

28 | 模型训练(下):协同过滤与频繁项集算法详解
吴磊

你好,我是吴磊。
如果你平时爱刷抖音,或者热衷看电影,不知道有没有过这样的体验:这类影视 App 你用得越久,它就好像会读心术一样,总能给你推荐对胃口的内容。其实这种迎合用户喜好的推荐,离不开机器学习中的推荐算法。
今天是咱们模型训练的最后一讲,在今天这一讲,我们就结合两个有趣的电影推荐场景,为你讲解 Spark MLlib 支持的协同过滤与频繁项集算法。与上一讲一样,咱们还是先来贴出下面这张“全景图”,方便你对学过和即将要学的知识做到心中有数。
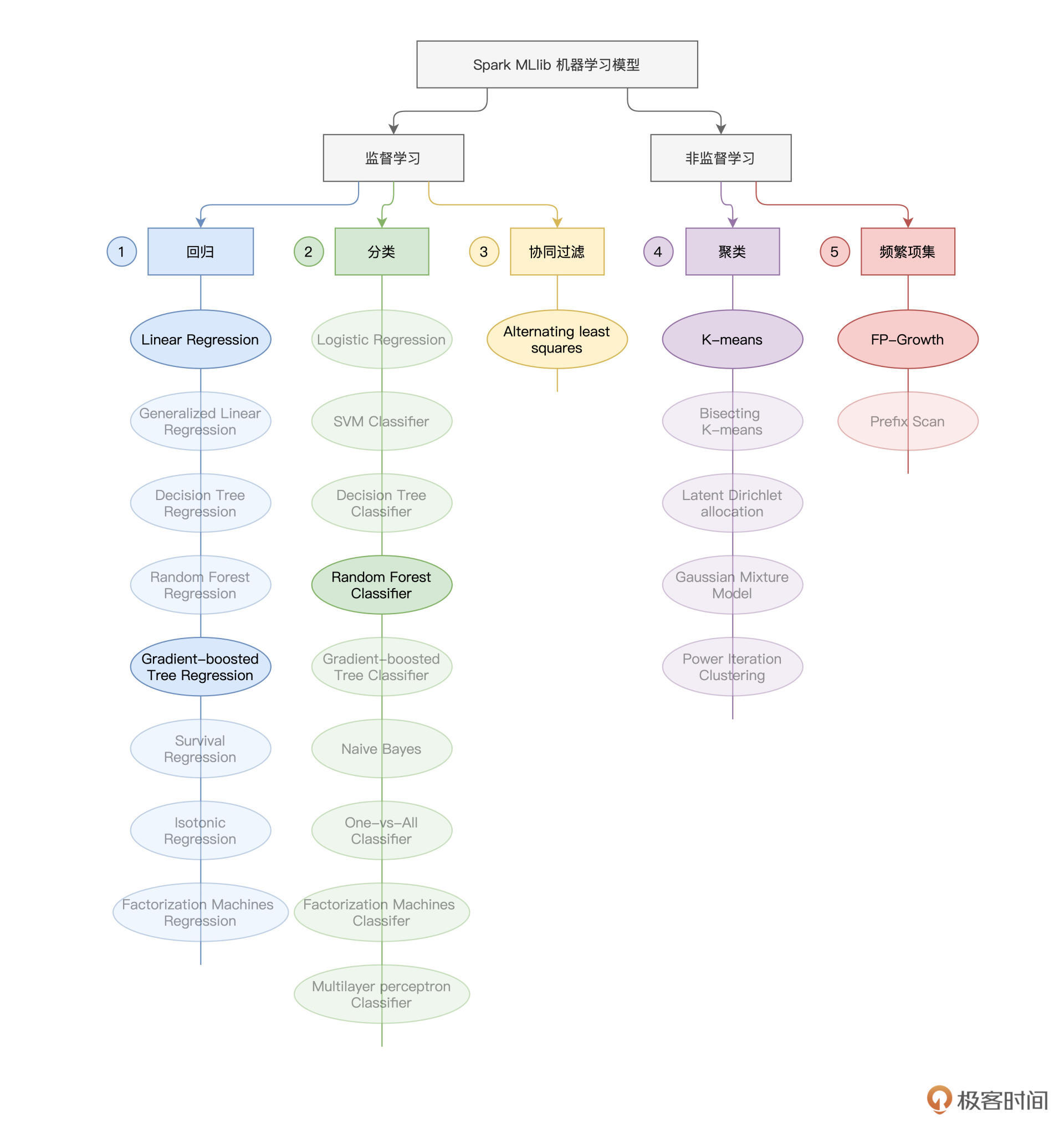
Spark MLlib支持的模型算法
电影推荐场景
今天这一讲,咱们结合 Kaggle 竞赛中的MovieLens 数据集,使用不同算法来构建简易的电影推荐引擎。尽管 MovieLens 数据集包含了多个文件,但课程中主要用到的,是 ratings.csv 这个文件。文件中的每条数据条目,记录的都是用户对于电影的打分,如下表所示。
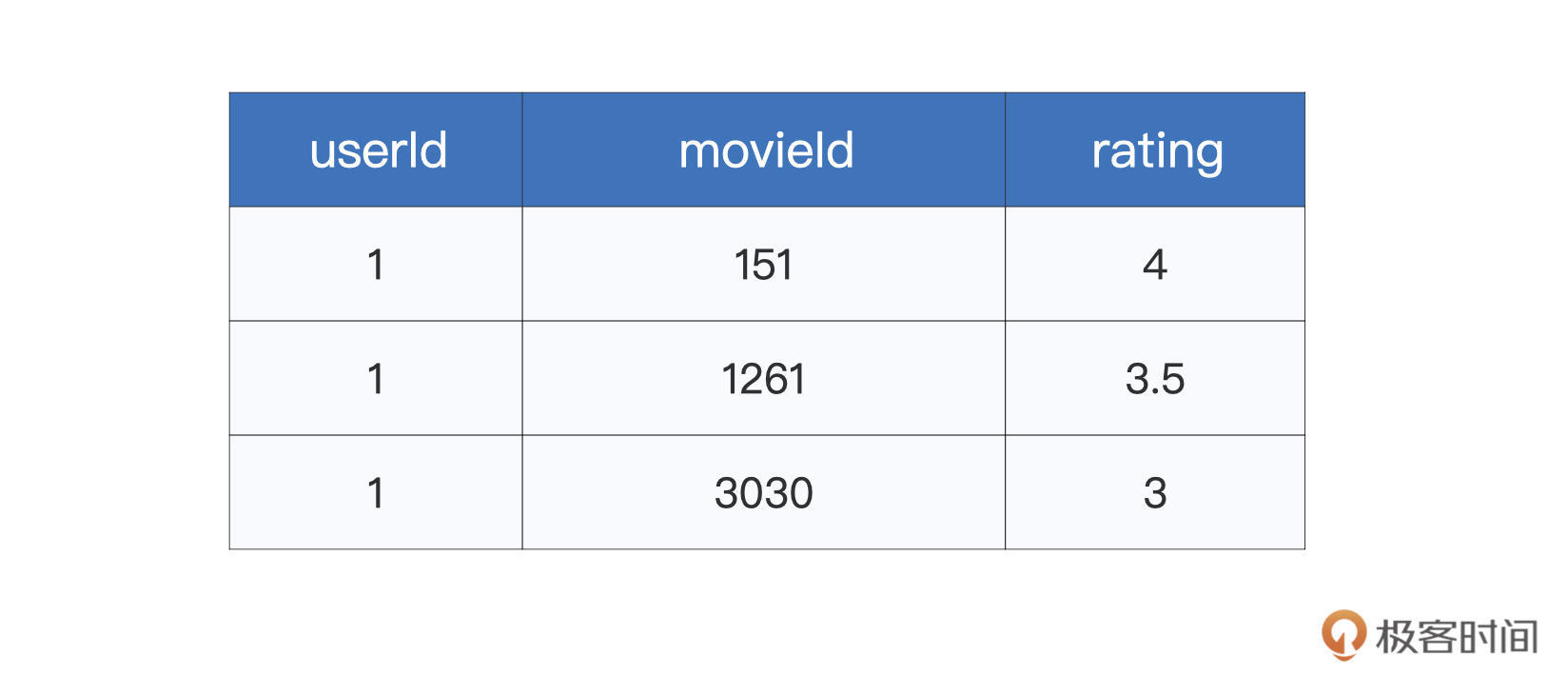
ratings.csv样本示例
其中第一列 userId 为用户 ID,movieId 表示电影 ID,而 rating 就是用户对于电影的评分。像这样,同时存有用户与物品(电影)信息的二维表,我们把它们统称为“交互矩阵”,或是“共现矩阵”。你可能会疑惑,通过这么一份简单的二维表,我们能干些什么呢?
可别小瞧这份数据,与合适的模型算法搭配在一起,我就能根据它们构建初具模样的推荐引擎。在 Spark MLlib 框架下,至少有两种模型算法可以做到这一点,一个是协同过滤(Collaborative Filtering),另一个是频繁项集(Frequency Patterns)。其中,前者天生就是用来做推荐用的,而后者是一种常规的非监督学习算法,你可以结合数据特点,把这个算法灵活运用于推荐场景。
公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结

Spark MLlib框架下的协同过滤与频繁项集算法在电影推荐场景中的应用是本文的重点。作者以Kaggle竞赛中的电影推荐引擎构建为例,通过分析用户对电影的评分数据,展示了如何利用这些数据构建推荐引擎。文章介绍了交互矩阵的概念,指出了这些数据的潜在价值,即通过合适的模型算法,可以构建初具模样的推荐引擎。 在Spark MLlib框架下,作者深入介绍了协同过滤和频繁项集两种适用于推荐场景的模型算法。协同过滤的核心思想是“相似的人倾向于喜好相似的物品集”,通过矩阵分解和ALS算法实现了用户与物品的Embedding,从而设计了一个简单的电影推荐引擎。频繁项集算法则是一种常规的非监督学习算法,可以根据数据特点灵活运用于推荐场景。 通过实际案例和技术原理的介绍,读者可以了解了协同过滤与频繁项集算法在电影推荐场景中的应用,为读者提供了深入学习和实践的基础。整篇文章通过代码演示和技术原理的讲解,使读者能够快速了解并掌握Spark MLlib框架下的推荐算法应用,为构建个性化推荐系统提供了有力的技术支持。文章还介绍了频繁项集算法的原理和应用场景,以及在Spark MLlib框架下如何进行频繁项集的计算和模型训练,为读者提供了实际操作的指导。 总之,本文通过深入的技术讲解和实际案例分析,为读者提供了在Spark MLlib框架下构建电影推荐引擎的全面指南,使读者能够快速掌握相关算法和工具,为推荐系统的开发和优化提供了重要参考。
仅可试看部分内容,如需阅读全部内容,请付费购买文章所属专栏
《零基础入门 Spark》,新⼈⾸单¥59
《零基础入门 Spark》,新⼈⾸单¥59
立即购买
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
全部留言(1)
- 最新
- 精选
 Abigail协同过滤算法本身其实对于推荐什么物品是一点都不关心的,所有的推荐机制都是基于用户对物品的行为来制定的, 优点基于用户行为,因此对推荐内容无需先验知识;只需要用户和商品的关联矩阵即可,结构简单;在用户行为丰富的情况下,效果好。 当然如此一来,缺点也非常明显:需要大量的显性/隐形的用户行为数据,有冷启动问题;需要通过完全相同的商品关联,相似的不行 aka 同义词问题;在数据稀疏的情况下易受影响。 频繁项集它暗示了某些事物之间总是结伴或成对出现。本质上来说,不管是因果关系还是相关关系,都是共现关系。理论上所有机器学习算法都可以暴力搜索,也就不需要承担启发式搜索带来的局部优化损失问题,估计现在很少有人这么做了。FP-growth算法只需要对数据库进行两次扫描,同Aprion相比压缩度更高,不过对内存开销大,而且只能用于挖掘单维的布尔关联规则。理论上一般建议使用Apriori算法进行关联分析,用FP-growth算法来高效发现频繁项集。当然实际工程还是要根据数据的质量和目标需求以及运营成本来调整。
Abigail协同过滤算法本身其实对于推荐什么物品是一点都不关心的,所有的推荐机制都是基于用户对物品的行为来制定的, 优点基于用户行为,因此对推荐内容无需先验知识;只需要用户和商品的关联矩阵即可,结构简单;在用户行为丰富的情况下,效果好。 当然如此一来,缺点也非常明显:需要大量的显性/隐形的用户行为数据,有冷启动问题;需要通过完全相同的商品关联,相似的不行 aka 同义词问题;在数据稀疏的情况下易受影响。 频繁项集它暗示了某些事物之间总是结伴或成对出现。本质上来说,不管是因果关系还是相关关系,都是共现关系。理论上所有机器学习算法都可以暴力搜索,也就不需要承担启发式搜索带来的局部优化损失问题,估计现在很少有人这么做了。FP-growth算法只需要对数据库进行两次扫描,同Aprion相比压缩度更高,不过对内存开销大,而且只能用于挖掘单维的布尔关联规则。理论上一般建议使用Apriori算法进行关联分析,用FP-growth算法来高效发现频繁项集。当然实际工程还是要根据数据的质量和目标需求以及运营成本来调整。作者回复: 老弟总结得很到位,赞👍~
2021-11-173
收起评论

