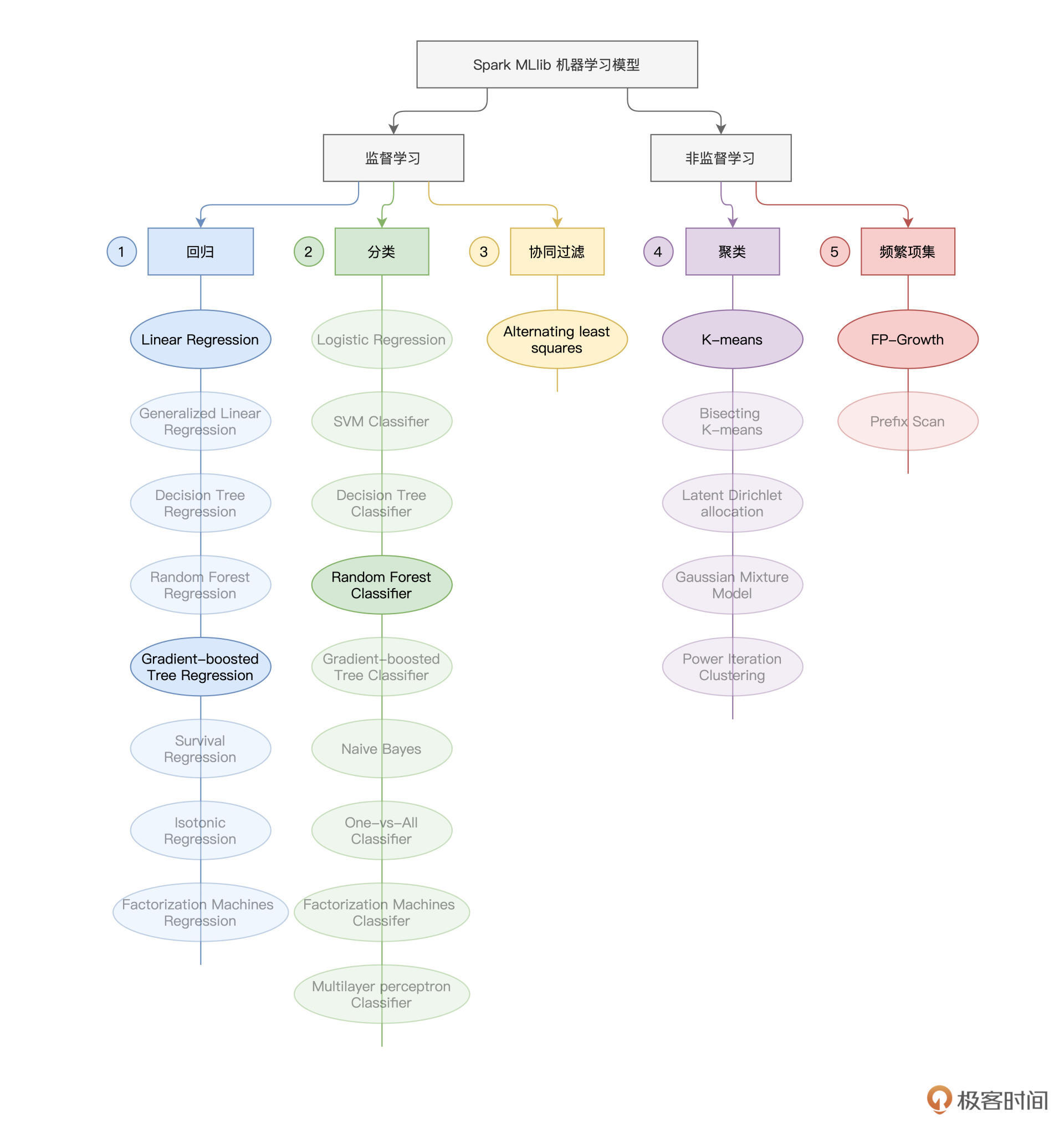
本文介绍了在Spark MLlib框架下,如何应用回归、分类和聚类算法到实际场景中。作者以房屋预测为例,分别讨论了房价预测、房屋分类和房屋聚类三个实例。在房价预测中,作者介绍了使用GBDT算法拟合房价的过程,特别强调了VectorIndexer的作用和GBDT模型的参数设置。在房屋分类中,作者将房屋质量作为标签,使用RandomForestClassifier进行模型训练,并介绍了模型效果的验证。在房屋聚类中,作者介绍了K-means算法的基本原理和模型效果的评估。整体而言,本文通过具体的代码实现,帮助读者了解了在Spark MLlib框架下应用回归、分类和聚类算法的方法和技巧。读者可以从中学习到GBTRegressor和RandomForestClassifier的一般用法,以及K-means算法的基本原理和应用。
《零基础入门 Spark》,新⼈⾸单¥59

全部留言(4)
- 最新
- 精选
- pythonbug老师好,房价预测那个例子,我用GBDT试了一下,结果发现比咱们一开始入门那个例子计算出来的rmse还要大。。没有明显变小,树的深度和最大棵数以及阈值都是和您一样的。 其中,预测对比我用的是: val predictions: DataFrame = gbtModel.transform(testData).select("SalePriceInt", "prediction") import org.apache.spark.ml.evaluation.RegressionEvaluator val evaluator = new RegressionEvaluator().setLabelCol("SalePriceInt").setPredictionCol("prediction").setMetricName("rmse") val rmse = evaluator.evaluate(predictions) println("Root Mean Squared Error (RMSE) on test data = " + rmse) 然后代码中我还设置了一个maxBins,不设置会报错。修改后的如下: val gbt = new GBTRegressor() .setLabelCol("SalePriceInt") .setFeaturesCol("indexedFeatures") // 限定每棵树的最大深度 .setMaxDepth(5) // 限定决策树的最大棵树 .setMaxIter(10) .setMaxBins(113) 就是很头疼,怎么用了好的模型,表现还变的糟糕了呢。 非常有兴趣的一直看到这里,突然觉得没有兴趣了。。。麻烦老师看看能不能帮忙指点一下。 全部代码比较长,贴不过来
作者回复: 老弟不必沮丧哈,机器学习就是这样,高级玩法试了一圈,发现效果并没有显著提升,有的时候,甚至更差,这个不必郁闷,大家一开始都是这样的~ 根本原因在于,我们对于数据、特征、模型(学习器)之间的本质区别,并没有从根儿上理解到位。咱们这门入门课,机器学习部分,受课程要求所限,篇章太少了,实际上机器学习涉及的方方面面非常多。机器学习,并不是跑个模型,调调参数那么简单,否则的话,算法工程师的工资不会那么高~ 模型效果,80%依赖特征,20%依赖模型选择、调优、调参,等等,我们从线性模型介绍到树模型,实际上,更多的是课程上的需要,为了给大家介绍更多种类型的模型,让大家知道,当需要类似模型和算法的时候,Spark都支持哪些,不支持哪些,从哪里选,怎么用。 但严格来说,并不是复杂模型,就一定比简单模型效果更好,在同一个假设空间,能够完美拟合训练数据的假设有多个,并不是复杂的模型,就是更好的。对于房价预测的例子,其实重中之重还是特征,老弟不妨去文中Kaggle对应的项目,聊一下排名靠前的那些项目,他们大部分都是使用各种“骚操作”来处理、生成特征,反而模型并不复杂。 由于咱们课程定位是入门,所以特征工程的部分,其实更得的,也是介绍方法,Spark MLlib支持哪些,不支持哪些,怎么用,真要用到的时候,怎么选。其实,咱们并没有针对这个项目,去仔细地做特征选择、特征生成,等等,这些非常必要的工作。 所以说,老弟不必气馁,咱们这里效果不好,主要是很多事情其实没多到位,并不是机器学习本身不给力,或是过于缥缈,一起加油哈~
2021-11-221  小新老师后面可以出一个详细的ML的课程吗?也是这样的讲解方式。
小新老师后面可以出一个详细的ML的课程吗?也是这样的讲解方式。作者回复: 最开始,其实是想出一门Spark MLlib + 机器学习的课程,但是后来跟极客时间商量之后,大家觉得Spark + 机器学习,受众面更小,所以后来改成了基础入门课,也就是咱们现在这门课程《零基础入门Spark》,后面找机会写一些专门针对机器学习的东西吧~
2021-12-05 六月的余晖老师后续有计划出Flink的课程吗
六月的余晖老师后续有计划出Flink的课程吗作者回复: 暂时还没有哈,杂务缠身,时间精力确实有限,等忙过这段时间再说吧,对不住老弟
2021-11-12- liangyu.setInputCols(numericFields ++ indexFields) 这里一个typo , numericfields 是没有转换成int的 ,前文用的是numeric features2022-12-15归属地:美国

