

07 | RDD常用算子(二):Spark如何实现数据聚合?

 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

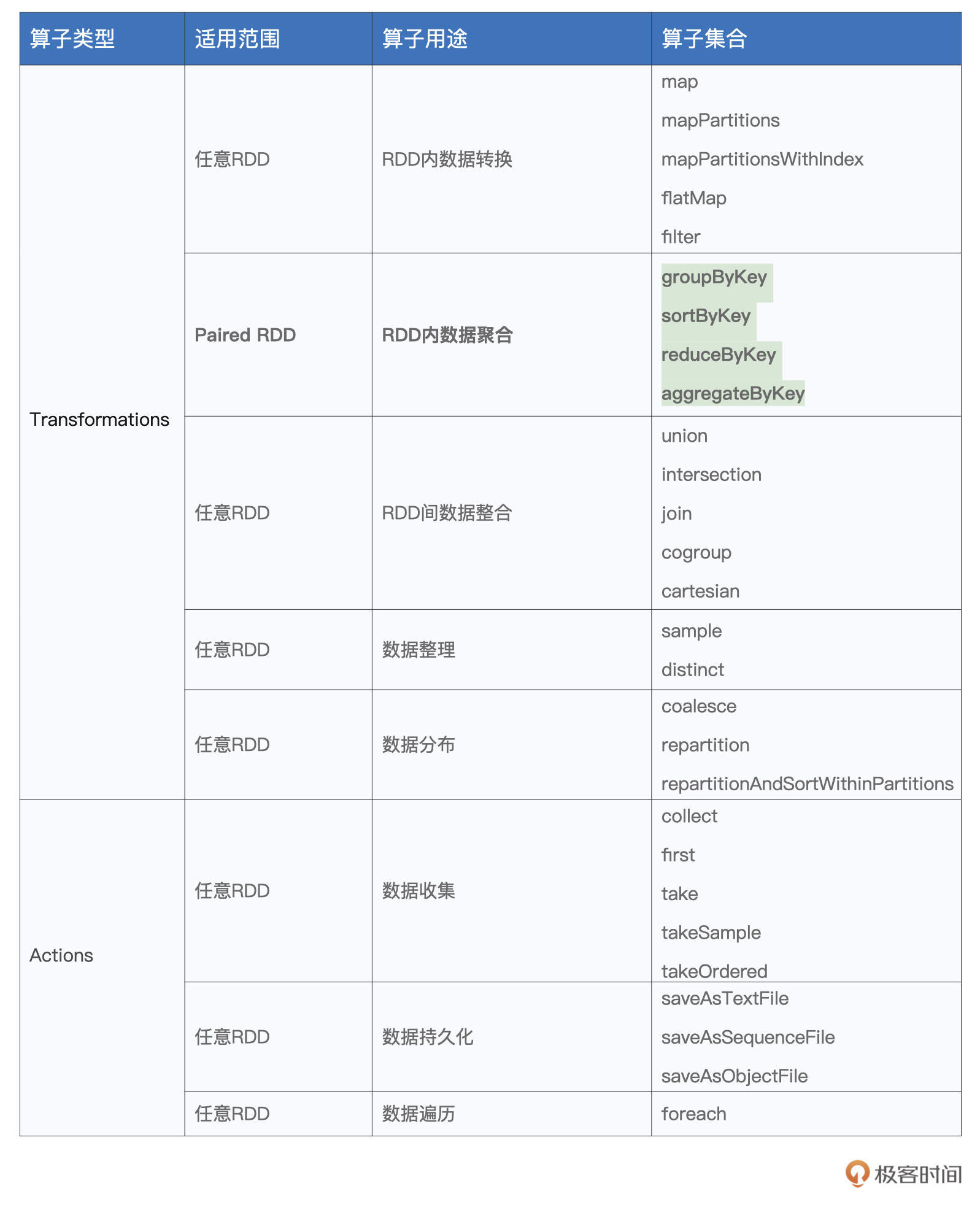
本文深入介绍了Spark中常用的数据聚合算子,包括groupByKey、reduceByKey、aggregateByKey和sortByKey。通过清晰的示例和解释,读者能够快速掌握这些算子的用法和计算过程。文章指出了groupByKey算子执行效率较差的问题,并重点回顾了reduceByKey和aggregateByKey算子的灵活性和功能性。此外,还介绍了sortByKey算子用于按照Key进行排序。总的来说,本文帮助读者了解了Spark中实现数据聚合的方式,为开发数据分析应用提供了重要基础。通过掌握这些算子的用法与原理,读者能够游刃有余地开发数据分析应用,为他们在实际开发中应用这些算子提供了指导和帮助。
《零基础入门 Spark》,新⼈⾸单¥59

全部留言(9)
- 最新
- 精选
- Geek_2dfa9a置顶最近公司在搞黑客马拉松,我忙于做一个数仓血缘图计算的项目来晚啦。 reduceByKey和aggregateByKey底层使用了同一个方法实现:combineByKeyWithClassTag,该方法是将KV型的RDD[(K, V)]转换为RDD[(K, C)], 类似于分组聚合,既然要找到reduceByKey和aggregateByKey的联系那肯定要从下至上由共性开始分析,combineByKeyWithClassTag方法声明如下: def combineByKeyWithClassTag[C]( createCombiner: V => C, mergeValue: (C, V) => C, mergeCombiners: (C, C) => C, partitioner: Partitioner, mapSideCombine: Boolean = true, serializer: Serializer = null)(implicit ct: ClassTag[C]): RDD[(K, C)] = self.withScope { } 字数限制了,我把方法实现放在下面评论。 首先讲三个高阶函数入参:createCombiner,mergeValue,mergeCombiners数,在方法里组成了Aggregator对象,Aggregator 其实就是spark对分组聚合(Shuffle)操作的抽象,如果不清楚spark分组聚合的过程这三个高阶函数不好理解,简单点讲,RDD按照Key分组后因为 不同Partition里会有相同Key,因此对于Key=k1这个大组会有多个小组(k11,k12...k1n),首先createCombiner会给k11,k12...k1n) 每个小组赋一个初始值C0,然后mergeValue把小组内的每个记录叠加给初始值得到一个小组值C00(其实就是map端聚合),最后再把所有小组的 小组值合并成一个KV型RDD(注意这里V已经变成了C类型)。 再讲参数partitioner,了解RDD的话应该清楚,就是这个RDD的分区规则,这里的入参就是聚合后RDD的分区规则,如果相同的话,那Shuffle就完全不需要了, 直接task本地聚合一下就好了,源码里也就直接mapPartitions就结束了,如果聚合前后分区规则不相同的话,那么就会返回一个ShuffledRDD。 最后讲下参数mapSideCombine和serializer,mapSideCombine就是是否在map端聚合,方法开头的校验可以看到keyClass是数组时不支持 map端聚合和哈希分区,这里是为什么呢?不太熟悉scala的我查了下stackoverflow,原来scala里的数组和Java的一样,hashcode只是数组对象本身的 hashcode,和内容没关系,那自然没办法map端聚合了, 这里请问老师,那数组作为KVRDD的时候,reduce端的聚合是怎么完成判等的呢? serializer是指出数据如何序列化的,序列化就先不说了,不然又要讲好多。 最后总结下,reduceByKey和aggregateByKey底层实现完全相同,都是combineByKeyWithClassTag,只不过reduceByKey调用 combineByKeyWithClassTag的入参mergeValue和mergeCombiners是相等的,aggregateByKey是用户指定可以不等的,也就是说 reduceByKey是一种特殊的aggregateByKey。
作者回复: 完美,满分💯!置顶🔝 数组的hashcode,其实就是它的内存地址,就像你说的,跟内容无关。因此,它没有办法利用hashPartitioner完成分发,所以说,key是数组的rdd,应用范围非常有限。 除了hashPartitioner,Spark还支持rangePartitioner,这种分区器,不需要hashcode,只要实现了comparator(能比较)就行。所以即便非要用hashcode来排序,也ok。这个时候,内容是否一样,已经不重要了。 reduce阶段需要聚合的场景,一定是需要hashPartitioner的,由于数组不支持hashPartitioner,它也就走不到reduce那一步,没有这样的code path~
2021-09-26320 - Geek_2a0debreduceByKey 和 aggregateByKey的区别在于reduceByKey在map端和reduce时的聚合函数一致,而aggregateByKey在map端和reduce端聚合函数可以不一致,联系就是reduceByKey可以认为是一种特殊的aggregateByKey(map和reduce是同一个函数)如果用算子来描述:reduceByKey(f)=aggregateByKey(初始值) (f,f)
作者回复: 没错,满分~ 💯
2022-01-111  Botanic``` # 使用 aggregateByKey 来实现 reduceByKey def f1(x, y): # 显示定义Map阶段聚合函数f1,求加和 return x+y import random # 实验3:aggregateByKey 使用说明 textFile = SparkContext().textFile("../wikiOfSpark.txt") wordCount = ( textFile.flatMap(lambda line: line.split(" ")) .filter(lambda word: word != "") .map(lambda word: (word, 1)) .aggregateByKey(0, f1, f1) .sortBy(lambda x: x[1], False) .take(5)) print(wordCount) ```
Botanic``` # 使用 aggregateByKey 来实现 reduceByKey def f1(x, y): # 显示定义Map阶段聚合函数f1,求加和 return x+y import random # 实验3:aggregateByKey 使用说明 textFile = SparkContext().textFile("../wikiOfSpark.txt") wordCount = ( textFile.flatMap(lambda line: line.split(" ")) .filter(lambda word: word != "") .map(lambda word: (word, 1)) .aggregateByKey(0, f1, f1) .sortBy(lambda x: x[1], False) .take(5)) print(wordCount) ```作者回复: 满分,💯,赞👍~
2021-12-22- pythonbug我感觉aggregateByKey直接作用在刚刚读取数据的RDD上的情况很少,因为刚刚从数据源读取出来的数据分区大多数时候是没啥业务含义的,所以Map阶段的聚合也没有太大意义。所以猜测,aggregateByKey可能大多数情况是跟在reduceByKey之后,那个时候已经对数据按照业务分区好了。那个时候Map阶段的聚合才有一些意义,不知道猜的对不对
作者回复: 没什么关系哈,aggregateByKey可以理解成是reduceByKey的“升级版”,功能更灵活,能够应对的计算场景更多~ 实际上,reduceByKey完全可以用aggregateByKey来实现~
2021-11-14  十年请问老师,aggregateByKey的初始值有什么作用?
十年请问老师,aggregateByKey的初始值有什么作用?作者回复: 数值的话,可以指定非零初始值,字符串的话,可以指定任意前缀字符串~ 主要看业务需要了
2021-10-072 钱鹏 AllenreduceByKey 和 aggregateByKey的联系:将相同的key值进行聚合。不同点:reduceByKey()采用的是相同的func,在map阶段使用sum操作,reduce阶段采用max操作就不满足。 aggregateByKey可以看做是更一般的reduceByKey,
钱鹏 AllenreduceByKey 和 aggregateByKey的联系:将相同的key值进行聚合。不同点:reduceByKey()采用的是相同的func,在map阶段使用sum操作,reduce阶段采用max操作就不满足。 aggregateByKey可以看做是更一般的reduceByKey,作者回复: 对的~
2021-09-28
 J讲解aggregateByKey计算过程时,图例错写成了“reduceByKey计算过程”2022-08-07归属地:湖北1
J讲解aggregateByKey计算过程时,图例错写成了“reduceByKey计算过程”2022-08-07归属地:湖北1 睿晞aggregateByKey算子中第一个默认参数的使用方法是什么啊?是直接参与到第二个聚合函数(reduce端)里面运算吗?比如,默认参数是0,然后如果第二个聚合函数是max求最大值,初始默认参数是参与比较的,用0和每个字段中的值比较,是这个意思吗?2022-04-27
睿晞aggregateByKey算子中第一个默认参数的使用方法是什么啊?是直接参与到第二个聚合函数(reduce端)里面运算吗?比如,默认参数是0,然后如果第二个聚合函数是max求最大值,初始默认参数是参与比较的,用0和每个字段中的值比较,是这个意思吗?2022-04-27 SpoonJava实现代码 https://github.com/Spoon94/spark-practice/blob/master/src/main/java/com/spoon/spark/core/AggOpJob.java2022-03-271
SpoonJava实现代码 https://github.com/Spoon94/spark-practice/blob/master/src/main/java/com/spoon/spark/core/AggOpJob.java2022-03-271

