

33丨PageRank(下):分析希拉里邮件中的人物关系
该思维导图由 AI 生成,仅供参考
如何使用工具实现 PageRank 算法
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

本文介绍了如何使用Python中的NetworkX工具包实现PageRank算法,并结合希拉里邮件中的人物关系案例进行详细讲解。文章首先介绍了如何创建有向图,并通过PageRank函数计算节点的PR值。随后,详细讲解了如何加载数据源、进行数据清洗和准备阶段,以及如何使用PageRank算法挖掘有影响力的节点,并绘制网络图。最后,文章提供了代码示例,展示了如何通过PageRank算法揭秘希拉里邮件中的人物关系,并对创建好的网络图进行可视化。整篇文章结合实际案例,详细介绍了PageRank算法的实际应用,为读者提供了一种快速了解和实践PageRank算法的方法。文章还提到了使用NetworkX工具的方法,包括创建图、节点、边及PR值的计算。同时,作者还分享了在实际项目中使用PageRank算法的经验和注意事项。
《数据分析实战 45 讲》,新⼈⾸单¥59

全部留言(18)
- 最新
- 精选
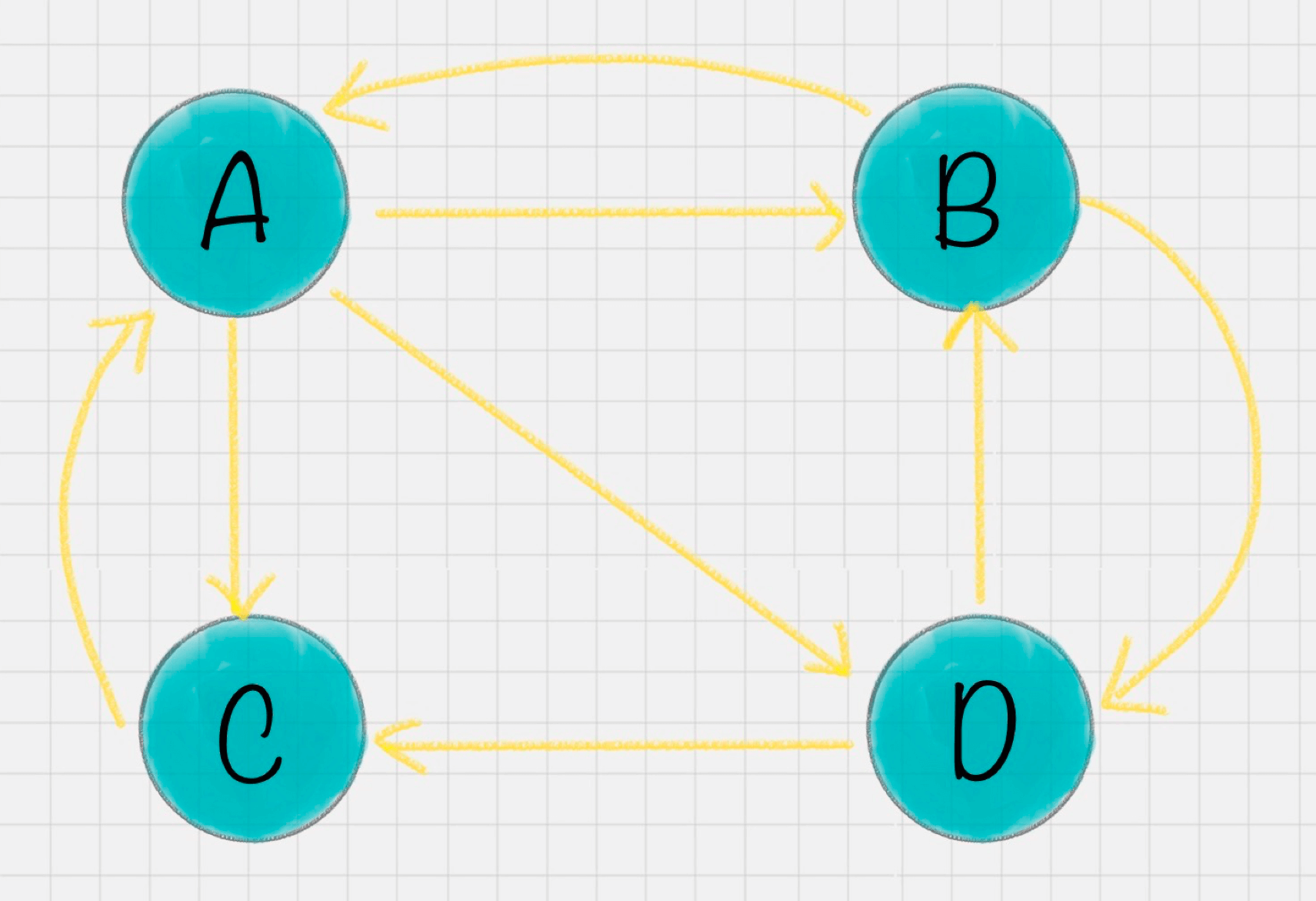
 thirdpagerank 值是: {'C': 0.22514635472743896, 'A': 0.3245609358176832, 'D': 0.22514635472743894, 'B': 0.22514635472743896} import networkx as nx # 创建有向图 G = nx.DiGraph() # 有向图之间边的关系 edges = [("A", "B"), ("A", "C"), ("A", "D"), ("B", "A"), ("B", "D"), ("C", "A"), ("D", "B"), ("D", "C")] for edge in edges: G.add_edge(edge[0], edge[1]) pagerank_list = nx.pagerank(G, alpha=0.85) print("pagerank 值是:", pagerank_list)
thirdpagerank 值是: {'C': 0.22514635472743896, 'A': 0.3245609358176832, 'D': 0.22514635472743894, 'B': 0.22514635472743896} import networkx as nx # 创建有向图 G = nx.DiGraph() # 有向图之间边的关系 edges = [("A", "B"), ("A", "C"), ("A", "D"), ("B", "A"), ("B", "D"), ("C", "A"), ("D", "B"), ("D", "C")] for edge in edges: G.add_edge(edge[0], edge[1]) pagerank_list = nx.pagerank(G, alpha=0.85) print("pagerank 值是:", pagerank_list)编辑回复: 正确。
2019-02-277 永降不息之雨老师关于希拉里邮件的案例,这一段一直看不懂。 我print(temp)只有得到两个人名, 但是我print(edges_weights_temp)后 除了人名,后面还多了一个数字, 老师这数字是怎么来的,这段语法能帮忙解释一下吗? temp=(rew[0],row[1]) if temp not in edges_weights_temp: edges_weights_temp[temp] = 1 else: edges_weights_temp[temp] = edges_weights_temp[temp] + 1
永降不息之雨老师关于希拉里邮件的案例,这一段一直看不懂。 我print(temp)只有得到两个人名, 但是我print(edges_weights_temp)后 除了人名,后面还多了一个数字, 老师这数字是怎么来的,这段语法能帮忙解释一下吗? temp=(rew[0],row[1]) if temp not in edges_weights_temp: edges_weights_temp[temp] = 1 else: edges_weights_temp[temp] = edges_weights_temp[temp] + 1编辑回复: 我在程序里保存边(发送者->接受者)的权重的代码: for row in zip(emails.MetadataFrom, emails.MetadataTo, emails.RawText): temp = (row[0], row[1]) if temp not in edges_weights_temp: edges_weights_temp[temp] = 1 else: edges_weights_temp[temp] = edges_weights_temp[temp] + 1 如果你print(edges_weights_temp)应该是类似这样的结果: {('Jake Sullivan', 'Hillary Clinton'): 815, ('nan', 'Hillary Clinton'): 20, ('Cheryl Mills', ';h'): 1, ... 这里('Jake Sullivan', 'Hillary Clinton') 就是我们的temp,也就(row[0], row[1]),也就是保存的发送者->接收者的次数,次数为815次。 if temp not in edges_weights_temp 判断下在字典edges_weights_temp中是否已经存在了边temp,如果没有存在就创建一个,赋值为1,也就是代表他们通信了1次。如果存在了,就找出来当时的次数,然后+1
2019-07-0345 szm有2个问题: 第一个:pagerank已经是字典类型了,为什么还要用pagerank_list = {node: rank for node, rank in pagerank.items()}将其转换为字典呢?是不是删掉这个语句也没关系? 第二个:阈值大于0.005的图仍有很多重叠在一起,无法观看,请问怎样才能让画出来的图像美观呢?
szm有2个问题: 第一个:pagerank已经是字典类型了,为什么还要用pagerank_list = {node: rank for node, rank in pagerank.items()}将其转换为字典呢?是不是删掉这个语句也没关系? 第二个:阈值大于0.005的图仍有很多重叠在一起,无法观看,请问怎样才能让画出来的图像美观呢?编辑回复: 第一个问题:对的,pagerank是字典类型,直接使用nx.set_node_attributes(graph, name = 'pagerank', values=pagerank)是OK的 第二个问题,阈值大于0.005时,很多图重叠在一起,可以采用nx.circular_layout(graph)来进行显示。这样可以让筛选出来的点都分布到一个圆上,来显示出来他们之间的关系。
2019-03-044 WS老师,怎么筛选出某个人物的有向图?
WS老师,怎么筛选出某个人物的有向图?作者回复: 你可以通过 graph.edges取出所有的边,然后对所有边进行遍历查找
2019-08-052 mickeyimport networkx as nx # 创建有向图 G = nx.DiGraph() # 有向图之间边的关系 edges = [("A", "B"), ("A", "C"), ("A", "D"), ("B", "A"), ("B", "D"), ("C", "A"), ("D", "B"), ("D", "C")] for edge in edges: G.add_edge(edge[0], edge[1]) pagerank_list = nx.pagerank(G) #alpha为阻尼因子,默认值:0.85 print("pagerank值是:", pagerank_list) pagerank值是: {'A': 0.3245609358176831, 'B': 0.22514635472743894, 'C': 0.22514635472743894, 'D': 0.22514635472743894}
mickeyimport networkx as nx # 创建有向图 G = nx.DiGraph() # 有向图之间边的关系 edges = [("A", "B"), ("A", "C"), ("A", "D"), ("B", "A"), ("B", "D"), ("C", "A"), ("D", "B"), ("D", "C")] for edge in edges: G.add_edge(edge[0], edge[1]) pagerank_list = nx.pagerank(G) #alpha为阻尼因子,默认值:0.85 print("pagerank值是:", pagerank_list) pagerank值是: {'A': 0.3245609358176831, 'B': 0.22514635472743894, 'C': 0.22514635472743894, 'D': 0.22514635472743894}作者回复: Good Job
2019-03-052 王彬成1、pagerank_list=nx.pagerank(G,alpha=1)理解 参考链接:https://networkx.github.io/documentation/networkx-1.10/reference/generated/networkx.algorithms.link_analysis.pagerank_alg.pagerank.html alpha指的是阻尼因子。根据公式了解到,这因子代表用户按照跳转链接来上网的概率。 题目说15%的概率随机跳转,所以阻尼因子为0.85 2、代码 import networkx as nx # 创建有向图 G=nx.DiGraph() # 有向图之间边的关系 edges = [("A", "B"), ("A", "C"), ("A", "D"), ("B", "A"), ("B", "D"), ("C", "A"), ("D", "B"), ("D", "C")] for edge in edges: G.add_edge(edge[0],edge[1]) pagerank_list=nx.pagerank(G,alpha=0.85) print('pagerank 值是: ', pagerank_list) 3、结果 pagerank 值是: {'A': 0.3245609358176831, 'B': 0.22514635472743894, 'C': 0.22514635472743894, 'D': 0.22514635472743894}
王彬成1、pagerank_list=nx.pagerank(G,alpha=1)理解 参考链接:https://networkx.github.io/documentation/networkx-1.10/reference/generated/networkx.algorithms.link_analysis.pagerank_alg.pagerank.html alpha指的是阻尼因子。根据公式了解到,这因子代表用户按照跳转链接来上网的概率。 题目说15%的概率随机跳转,所以阻尼因子为0.85 2、代码 import networkx as nx # 创建有向图 G=nx.DiGraph() # 有向图之间边的关系 edges = [("A", "B"), ("A", "C"), ("A", "D"), ("B", "A"), ("B", "D"), ("C", "A"), ("D", "B"), ("D", "C")] for edge in edges: G.add_edge(edge[0],edge[1]) pagerank_list=nx.pagerank(G,alpha=0.85) print('pagerank 值是: ', pagerank_list) 3、结果 pagerank 值是: {'A': 0.3245609358176831, 'B': 0.22514635472743894, 'C': 0.22514635472743894, 'D': 0.22514635472743894}编辑回复: 结果正确,对alpha阻尼因子的理解也正确
2019-03-012 白夜默认阻尼就是0.85,alpha去掉完事、、 pagerank 值是: {'A': 0.3245609358176831, 'B': 0.22514635472743894, 'C': 0.22514635472743894, 'D': 0.22514635472743894}
白夜默认阻尼就是0.85,alpha去掉完事、、 pagerank 值是: {'A': 0.3245609358176831, 'B': 0.22514635472743894, 'C': 0.22514635472743894, 'D': 0.22514635472743894}编辑回复: 这样使用最方便,alpha默认是0.85
2019-02-272 小晨#!/usr/bin/env python # -*- coding:utf-8 -*- # Author:Peter import networkx as nx import matplotlib.pyplot as plt def show_graph(graph): # 使用Sprint Layout布局,类似中心放射状 positions = nx.spring_layout(graph) # 设置网格图中的节点大小,大小与pagerank无关,因为pagerank值很小所以需要*20000 nodesize = [x['pagerank'] * 20000 for v , x in graph.nodes(data=True)] # 设置网络图中的边长度 # edgesize = [np.sqrt(e[2]['weight']) for e in graph.edges(data=True)] # 绘制节点 nx.draw_networkx_nodes(graph , positions , node_size=nodesize , alpha=0.4) # 绘制边 nx.draw_networkx_edges(graph , positions , alpha=0.2) # 绘制节点的 label nx.draw_networkx_labels(graph , positions , font_size=10) #所有人物关系的关系图 plt.show() # 创建有向图 G = nx.DiGraph() # 有向图之间边的关系 edges = [("A", "B"), ("A", "C"), ("A", "D"), ("B", "A"), ("B", "D"), ("C", "A"), ("D", "B"), ("D", "C")] for edge in edges: G.add_edge(edge[0],edge[1]) pagerank = nx.pagerank(G) print('Pagerank值:',pagerank) # 获取每个节点的pagerank数值 pagerank_list = {node: rank for node, rank in pagerank.items()} # 将 pagerank 数值作为节点的属性 nx.set_node_attributes(G, name = 'pagerank', values = pagerank) # 画网络图 show_graph(G)
小晨#!/usr/bin/env python # -*- coding:utf-8 -*- # Author:Peter import networkx as nx import matplotlib.pyplot as plt def show_graph(graph): # 使用Sprint Layout布局,类似中心放射状 positions = nx.spring_layout(graph) # 设置网格图中的节点大小,大小与pagerank无关,因为pagerank值很小所以需要*20000 nodesize = [x['pagerank'] * 20000 for v , x in graph.nodes(data=True)] # 设置网络图中的边长度 # edgesize = [np.sqrt(e[2]['weight']) for e in graph.edges(data=True)] # 绘制节点 nx.draw_networkx_nodes(graph , positions , node_size=nodesize , alpha=0.4) # 绘制边 nx.draw_networkx_edges(graph , positions , alpha=0.2) # 绘制节点的 label nx.draw_networkx_labels(graph , positions , font_size=10) #所有人物关系的关系图 plt.show() # 创建有向图 G = nx.DiGraph() # 有向图之间边的关系 edges = [("A", "B"), ("A", "C"), ("A", "D"), ("B", "A"), ("B", "D"), ("C", "A"), ("D", "B"), ("D", "C")] for edge in edges: G.add_edge(edge[0],edge[1]) pagerank = nx.pagerank(G) print('Pagerank值:',pagerank) # 获取每个节点的pagerank数值 pagerank_list = {node: rank for node, rank in pagerank.items()} # 将 pagerank 数值作为节点的属性 nx.set_node_attributes(G, name = 'pagerank', values = pagerank) # 画网络图 show_graph(G)作者回复: 代码正确!建议按照Python PEP8规范书写代码,对未来的工作很有用哦
2021-02-2621 小匚老师好,我在跑的时候发现提示没有这个 edge_size 参数,我直接去掉了也跑出了和文章中相同的结果。nx.draw_networkx_edges(graph, positions, alpha=0.2)
小匚老师好,我在跑的时候发现提示没有这个 edge_size 参数,我直接去掉了也跑出了和文章中相同的结果。nx.draw_networkx_edges(graph, positions, alpha=0.2)作者回复: 之所以报错,是因为networkx版本更新后,更改了一部分参数的名称,比如:edge_size参数更名为nodelist。可以更改为nodelist参数,或者降低networkx的版本,比如:2.4版本,edge_size就不会报错了。
2021-02-201 等待老师您好,想询问以下就是,在分析希拉里的邮件人物关系的过程中,阻尼因子为0.85是什么意思呢?什么情况之下才要阻尼因子为1呢? 麻烦老师了
等待老师您好,想询问以下就是,在分析希拉里的邮件人物关系的过程中,阻尼因子为0.85是什么意思呢?什么情况之下才要阻尼因子为1呢? 麻烦老师了作者回复: 阻尼因子d通常默认取值为0.85,d=1时模型退化为PageRank简化模型
2020-03-3031

