

04 | 进程模型与分布式部署:分布式计算是怎么回事?

 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

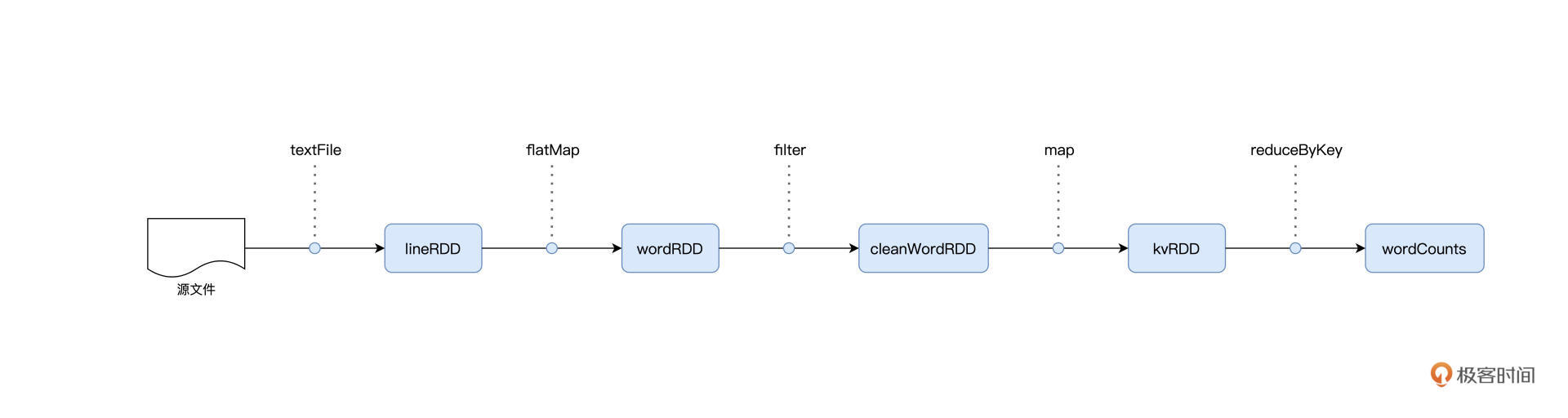
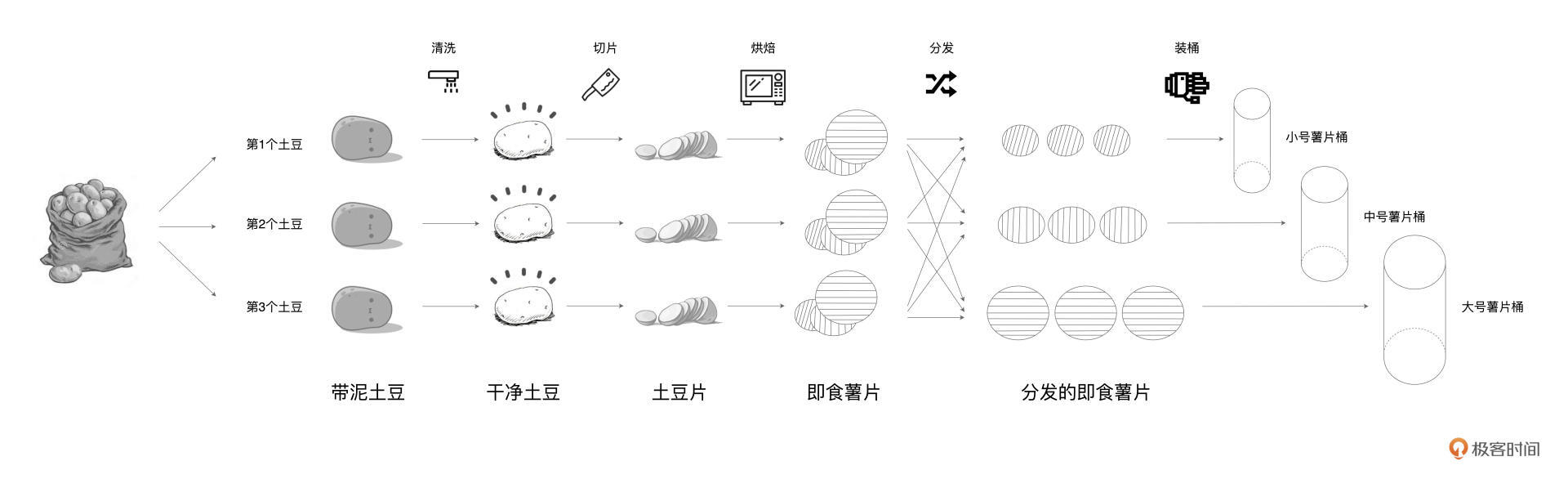
本文深入介绍了分布式计算的概念以及Spark在分布式计算中的应用。通过比较Word Count计算流图和土豆工坊的流水线工艺,阐述了抽象流程图与具体执行步骤的区别和联系。详细介绍了Spark的进程模型,包括Driver和Executors之间的关系,以及它们在分布式任务调度中的作用。通过生动的比喻,将Driver比作包工头,而Executors则是施工工人,形象地解释了它们之间的关系和各自的职责。此外,还介绍了Spark支持的分布式部署模式,主要有Standalone、YARN、Mesos、Kubernetes。其中,Standalone是Spark内置的资源调度器,而YARN、Mesos、Kubernetes是独立的第三方资源调度与服务编排框架。文章通过生动的比喻和清晰的逻辑,帮助读者快速了解了分布式计算的概念以及Spark的进程模型。
《零基础入门 Spark》,新⼈⾸单¥59

全部留言(20)
- 最新
- 精选
 路人丁置顶老师好!讲解很精彩! 为了帮助大家理解,还是要说说 standalone 模式下的 主从选举过程,三个节点怎么互相找到并选出主从。另外,standalone 模式下的 master 和 worker,与前面进程模型里说的 Driver 和 executor,二组之间的对应关系,也要讲讲。只要能简单串起来就可以了。让大家获得一个即便简单、但却完成的理解模型。
路人丁置顶老师好!讲解很精彩! 为了帮助大家理解,还是要说说 standalone 模式下的 主从选举过程,三个节点怎么互相找到并选出主从。另外,standalone 模式下的 master 和 worker,与前面进程模型里说的 Driver 和 executor,二组之间的对应关系,也要讲讲。只要能简单串起来就可以了。让大家获得一个即便简单、但却完成的理解模型。作者回复: 感谢老弟,问题提得很好~ 先说说选主,这个其实比较简单,Standalone部署模式下,Master与Worker角色,这个是我们通过配置文件,事先配置好的,所以说,哪台是Master,哪台是Worker,这个配置文件里面都有。在Standalone部署下,先启动Master,然后启动Worker,由于配置中有Master的连接地址,所以Worker启动的时候,会自动去连接Master,然后双方建立心跳机制,随后集群进入ready状态。 接下来说Master、Worker与Driver、Executors的关系。首先,这4个“家伙”,都是JVM进程。不过呢,他们的定位和角色,是完全不一样的。Master、Worker用来做资源的调度与分配,你可以这样理解,这两个家伙,只负责维护集群中可用硬件资源的状态。换句话说,Worker记录着每个计算节点可用CPU cores、可用内存,等等。而Master从Worker收集并汇总所有集群中节点的可用计算资源。 Driver和Executors的角色,那就纯是Spark应用级别的进程了。这个咱们课程有介绍,就不赘述了。Driver、Executors的计算资源,全部来自于Master的调度。一般来说,Driver会占用Master所在节点的资源;而Executors一般占用Worker所在节点的计算资源。一旦Driver、Executors从Master、Worker那里申请到资源之后,Driver、Executors就不再“鸟”Master和Worker了,因为资源已经到手了,后续就是任务调度的范畴。任务调度课程中也有详细的介绍,老弟可以关注下~ 大概其就是这么些关系,不知道对老弟是否有所帮助~
2021-11-08420- Geek_2dfa9a置顶1. collect,触发action返回全部组分区里的数据,results是个数组类型的数组,最后在把这些数组合并。 因为所有数据都会被加载到driver,所以建议只在数据量少的时候使用。源码如下: /** * Return an array that contains all of the elements in this RDD. * * @note This method should only be used if the resulting array is expected to be small, as * all the data is loaded into the driver's memory. */ def collect(): Array[T] = withScope { val results = sc.runJob(this, (iter: Iterator[T]) => iter.toArray) Array.concat(results: _*) } take代码太长就不发了,注释上说是先取一个分区,然后根据取到的数量预估出还需要取多少个分区。 和collect一样,建议只在数据量少的时候使用。如果rdd里有Nothing和Null的话,会抛出异常。 具体实现: 先尝试从第一个分区0开始collet数据, 如果返回数量为0的话,每次都拉已扫描分区数4倍的分区数(可以通过spark.rdd.limit.scaleUpFactor参数设置,默认值为4), 如果返回数量大于0但是还不够需要take的数量的话,从已扫描分区数4倍的分区数和已扫描分区数预估一个需要扫描分区数(1.5*剩余需要take的数据数*已扫描分区数/已取到的数据数,然后向上取整)选一个最小值 一直到拿到take数据数/全部分区都取完。 /** * Take the first num elements of the RDD. It works by first scanning one partition, and use the * results from that partition to estimate the number of additional partitions needed to satisfy * the limit. * * @note This method should only be used if the resulting array is expected to be small, as * all the data is loaded into the driver's memory. * * @note Due to complications in the internal implementation, this method will raise * an exception if called on an RDD of `Nothing` or `Null`. */ 2.使用了yarn,没有使用standalone所以也没啥生产经验,简单看了下官方部署文档: 首先需要关注安全问题,SparkRpc的身份验证和加密,本地文件(shuffle)的加密,SparkUI的安全(身份验证,https,其他web安全) Event Logging和访问,客户端模式下的持久化日志的权限 然后是高可用,spark的worker是支持高可用的,master是通过zk实现的
作者回复: 满分!满分!💯,Perfect! 太赞了,目前最棒的答案! collect和take的分析,尤其到位,尤其是take的部分!我跟编辑打个招呼,把你的答案置顶~
2021-09-17334 - pythonbug老师好,有一个地方一直不懂,textFile算子是在excutor端执行的吗?那岂不是每个excutor都会先读取整个文件
作者回复: 是在Executors端执行的,但是,每个Executors只读取文件的一部分~ 可以结合后面会讲的调度系统,来理解这一点~
2021-10-059  GAC·DU1、collect()方法回把RDD所有的元素返还给Driver端,并在Driver端把数据序列成数组,如果数据量过大,会导致Driver端内存溢出,也会导致Driver进程奔溃。但是有个问题,既然collect方法有弊端,spark开发者为什么还要对用户提供它?难道还有别的什么特殊用户场景吗?请老师指点。 2、目前使用的是YARN进行任务调度,提交任务需要指定--master yarn 和 --deploy-mode [cluster | client]。 有个问题咨询老师,比如说wordCount的top5,take(5)是如何知道要从哪个executor提取想要的数据的?
GAC·DU1、collect()方法回把RDD所有的元素返还给Driver端,并在Driver端把数据序列成数组,如果数据量过大,会导致Driver端内存溢出,也会导致Driver进程奔溃。但是有个问题,既然collect方法有弊端,spark开发者为什么还要对用户提供它?难道还有别的什么特殊用户场景吗?请老师指点。 2、目前使用的是YARN进行任务调度,提交任务需要指定--master yarn 和 --deploy-mode [cluster | client]。 有个问题咨询老师,比如说wordCount的top5,take(5)是如何知道要从哪个executor提取想要的数据的?作者回复: 好问题~ 1. 满分💯,我理解,collect更多的是社区为开发者提供的一种能力或者说功能,就是Spark有能力把全量结果收集到Driver,但是坦白说,这种需求在工业级应用中并不多。但是Spark必须提供这种能力或者选项,以备开发者不时之需。换句话说,collect是鸡肋,食之无味,但是不能没有。 2. 我理解这是两个问题。先说Top5,再说take5,两个有着天壤之别。top5,其实就是全量数据之上的计算,先分组,再聚合,最后排序,这个不是从哪个Executors提取的,而是最后做归并排序(Global sort)的时候,按照大小个提取出来的,具体是哪个Executors,要看它是不是提供了top5的words。 再说take5,这个就有意思了。top5,暗含着的意思,就是数据一定需要排序,否则哪里有“top”的概念呢。但是take不一样,take,是“随便”拿5个。在咱们的word count示例中,假设没有sortByKey,直接用take(5),那么Spark在运行时的表现,会完全不一样。具体来说,因为是“随便”取5个,所以Spark会偷懒,不会去run全量数据,而是试探性地,去run几个小的job,这些job,只用部分数据,只要最终能取到5个值,“随便取5个”的目的就达到了,这其实是Spark对于first、take这类算子的一种优化~
2021-09-1748 coderzjh讲的真好懂,老师能不能更快点哈,从来没有像现在这样爱好学习
coderzjh讲的真好懂,老师能不能更快点哈,从来没有像现在这样爱好学习作者回复: 感谢老弟认可~ 这边更新进度是每周一三五哈~
2021-09-1726 A数据交换之后,所有相同的单词都分发到了相同的 Executors 上去; 老师这里我有个问题在任务执行的时候executor之间还会进行通信嘛? 任务分发完成之后每一个executor不就是按部就班的执行自己的任务嘛?我不需要去拉取别的executor中的数据我只需要计算我自己的就好,聚合 的时候由driver来完成就好(不过这点也说不过去因为driver不负责计算) 疑惑点就是executor怎么通过dag来让每个executor去不同的executor上拉取数据?每个executor是如何感知之前的stage生成的数据都存在哪里?(相同的单词)难不成处理完前一个stage后executor会像driver报道我本次处理完的数据放在哪里 麻烦老师给解答一下,或是提供个引子我去追一下spark源码 感谢老师!
A数据交换之后,所有相同的单词都分发到了相同的 Executors 上去; 老师这里我有个问题在任务执行的时候executor之间还会进行通信嘛? 任务分发完成之后每一个executor不就是按部就班的执行自己的任务嘛?我不需要去拉取别的executor中的数据我只需要计算我自己的就好,聚合 的时候由driver来完成就好(不过这点也说不过去因为driver不负责计算) 疑惑点就是executor怎么通过dag来让每个executor去不同的executor上拉取数据?每个executor是如何感知之前的stage生成的数据都存在哪里?(相同的单词)难不成处理完前一个stage后executor会像driver报道我本次处理完的数据放在哪里 麻烦老师给解答一下,或是提供个引子我去追一下spark源码 感谢老师!作者回复: 其实这里需要理解Shuffle的过程哈~ 老弟可以关注后面Shuffle的部分。 1)dag解析,拆分stages,分发tasks,这些全部由driver来做,如你所言,Executors只负责计算, 2)在一个stage内部,各个Executors确实仅仅是做好自己的分内事,大家专注地执行自己的任务 3)但是,在shuffle阶段,所有Executors,都需要跨节点,去访问其他所有Executors的shuffle中间文件,这部分我们在shuffle会讲。而shuffle中间文件,是存储在spark.local.dir这个配置项所配置的本地目录的。也就是每个Executors都知道,去各个节点的这个目录下面去找。至于说,每个Executors怎么知道该获取数据的哪部分,这就还要说回shuffle中间文件,它包含data和index两部分,index会标记,每个reduce task去获取哪部分数据。 总的来说,老弟的问题,实际上是关于shuffle的,可以特别去关注那一part哈
2022-01-135 Abigail分享的经验:工作后一开始接触分布式计算时,直接上手的就是在 Azure/AWS/GCP 利用 DataBricks 进行数据分析处理和建模,感觉自己直接跳过了很多关于 Spark 基础的东西,关于如何部署Spark系统更是没有动手经验,平时就是 Create Cluster 然后一路点下去,或启动之前配置好的 Cluster,遇到门槛直接找 IT 或 DataBricks 的技术服务就解决了。不知道会不会影响自己未来技术积累和事业发展……心里小小慌张一下,不过目前大概是知道怎么个流程了,不是那么慌了。 在我看来这个“零基础”入门Spark其实不是很零基础~还是有一定的门槛的。 吴老师能否考虑稍后出一个基于Spark项目实战技术的教程,配上辅助的代码和教程,这样和这个基础入门结合起来会更受欢迎的!
Abigail分享的经验:工作后一开始接触分布式计算时,直接上手的就是在 Azure/AWS/GCP 利用 DataBricks 进行数据分析处理和建模,感觉自己直接跳过了很多关于 Spark 基础的东西,关于如何部署Spark系统更是没有动手经验,平时就是 Create Cluster 然后一路点下去,或启动之前配置好的 Cluster,遇到门槛直接找 IT 或 DataBricks 的技术服务就解决了。不知道会不会影响自己未来技术积累和事业发展……心里小小慌张一下,不过目前大概是知道怎么个流程了,不是那么慌了。 在我看来这个“零基础”入门Spark其实不是很零基础~还是有一定的门槛的。 吴老师能否考虑稍后出一个基于Spark项目实战技术的教程,配上辅助的代码和教程,这样和这个基础入门结合起来会更受欢迎的!作者回复: 感谢老弟提供的建议~ 和《入门篇》配套,还有一个《调优篇》:Spark性能调优实战,那门课里面更针对性能优化一些,里面的案例也更丰富,不知道是不是老弟想要的内容~
2021-11-1824
 一期一会有个问题麻烦老师回答:在咱们的word count示例中的take(5)前面运行了sortByKey(false), 那是不是各分区在分区内部做了排序,而不是所有分区进行了归并排序呢?然后take(5)就是返回各分区中取排序前几个的,最后凑出来5个结果呢?也就是说,如果各分区自己排序然后给出结果并汇总,那take(5)的结果,并不一定是全局中出现频率最高的5个单词?
一期一会有个问题麻烦老师回答:在咱们的word count示例中的take(5)前面运行了sortByKey(false), 那是不是各分区在分区内部做了排序,而不是所有分区进行了归并排序呢?然后take(5)就是返回各分区中取排序前几个的,最后凑出来5个结果呢?也就是说,如果各分区自己排序然后给出结果并汇总,那take(5)的结果,并不一定是全局中出现频率最高的5个单词?作者回复: 好问题,sortByKey其实是先shuffle,然后再merge sort,也就是: 1)Executors局部sort 2)用merge sort挑选出前5个 先shuffle,其实就保证了key一样的records,被shuffle到同一节点,这样全局再做sort的时候,就不会出现你说的局部与全局不一致的情况
2022-01-183- Abigail吴老师能否出一个更为详细一点的spark在AWS EC2上部署的note,我在AWS上尝试了一遍, 选的也是centOS7,最好好不容易把环境设置好了,在运行最后一个例子时, 又出现了一个bug如下。本人非IT需要手把手的带一遍。 [centos@ip-172-31-40-xxxx spark_latest]$ MASTER=spark://node0:7077 $SPARK_HOME/bin/run-example org.apache.spark.examples.SparkPi WARNING: An illegal reflective access operation has occurred WARNING: Illegal reflective access by org.apache.spark.unsafe.Platform (file:/opt/spark/spark-3.1.2-bin-hadoop3.2/jars/spark-unsafe_2.12-3.1.2.jar) to constructor java.nio.DirectByteBuffer(long,int) WARNING: Please consider reporting this to the maintainers of org.apache.spark.unsafe.Platform WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations WARNING: All illegal access operations will be denied in a future release Exception in thread "main" org.apache.spark.SparkException: Master must either be yarn or start with spark, mesos, k8s, or local
作者回复: Exception in thread "main" org.apache.spark.SparkException: Master must either be yarn or start with spark, mesos, k8s, or local。 从报错来看,Master没有设置好,老弟看下Master的spark-defaults.conf文件,可以把文件内容贴出来,一起看看,或者你加我微信也行,“方块K”或者“rJunior”。环境的配置确实比较麻烦,哪一步稍有不对,可能就跑不起来,加微信一起看看吧。 确认下,无密码SSH没问题是吧?不同节点jps一下,看看Master和Worker是不是成功启动了,再有,用spark-shell --master spark://node0:7077,试一下Master是不是ready的,先看看spark-shell能不能起来
2021-11-231  钱鹏 Allen吴老师的进程模型讲得易于理解, 各种RDD的算子计算,我们带入到日常的生活场景里去理解。Driver和Executor,包工头和工人的比喻。 期待老师的后续课程~
钱鹏 Allen吴老师的进程模型讲得易于理解, 各种RDD的算子计算,我们带入到日常的生活场景里去理解。Driver和Executor,包工头和工人的比喻。 期待老师的后续课程~作者回复: 感谢老弟的认可~ 嗯嗯,后面继续加油~
2021-09-181

