

09 | RDD常用算子(三):数据的准备、重分布与持久化

 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

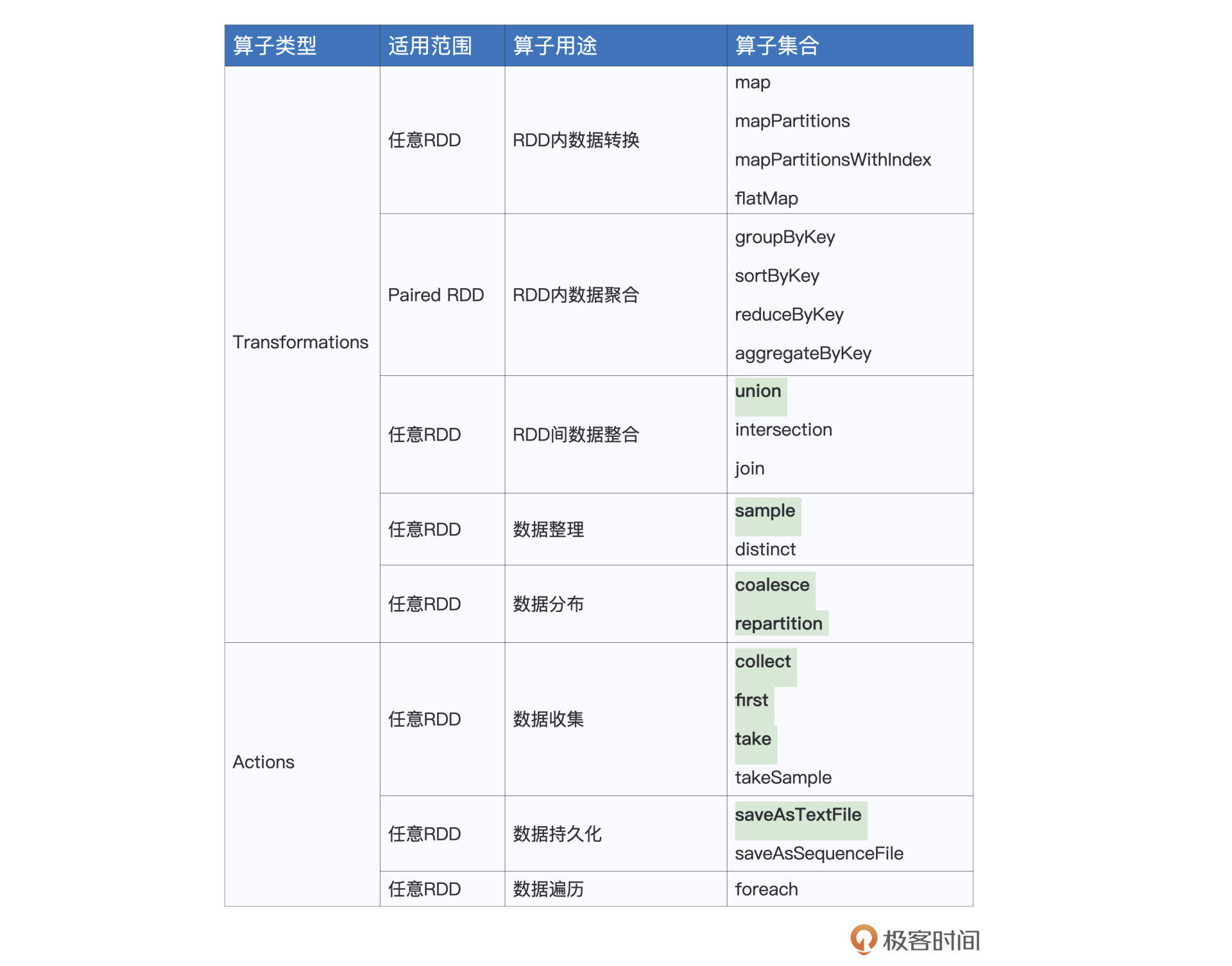
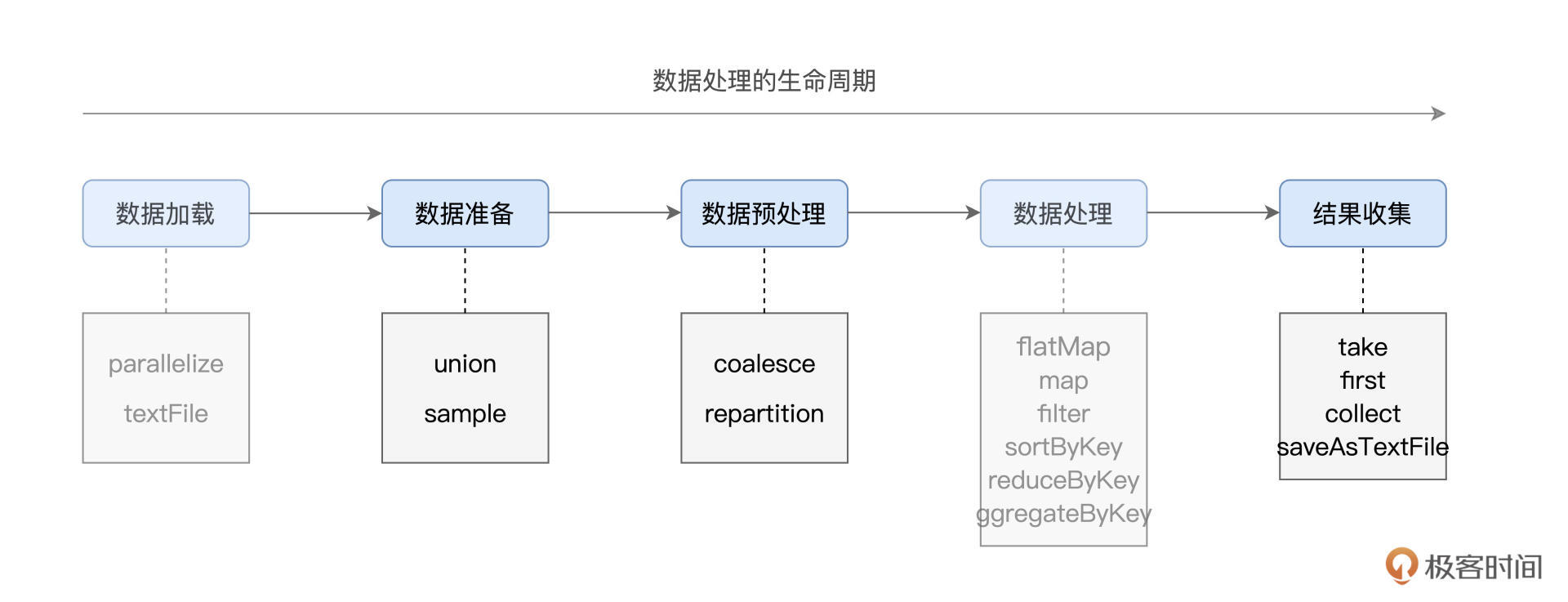
本文介绍了RDD常用算子中的数据准备、重分布与持久化部分。作者从数据生命周期的角度出发,介绍了在数据准备阶段的union和sample算子。在数据预处理阶段,作者介绍了repartition和coalesce算子,用于调整RDD的并行度和数据分布。文章通过具体的代码示例和场景说明,使读者能够快速了解这些算子的用法和作用。在介绍repartition时,强调了合理设置RDD并行度的重要性,以及repartition引入Shuffle的弊端。而在介绍coalesce时,则着重对比了其与repartition的执行计划差异,以及其不引入Shuffle的原因。最后,文章提到了数据处理阶段的结果收集,介绍了两类收集算子的应用场景。整体而言,本文通过深入浅出的方式,帮助读者快速掌握RDD常用算子中数据准备、重分布与持久化的关键知识点。文章还介绍了第一类算子first、take和collect的用法,以及第二类算子saveAsTextFile的作用,帮助读者更好地理解RDD算子的工作原理。通过对算子与数据生命周期不同阶段的对应关系的总结,读者可以更好地掌握这些算子的灵活运用,应对日常开发中的业务需求。
《零基础入门 Spark》,新⼈⾸单¥59

全部留言(15)
- 最新
- 精选
 GAC·DU置顶#合并RDD 测试了三种方法,分别是union、reduce、++,并且通过调用toDebugString方法查看,显示结果是一致的,下面的代码是在spark-shell上测试的 ```scala scala> val rdd1 = spark.sparkContext.parallelize(1 to 10) scala> val rdd2 = spark.sparkContext.parallelize(20 to 30) scala> val unionRDD = rdd1 union rdd2 scala> unionRDD.collect res3: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30) scala> unionRDD.toDebugString res4: String = (16) UnionRDD[2] at union at <console>:27 [] | ParallelCollectionRDD[0] at parallelize at <console>:23 [] | ParallelCollectionRDD[1] at parallelize at <console>:23 [] scala> val data = Seq(rdd1, rdd2) scala> data.foreach(println) ParallelCollectionRDD[0] at parallelize at <console>:23 ParallelCollectionRDD[1] at parallelize at <console>:23 scala> val reduceRDD = data.reduce(_ union _) scala> reduceRDD.collect res6: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30) scala> reduceRDD.toDebugString res7: String = (16) UnionRDD[3] at union at <console>:25 [] | ParallelCollectionRDD[0] at parallelize at <console>:23 [] | ParallelCollectionRDD[1] at parallelize at <console>:23 [] scala> val addRDD = rdd1 ++ rdd2 scala> addRDD.collect res15: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30) scala> addRDD.toDebugString res16: String = (16) UnionRDD[7] at $plus$plus at <console>:27 [] | ParallelCollectionRDD[0] at parallelize at <console>:23 [] | ParallelCollectionRDD[1] at parallelize at <console>:23 [] ``` # coalesce 潜在隐患 repartition和coalesce相比较,repartition由于引入了shuffle机制,对数据进行打散,混洗,重新平均分配,所以repartition操作较重,但是数据分配均匀。而coalesce只是粗力度移动数据,没有平均分配的过程,会导致数据分布不均匀,在计算时出现数据倾斜。
GAC·DU置顶#合并RDD 测试了三种方法,分别是union、reduce、++,并且通过调用toDebugString方法查看,显示结果是一致的,下面的代码是在spark-shell上测试的 ```scala scala> val rdd1 = spark.sparkContext.parallelize(1 to 10) scala> val rdd2 = spark.sparkContext.parallelize(20 to 30) scala> val unionRDD = rdd1 union rdd2 scala> unionRDD.collect res3: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30) scala> unionRDD.toDebugString res4: String = (16) UnionRDD[2] at union at <console>:27 [] | ParallelCollectionRDD[0] at parallelize at <console>:23 [] | ParallelCollectionRDD[1] at parallelize at <console>:23 [] scala> val data = Seq(rdd1, rdd2) scala> data.foreach(println) ParallelCollectionRDD[0] at parallelize at <console>:23 ParallelCollectionRDD[1] at parallelize at <console>:23 scala> val reduceRDD = data.reduce(_ union _) scala> reduceRDD.collect res6: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30) scala> reduceRDD.toDebugString res7: String = (16) UnionRDD[3] at union at <console>:25 [] | ParallelCollectionRDD[0] at parallelize at <console>:23 [] | ParallelCollectionRDD[1] at parallelize at <console>:23 [] scala> val addRDD = rdd1 ++ rdd2 scala> addRDD.collect res15: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30) scala> addRDD.toDebugString res16: String = (16) UnionRDD[7] at $plus$plus at <console>:27 [] | ParallelCollectionRDD[0] at parallelize at <console>:23 [] | ParallelCollectionRDD[1] at parallelize at <console>:23 [] ``` # coalesce 潜在隐患 repartition和coalesce相比较,repartition由于引入了shuffle机制,对数据进行打散,混洗,重新平均分配,所以repartition操作较重,但是数据分配均匀。而coalesce只是粗力度移动数据,没有平均分配的过程,会导致数据分布不均匀,在计算时出现数据倾斜。作者回复: 优秀!👍👍👍 满分💯,置顶🔝
2021-09-2916 火炎焱燚老师,我这儿遇到了一个问题,不太明白,一共有100个数字,每次sample(False,0.1)理论上应该会获取10个数字,但运行几次得到的数字个数都不同,有的是8个,有的11个,这是为啥?spark中sample的原理不会精确控制个数吗? 运行代码: >>> rdd.sample(False,0.1).collect() [1, 18, 23, 25, 31, 52, 59, 73, 95, 96, 97] >>> rdd.sample(False,0.1).collect() [11, 12, 13, 36, 40, 50, 51, 77, 90] >>> rdd.sample(False,0.1).collect() [2, 13, 21, 33, 51, 59, 73, 80, 84, 88] >>> rdd.sample(False,0.1).collect() [3, 18, 41, 44, 67, 87, 89, 91] >>> rdd.sample(False,0.1).collect() [35, 41, 69, 75, 87, 92, 99]
火炎焱燚老师,我这儿遇到了一个问题,不太明白,一共有100个数字,每次sample(False,0.1)理论上应该会获取10个数字,但运行几次得到的数字个数都不同,有的是8个,有的11个,这是为啥?spark中sample的原理不会精确控制个数吗? 运行代码: >>> rdd.sample(False,0.1).collect() [1, 18, 23, 25, 31, 52, 59, 73, 95, 96, 97] >>> rdd.sample(False,0.1).collect() [11, 12, 13, 36, 40, 50, 51, 77, 90] >>> rdd.sample(False,0.1).collect() [2, 13, 21, 33, 51, 59, 73, 80, 84, 88] >>> rdd.sample(False,0.1).collect() [3, 18, 41, 44, 67, 87, 89, 91] >>> rdd.sample(False,0.1).collect() [35, 41, 69, 75, 87, 92, 99]作者回复: 好问题,你说的没错,Spark的采样,确实不会精确地控制个数。这跟他的采样原理有关,Spark采用伯努利或是泊松分布来做采样,对于每一个数据元素的采样,都是独立的。比如这里的0.1,也就是10%的采样率,Spark会对RDD每个元素抛个骰子,骰子值小于10%,才会把这个元素采集出去。因此,10%这个比例只是在统计上的一种近似,而不会精确地保证每次采样的个数,一定是原数据的10%。一个tips是,采样率越高,精确率越高,这个还是那句话,跟刚才的采样原理有关~ 如果想精确采样的话,可以这么做: rdd.takeSample(false, 1000) 这样得到的结果,一定是采集1000个数值。但是请注意,这里的返回结果,不再是RDD,而是array。takeSample的实现,实际上也是调用sample算子,只不过在最后,加入了元素个数上的检查,所以可以保证采样结果,一定是这里指定的1000。最后,要强调的是,takeSample会把结果收集到Driver端,所以要注意它对于Driver端内存的消耗~
2021-10-0913
 qinsi从文中的描述来看,coalesce似乎并不能避免shuffle?极端的例子,coalesce(1)必然会把数据都放入同一个Executor里?
qinsi从文中的描述来看,coalesce似乎并不能避免shuffle?极端的例子,coalesce(1)必然会把数据都放入同一个Executor里?作者回复: 非常好的问题,我们来细说说~ 取决于你如何调用coalesce(1, shuffle = false/true),分两种情况。 1. shuffle = false,这个时候,coalesce不会引入Shuffle,但是,所有操作,从一开始,并行度都是1,都在一个executor计算,显然,这个时候,整个作业非常慢,奇慢无比 2. shuffle = true,这个时候,coalesce就会引入shuffle,切割stage。coalesce之前,用源数据DataFrame的并行度,这个时候是多个Executors真正的并行计算;coalesce之后,也就是shuffle之后,并行度下降为1,所有父RDD的分区,全部shuffle到一个executor,交给一个task去计算。 显然,相比前一种,这种实现在执行效率上,更好一些。因此,如果业务应用必须要这么做,推荐这一种实现方法。回答你最初的问题,没错,coalesce(1)必然会把数据都放入同一个Executor里
2021-09-299- Geek_2dfa9a第一题 没明白考点是啥,考的是scala的语法么? val rdd1 = sc.textFile("") val rdd2 = sc.textFile("") val rdd3 = sc.textFile("") val unionRdd = rdd1.union(rdd2).union(rdd3) val unionRdd2 = Seq(rdd1, rdd2, rdd3).reduce(_.union(_)) 第二题 repartition也是通过colesce实现的,只不过repartition默认是要shuffle的,也就是说,repartition肯定是会通过哈希重分区的, 不管分区前数据分布是否均匀,分区后数据分布会比较均匀,但是colesce就未必了,colesce默认是不shuffle的,会尽量在local合并分区, 如果colesce之前数据是分布不均匀的,那colesce之后数据分布还是不均匀的,这种情况下指定方法入参shuffle=true就解决了。
作者回复: 正解,满分💯 👍
2021-09-3038 - Geek_038655collect对于大数据分析结果过大导致的OOM问题,用saveAsTextFile解决是不是过于迁就? 为什么不用foreashPartition?
作者回复: 并无优劣之分~ foreachPartition更多地用来写DB和Kafka;而saveAsTextFile用来写文件系统。数据写入标的不同而已,没有优劣上的差别。 当然,也可以用foreachPartition来写文件系统,但是这个时候,就不如直接调用saveAsTextFile这类算子方便。
2021-09-296  爱吃猫的鱼coalesce 会降低同一个 stage 计算的并行度,导致 cpu 利用率不高,任务执行时间变长。我们目前有一个实现是需要将最终的结果写成单个 avro 文件,前面的转换过程可能是各种各样的,我们在最后阶段加上 repartition(1).write().format('avro').mode('overwrite').save('path')。最近发现有时前面的转换过程中有排序时,使用 repartition(1) 有时写得单文件顺序不对,使用 coalesce(1) 顺序是对的,但 coalesce(1) 有性能问题。目前想到可以 collect 到 driver 自己写 avro 文件,但可能存在以上提到的内存问题,不知道有没有更好的方案?
爱吃猫的鱼coalesce 会降低同一个 stage 计算的并行度,导致 cpu 利用率不高,任务执行时间变长。我们目前有一个实现是需要将最终的结果写成单个 avro 文件,前面的转换过程可能是各种各样的,我们在最后阶段加上 repartition(1).write().format('avro').mode('overwrite').save('path')。最近发现有时前面的转换过程中有排序时,使用 repartition(1) 有时写得单文件顺序不对,使用 coalesce(1) 顺序是对的,但 coalesce(1) 有性能问题。目前想到可以 collect 到 driver 自己写 avro 文件,但可能存在以上提到的内存问题,不知道有没有更好的方案?作者回复: 想必老弟对coalesce(1, shuffle = false/true)的用法和区别,已经了如指掌,不再赘述。 遗憾的是,驴和熊猫不可兼得,想要高性能的同时做到保序,确实不容易。shuffle = false/true,前者保序,后者高性能,确实两者很难兼得。 实在对不住,对于两者都需要的场景,我暂时还真想不到特别好的办法,除了你说的“先shuffle -> coalesce(1, shuffle = true) -> 再排序 -> 再收集”之外,我现在还真想不到更好的办法,抱歉
2021-09-2942 Unknown element老师我看了评论区那个关于coalesce(1,shuffle = false)的问题,您说这个时候coalesce不会引入Shuffle,但是所有操作并行度都是1,都在一个executor计算;这里我不太明白,既然数据是分布在多个节点上,又不能用shuffle,那数据是怎么被汇集到一个节点的?
Unknown element老师我看了评论区那个关于coalesce(1,shuffle = false)的问题,您说这个时候coalesce不会引入Shuffle,但是所有操作并行度都是1,都在一个executor计算;这里我不太明白,既然数据是分布在多个节点上,又不能用shuffle,那数据是怎么被汇集到一个节点的?作者回复: 好问题~ coalesce(1,shuffle = false),首先,shuffle = false,通常是为了保序,否则没必要。然后,coalesce(1,shuffle = false),它的目标,是把分区数降低为1。要做到没有Shuffle,那只有从源头上就开始限制,也就是说,源头上的并行度,就是1。只有这样,才能做到最后在没有Shuffle的情况下,把并行度降低为1。 需要说明的是,这种“骚操作”会拖累整个作业的执行性能,如非必要,绝不推荐这么做~
2021-10-0431 钱鹏 Allen1. 方法一:Seq(rdd1,rdd2).reduce(_ union _) 方法二: rdd1 ++ rdd2 (高赞精简版本) 2.大数据量的情况下,相比 repartition,coalesce没有shuffle,可能会导致数据倾斜,即一个分区上有着大量的数据,而另外一个可能没有多少数据。
钱鹏 Allen1. 方法一:Seq(rdd1,rdd2).reduce(_ union _) 方法二: rdd1 ++ rdd2 (高赞精简版本) 2.大数据量的情况下,相比 repartition,coalesce没有shuffle,可能会导致数据倾斜,即一个分区上有着大量的数据,而另外一个可能没有多少数据。作者回复: 正解,满分💯~
2021-10-0321 实数sortshuufle是不是能保证全局有序呢 第一代的hashshuffle好像是不是废弃了 ,老师有空能不能讲下bypass mergesort、unsafe、sort shuffle ,这三个确实不懂
实数sortshuufle是不是能保证全局有序呢 第一代的hashshuffle好像是不是废弃了 ,老师有空能不能讲下bypass mergesort、unsafe、sort shuffle ,这三个确实不懂作者回复: 第一个问题,在第6讲的问题里面回复了哈~ 第6讲:06 | Shuffle管理,其实就是在介绍Sort-based shuffle的工作原理,只不过作为入门课,我们没有特别点明。bypass mergesort,实际上就是当reduce分区数小于一定阈值、且计算中不存在Aggregate操作,Spark就把Sort-based shuffle退化为Hash-based shuffle,因此,bypass mergesort实际的应用场景非常有限,因为一般来说,数据分析都少不了数据聚合,也就少不了Aggregate操作。 unsafe shuffle,其实底子还是Sort-based shuffle,但是利用了Tungsten的数据结构来做优化,Tungsten相关内存,老弟可以参考:14 | 台前幕后:DataFrame与Spark SQL的由来
2021-11-29 Andy如前一章内存,我看过一些博客文章也没看明白,老师一讲我就理解了。本章老师和同学的评论,进一步加强了对coalesce解释(shuffle和非shuffle的区别),如coalesce(1) shuffle是多个executer输出数据到一个executer不保证数据顺序,但运行速度快。本章第一题没达出来,看官网文档和百度也没达上来。应该是我对scala语法不熟。第二题我的答案是可能会导致分区数据不均,严重的会导致数据倾斜计算慢或内存溢出。
Andy如前一章内存,我看过一些博客文章也没看明白,老师一讲我就理解了。本章老师和同学的评论,进一步加强了对coalesce解释(shuffle和非shuffle的区别),如coalesce(1) shuffle是多个executer输出数据到一个executer不保证数据顺序,但运行速度快。本章第一题没达出来,看官网文档和百度也没达上来。应该是我对scala语法不熟。第二题我的答案是可能会导致分区数据不均,严重的会导致数据倾斜计算慢或内存溢出。作者回复: 确实,第一题跟scala语法比较相关,可以参考Geek_2dfa9a同学给出的答案哈:val unionRdd2 = Seq(rdd1, rdd2, rdd3).reduce(_.union(_))。 第二题满分💯~
2021-11-14

