

13 | 数据变换:考试成绩要求正态分布合理么?
陈旸

该思维导图由 AI 生成,仅供参考
上一讲中我给你讲了数据集成,今天我来讲下数据变换。
如果一个人在百分制的考试中得了 95 分,你肯定会认为他学习成绩很好,如果得了 65 分,就会觉得他成绩不好。如果得了 80 分呢?你会觉得他成绩中等,因为在班级里这属于大部分人的情况。
为什么会有这样的认知呢?这是因为我们从小到大的考试成绩基本上都会满足正态分布的情况。什么是正态分布呢?正态分布也叫作常态分布,就是正常的状态下,呈现的分布情况。
比如你可能会问班里的考试成绩是怎样的?这里其实指的是大部分同学的成绩如何。以下图为例,在正态分布中,大部分人的成绩会集中在中间的区域,少部分人处于两头的位置。正态分布的另一个好处就是,如果你知道了自己的成绩,和整体的正态分布情况,就可以知道自己的成绩在全班中的位置。
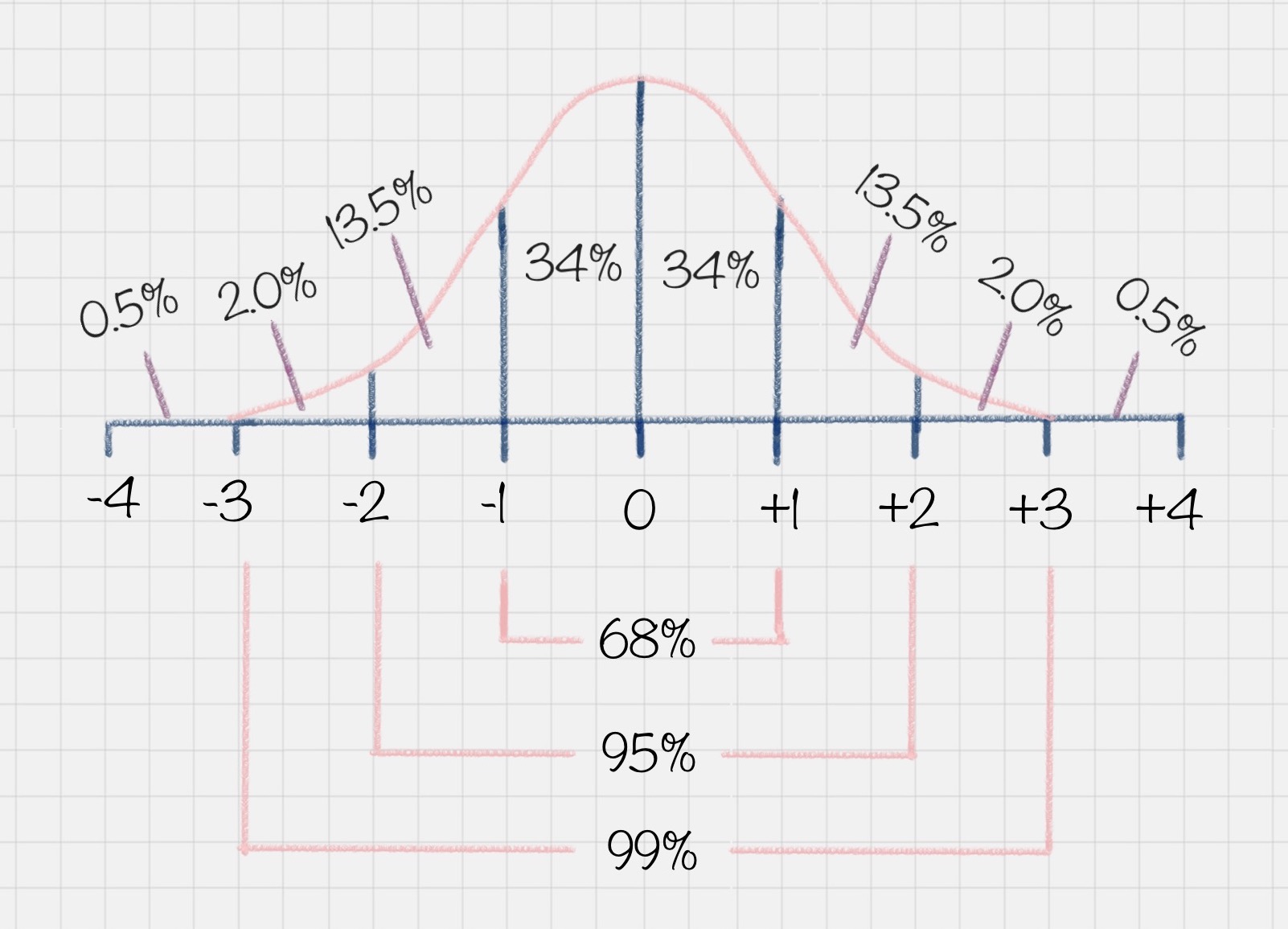
另一个典型的例子就是,美国 SAT 考试成绩也符合正态分布。而且美国本科的申请,需要中国高中生的 GPA 在 80 分以上(百分制的成绩),背后的理由也是默认考试成绩属于正态分布的情况。
为了让成绩符合正态分布,出题老师是怎么做的呢?他们通常可以把考题分成三类:
第一类:基础题,占总分 70%,基本上属于送分题;
第二类:灵活题,基础范围内 + 一定的灵活性,占 20%;
第三类:难题,涉及知识面较广的难题,占 10%;
公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结

数据变换在数据分析中扮演着重要角色,本文深入浅出地介绍了数据变换的重要性和具体应用方法。首先讨论了正态分布对考试成绩的影响,以及出题老师如何调整试题以满足正态分布的情况。接着详细讨论了数据变换在数据准备中的重要性,包括数据平滑、聚集、概化和规范化等方法。其中,对数据规范化的几种方法进行了详细介绍,包括Min-max规范化、Z-Score规范化和小数定标规范化。文章以Python的SciKit-Learn库为例,展示了如何使用该库进行数据规范化。值得注意的是,数据挖掘中数据变换比算法选择更重要,因为数据变换能够让数据满足一定的规律,达到规范性的要求,便于进行挖掘。最后,文章提出了思考题,引发读者思考和讨论。整体而言,本文内容丰富,涵盖了数据变换的重要性和实际应用,对于读者快速了解数据变换的概念和实践操作具有指导意义。
仅可试看部分内容,如需阅读全部内容,请付费购买文章所属专栏
《数据分析实战 45 讲》,新⼈⾸单¥59
《数据分析实战 45 讲》,新⼈⾸单¥59
立即购买
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
全部留言(53)
- 最新
- 精选
 跳跳一、16000的位置 (16000-5000)/(58000-5000)=0.2075 代码实现如下: # coding:utf-8 from sklearn import preprocessing import numpy as np # 初始化数据,每一行表示一个样本,每一列表示一个特征 x = np.array([[5000.],[16000.],[58000.]]) # 将数据进行 [0,1] 规范化 min_max_scaler = preprocessing.MinMaxScaler() minmax_x = min_max_scaler.fit_transform(x) print(minmax_x) 输出: [[0. ] [0.20754717] [1. ]] 二、关于规范化方法 1.min-max:将数据归一化到[0,1]区间 2.z-score:将数据规范到0均值,1方差的标准正态分布上,减少老师说的百分制80和500分制80的数据值差异问题 3.小数定标规范化:将数据转化为[-1,1]区间中
跳跳一、16000的位置 (16000-5000)/(58000-5000)=0.2075 代码实现如下: # coding:utf-8 from sklearn import preprocessing import numpy as np # 初始化数据,每一行表示一个样本,每一列表示一个特征 x = np.array([[5000.],[16000.],[58000.]]) # 将数据进行 [0,1] 规范化 min_max_scaler = preprocessing.MinMaxScaler() minmax_x = min_max_scaler.fit_transform(x) print(minmax_x) 输出: [[0. ] [0.20754717] [1. ]] 二、关于规范化方法 1.min-max:将数据归一化到[0,1]区间 2.z-score:将数据规范到0均值,1方差的标准正态分布上,减少老师说的百分制80和500分制80的数据值差异问题 3.小数定标规范化:将数据转化为[-1,1]区间中作者回复: Good Job
2019-01-11341- 锦水春风老师,你好: 随着学习的不断加深,许多内容需要掌握理解或者编码测试,每个人多少都有疑难问题,如不能及时解决势必影响学习效果。建议对上课人员建立交流QQ群,有些问题可以互相交流学习,对仍有问题的老师可亲自回答。
作者回复: 咱们有微信群的,可以让运营同学拉你进群
2019-01-133437  林有时候数据变换比算法选择更重要,数据错了,算法再正确也错的。这就是为什么数据分析师80%的时间会花在前期的数据准备上了。 #数据挖掘前的准备工作 在数据变换前,需要对数据进行筛选,然后进行数据探索和相关性分析,接着选择算法模型,然后针对算法模型对数据进行数据变换,从而完成数据挖掘前的准备工作。 #数据变换的四种常见方法 1、数据平滑 去除数据噪声,将连续数据离散化。主要是用分箱、聚类和回归方式等算法进行数据平滑。 2、数据聚集 个人理解就是对数据聚合。 对数据进行汇总,比如常见的使用sql的聚合函数。 3、数据概化 个人理解就是数据维度抽象。 将数据由较低的概念抽象成为较高的概念,减少数据复杂度,即用更高的概念替代更低的概念。比如说上海、杭州、深圳、北京可以概化为中国。 4、数据规范化 常用方法:min-max规范化、Z-score规范化、按小数定标规范化。 5、属性构造 人个理解就是根据需要加字段。 #数据规范化的几种方法 1、Min-Max规范化 将原始数据变换到[0,1]的空间中。 公式:新数值=(原数值-极小值)/(极大值-极小值) 2、Z-score规范化 对不同级别的数据按相同标准来进行比较。 公式: 新数值 = (原数值-均值)/标准差 3、小数定标规范化 不知道作用是干啥? #Python 的 SciKit-Learn 库 是一个机器学习库,封装了大量的机器学习算法,比如分类、聚类、回归、降维等。另外,它还包括了上面说的数据变换模块。
林有时候数据变换比算法选择更重要,数据错了,算法再正确也错的。这就是为什么数据分析师80%的时间会花在前期的数据准备上了。 #数据挖掘前的准备工作 在数据变换前,需要对数据进行筛选,然后进行数据探索和相关性分析,接着选择算法模型,然后针对算法模型对数据进行数据变换,从而完成数据挖掘前的准备工作。 #数据变换的四种常见方法 1、数据平滑 去除数据噪声,将连续数据离散化。主要是用分箱、聚类和回归方式等算法进行数据平滑。 2、数据聚集 个人理解就是对数据聚合。 对数据进行汇总,比如常见的使用sql的聚合函数。 3、数据概化 个人理解就是数据维度抽象。 将数据由较低的概念抽象成为较高的概念,减少数据复杂度,即用更高的概念替代更低的概念。比如说上海、杭州、深圳、北京可以概化为中国。 4、数据规范化 常用方法:min-max规范化、Z-score规范化、按小数定标规范化。 5、属性构造 人个理解就是根据需要加字段。 #数据规范化的几种方法 1、Min-Max规范化 将原始数据变换到[0,1]的空间中。 公式:新数值=(原数值-极小值)/(极大值-极小值) 2、Z-score规范化 对不同级别的数据按相同标准来进行比较。 公式: 新数值 = (原数值-均值)/标准差 3、小数定标规范化 不知道作用是干啥? #Python 的 SciKit-Learn 库 是一个机器学习库,封装了大量的机器学习算法,比如分类、聚类、回归、降维等。另外,它还包括了上面说的数据变换模块。作者回复: Good Job
2019-01-1122 一个射手座的程序猿老师你好,这是后续报错: from numpy import show_config as show_numpy_config ImportError: cannot import name 'show_config' from 'numpy' (C:\Users\沐瑾\PycharmProjects\pythonProject\venv\numpy.py) 进程已结束,退出代码为 1 下载sklearn包时,出现的报错: ERROR:could not install packages due to an OSError:[winError 5] 拒绝访问:’C:\\Users\\沐瑾\\AppDate\\Local\\PythonSoftwareFoundation.Python.3.8_qbz5nzkfra8p0\\Loca]cache\\local-packages\\Python38\\site-packahes\\skilearn\\.linbs\\vcomp140.d11’
一个射手座的程序猿老师你好,这是后续报错: from numpy import show_config as show_numpy_config ImportError: cannot import name 'show_config' from 'numpy' (C:\Users\沐瑾\PycharmProjects\pythonProject\venv\numpy.py) 进程已结束,退出代码为 1 下载sklearn包时,出现的报错: ERROR:could not install packages due to an OSError:[winError 5] 拒绝访问:’C:\\Users\\沐瑾\\AppDate\\Local\\PythonSoftwareFoundation.Python.3.8_qbz5nzkfra8p0\\Loca]cache\\local-packages\\Python38\\site-packahes\\skilearn\\.linbs\\vcomp140.d11’作者回复: 调用numpy报的错,先检查你当前pycharm路径下,是否有同名numpy.py的文件,把它的名字改掉;如果还是报同样的错,则降低下numpy版本。 安装sklearn报错应该是权限问题,试试pip install --user scikit-learn
2021-04-071 夕子1、16000经过min-max规范化以后是:(16000-5000)/(58000-5000)=0.2075 代码: from sklearn import preprocessing import numpy as np x = np.array([[16000],[5000],[58000]]) min_max_scaler = preprocessing.MinMaxScaler() minmax_x = min_max_scaler.fit_transform(x) minmax_x 2、数据规范化的方法: ①min-max规范化 ②z-score规范化 ③小数定标规范化
夕子1、16000经过min-max规范化以后是:(16000-5000)/(58000-5000)=0.2075 代码: from sklearn import preprocessing import numpy as np x = np.array([[16000],[5000],[58000]]) min_max_scaler = preprocessing.MinMaxScaler() minmax_x = min_max_scaler.fit_transform(x) minmax_x 2、数据规范化的方法: ①min-max规范化 ②z-score规范化 ③小数定标规范化作者回复: 回答正确!!!很棒
2021-03-151 王钰有些问题可以自己先百度一下,简单了解下函数的用法,不影响继续阅读就可以了
王钰有些问题可以自己先百度一下,简单了解下函数的用法,不影响继续阅读就可以了作者回复: 嗯嗯
2019-03-111 杰之7通过这一节的阅读学习,对数据的转换有了更全面的整理。数据工程师大多数的工作内容也是在处理数据清洗,集成和转换的内容。数据质量能直接影响到后续的算法建模的好坏。 对于常见的变换,有数据平滑、聚集、概化、规范化、属性构造等方法,老师在文章中主要讲述来了规范化的3种方法,Min_max规范化,Z_score,小数立标规范化,并在sklearn中加已了实现。
杰之7通过这一节的阅读学习,对数据的转换有了更全面的整理。数据工程师大多数的工作内容也是在处理数据清洗,集成和转换的内容。数据质量能直接影响到后续的算法建模的好坏。 对于常见的变换,有数据平滑、聚集、概化、规范化、属性构造等方法,老师在文章中主要讲述来了规范化的3种方法,Min_max规范化,Z_score,小数立标规范化,并在sklearn中加已了实现。作者回复: 加油~
2019-02-111 McKee Chen属性 income 的 16000 元将被转化为0.207547 #Min-max规范化 from sklearn import preprocessing import numpy as np #初始化数据,每一行代表一个样本,每一列代表一个特征 x = np.array([[5000,0],[16000,0],[58000,0]]) #将数据进行[0,1]规范化 min_max_scaler = preprocessing.MinMaxScaler() minmax_x = min_max_scaler.fit_transform(x) minmax_x 1.Min-max规范方法是将原始数据变换到[0,1]的空间中,公式为:新数值=(原数值-极小值)/(极大值-极小值) 2.Z-score规范化公式为:新数值=(原数值-均值)/标准差,将数据集进行了规范化,数值都符合均值为0,方差为1的正态分布 3.小数定标规范化通过移动小数点的位置来进行规范化,小数点移动的位数取决于数值最大绝对值 以前常用的是Min-Max规范化、Z-Score规范化,本次课程让我学到了新的规范方法 课后还需自己多琢磨,多练习
McKee Chen属性 income 的 16000 元将被转化为0.207547 #Min-max规范化 from sklearn import preprocessing import numpy as np #初始化数据,每一行代表一个样本,每一列代表一个特征 x = np.array([[5000,0],[16000,0],[58000,0]]) #将数据进行[0,1]规范化 min_max_scaler = preprocessing.MinMaxScaler() minmax_x = min_max_scaler.fit_transform(x) minmax_x 1.Min-max规范方法是将原始数据变换到[0,1]的空间中,公式为:新数值=(原数值-极小值)/(极大值-极小值) 2.Z-score规范化公式为:新数值=(原数值-均值)/标准差,将数据集进行了规范化,数值都符合均值为0,方差为1的正态分布 3.小数定标规范化通过移动小数点的位置来进行规范化,小数点移动的位数取决于数值最大绝对值 以前常用的是Min-Max规范化、Z-Score规范化,本次课程让我学到了新的规范方法 课后还需自己多琢磨,多练习作者回复: 继续坚持!
2020-10-13- lemonlxnStandardScaler 相比 z-score 可能要好些,可以将不同量级的数据,投射都 均值为0,标准差为1的正态分布中
作者回复: StandardScaler 就是z-score在sklearn中的API哦
2020-09-18  §mc²ompleXWr貌似规范化都是按列进行的(也就是以一个字段为单位)。那么可以按行,或者按照整体数据进行吗?如何操作呢?
§mc²ompleXWr貌似规范化都是按列进行的(也就是以一个字段为单位)。那么可以按行,或者按照整体数据进行吗?如何操作呢?作者回复: 需要每一列中进行规范化。因为每一列代表一个特征。
2020-05-07
收起评论

