

18丨决策树(中):CART,一棵是回归树,另一棵是分类树

该思维导图由 AI 生成,仅供参考
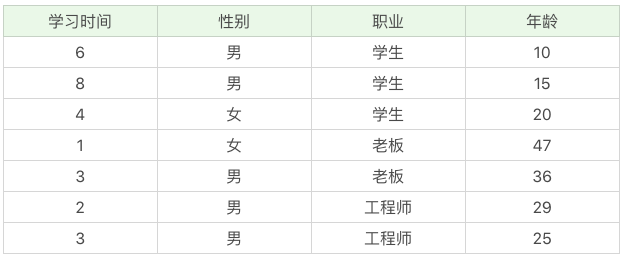
CART 分类树的工作流程
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

CART算法是一种灵活的决策树算法,既可用于分类树,也可用于回归树。在分类树中,CART算法使用基尼系数来评估属性的划分纯度,通过基尼系数对特征属性进行二元分裂,从而构建分类树。而在回归树中,CART算法使用最小二乘偏差(LSD)来评价不纯度,通过计算样本的离散程度来划分节点,得到连续值的预测结果。读者可以通过Python的sklearn库来实现CART分类树和回归树的构建和预测,使用DecisionTreeClassifier和DecisionTreeRegressor类即可轻松完成。文章详细介绍了CART算法的工作流程和使用方法,对于想要学习决策树算法的读者来说,是一篇值得阅读的技术文章。此外,文章还介绍了CART决策树的剪枝方法,即CCP方法,以及三种决策树在属性选择标准上的差异。文章以清晰的实例代码和运行结果展示了CART算法的使用方法和准确率,为读者提供了实践操作的指导。
《数据分析实战 45 讲》,新⼈⾸单¥59

全部留言(64)
- 最新
- 精选
 rainman置顶对于 CART 回归树的可视化,可以先在电脑上安装 graphviz;然后 pip install graphviz,这是安装python的库,需要依赖前面安装的 graphviz。可视化代码如下: ---- from sklearn.tree import export_graphviz import graphviz # 参数是回归树模型名称,不输出文件。 dot_data = export_graphviz(dtr, out_file=None) graph = graphviz.Source(dot_data) # render 方法会在同级目录下生成 Boston PDF文件,内容就是回归树。 graph.render('Boston') ---- 具体内容可以去 sklearn(https://scikit-learn.org/stable/modules/generated/sklearn.tree.export_graphviz.html) 和 graphviz(https://graphviz.readthedocs.io/en/stable/) 看看。
rainman置顶对于 CART 回归树的可视化,可以先在电脑上安装 graphviz;然后 pip install graphviz,这是安装python的库,需要依赖前面安装的 graphviz。可视化代码如下: ---- from sklearn.tree import export_graphviz import graphviz # 参数是回归树模型名称,不输出文件。 dot_data = export_graphviz(dtr, out_file=None) graph = graphviz.Source(dot_data) # render 方法会在同级目录下生成 Boston PDF文件,内容就是回归树。 graph.render('Boston') ---- 具体内容可以去 sklearn(https://scikit-learn.org/stable/modules/generated/sklearn.tree.export_graphviz.html) 和 graphviz(https://graphviz.readthedocs.io/en/stable/) 看看。编辑回复: 关于决策树可视化,大家可以看看这个。
2019-02-1537 小熊猫ID3:以信息增益作为判断标准,计算每个特征的信息增益,选取信息增益最大的特征,但是容易选取到取值较多的特征 C4.5:以信息增益比作为判断标准,计算每个特征的信息增益比,选取信息增益比最大的特征 CART:分类树以基尼系数为标准,选取基尼系数小的的特征 回归树以均方误差或绝对值误差为标准,选取均方误差或绝对值误差最小的特征 练习题: from sklearn import datasets from sklearn.model_selection import train_test_split from sklearn import tree from sklearn.metrics import accuracy_score import graphviz # 准备手写数字数据集 digits = datasets.load_digits() # 获取特征和标识 features = digits.data labels = digits.target # 选取数据集的33%为测试集,其余为训练集 train_features, test_features, train_labels, test_labels = train_test_split(features, labels, test_size=0.33) # 创建CART分类树 clf = tree.DecisionTreeClassifier() # 拟合构造CART分类树 clf.fit(train_features, train_labels) # 预测测试集结果 test_predict = clf.predict(test_features) # 测试集结果评价 print('CART分类树准确率:', accuracy_score(test_labels, test_predict)) # 画决策树 dot_data = tree.export_graphviz(clf, out_file=None) graph = graphviz.Source(dot_data) graph.render('CART//CART_practice_digits') CART分类树准确率: 0.8636363636363636
小熊猫ID3:以信息增益作为判断标准,计算每个特征的信息增益,选取信息增益最大的特征,但是容易选取到取值较多的特征 C4.5:以信息增益比作为判断标准,计算每个特征的信息增益比,选取信息增益比最大的特征 CART:分类树以基尼系数为标准,选取基尼系数小的的特征 回归树以均方误差或绝对值误差为标准,选取均方误差或绝对值误差最小的特征 练习题: from sklearn import datasets from sklearn.model_selection import train_test_split from sklearn import tree from sklearn.metrics import accuracy_score import graphviz # 准备手写数字数据集 digits = datasets.load_digits() # 获取特征和标识 features = digits.data labels = digits.target # 选取数据集的33%为测试集,其余为训练集 train_features, test_features, train_labels, test_labels = train_test_split(features, labels, test_size=0.33) # 创建CART分类树 clf = tree.DecisionTreeClassifier() # 拟合构造CART分类树 clf.fit(train_features, train_labels) # 预测测试集结果 test_predict = clf.predict(test_features) # 测试集结果评价 print('CART分类树准确率:', accuracy_score(test_labels, test_predict)) # 画决策树 dot_data = tree.export_graphviz(clf, out_file=None) graph = graphviz.Source(dot_data) graph.render('CART//CART_practice_digits') CART分类树准确率: 0.8636363636363636作者回复: Good Job
2019-02-1516- jake首先想问一个问题 就是在讲到基尼系数那里 有一个图那里的例子 什么D: 9个打篮球 3个不打篮球那里 那里的D的基尼系数用到了子节点归一化基尼系数之和这个方法求 请问D的基尼系数不能直接用 上面那个公式 也就是"1 - [p(ck|t)]^2"那个公式计算吗 我用这个公式计算出D的基尼系数为 1 - (9/12 * 9/12 + 3/12 * 3/12) = 6/16。 我也想问一下上面那个同学提的这个问题
编辑回复: 单纯看节点D的基尼系数,采用公式:1 - [p(ck|t)]^2,也就是Gini(D)=1 - (9/12 * 9/12 + 3/12 * 3/12) = 0.375 同时,文章也计算了关于节点D,在属性A划分下的基尼系数的情况: Gini(D, A)=|D1|/|D|*Gini(D1) + |D2|/|D|*Gini(D2)=6/12*0+6/12*0.5=0.25 所以Gini(D)=0.375, Gini(D, A)=0.25
2019-02-2427 - xfoolinID3 是通过信息增益,选取信息增益最大的特征;C4.5 是通过信息增益率,选取,CART 是通过基尼系数,选取基尼系数最小的特征。 from sklearn.model_selection import train_test_split#训练集和测试集 from sklearn.metrics import mean_squared_error#二乘偏差均值 from sklearn.metrics import mean_absolute_error#绝对值偏差均值 from sklearn.datasets import load_digits#引入 digits 数据集 from sklearn.metrics import accuracy_score#测试结果的准确性 from sklearn import tree import graphviz #准备数据集 digits = load_digits() #获取数据集的特征集和分类标识 features = digits.data labels = digits.target #随机抽取 33% 的数据作为测试集,其余为训练集 train_features,test_features,train_labels,test_labels = \ train_test_split(features,labels,test_size = 0.33,random_state = 0) #创建 CART 分类树 clf = tree.DecisionTreeClassifier(criterion = 'gini') #拟合构造分类树 clf = clf.fit(train_features,train_labels) #用 CART 分类树做预测 test_predict = clf.predict(test_features) #预测结果与测试集作对比 score = accuracy_score(test_labels,test_predict) #输出准确率 print('准确率 %.4f'%score) dot_data = tree.export_graphviz(clf,out_file = None) graph = graphviz.Source(dot_data) #输出分类树图示 graph.view()
作者回复: Good Job
2019-02-194  Lee# encoding=utf-8 from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score from sklearn.tree import DecisionTreeClassifier from sklearn.datasets import load_digits # 准备数据集 digits=load_digits() # 获取特征集和分类标识 features = digits.data labels = digits.target # 随机抽取 33% 的数据作为测试集,其余为训练集 train_features, test_features, train_labels, test_labels = train_test_split(features, labels, test_size=0.33, random_state=0) # 创建 CART 分类树 clf = DecisionTreeClassifier(criterion='gini') # 拟合构造 CART 分类树 clf = clf.fit(train_features, train_labels) # 用 CART 分类树做预测 test_predict = clf.predict(test_features) # 预测结果与测试集结果作比对 score = accuracy_score(test_labels, test_predict) print("CART 分类树准确率 %.4lf" % score) CART 分类树准确率 0.8620
Lee# encoding=utf-8 from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score from sklearn.tree import DecisionTreeClassifier from sklearn.datasets import load_digits # 准备数据集 digits=load_digits() # 获取特征集和分类标识 features = digits.data labels = digits.target # 随机抽取 33% 的数据作为测试集,其余为训练集 train_features, test_features, train_labels, test_labels = train_test_split(features, labels, test_size=0.33, random_state=0) # 创建 CART 分类树 clf = DecisionTreeClassifier(criterion='gini') # 拟合构造 CART 分类树 clf = clf.fit(train_features, train_labels) # 用 CART 分类树做预测 test_predict = clf.predict(test_features) # 预测结果与测试集结果作比对 score = accuracy_score(test_labels, test_predict) print("CART 分类树准确率 %.4lf" % score) CART 分类树准确率 0.8620作者回复: Good Job
2019-01-243 雨先生的晴天scikit learn package 确实非常好用,很简洁。推荐大家也去官网看一看,请问一下怎样可以把decision tree 可视化呀?
雨先生的晴天scikit learn package 确实非常好用,很简洁。推荐大家也去官网看一看,请问一下怎样可以把decision tree 可视化呀?编辑回复: 评论中有人对决策树可视化做了解释,你可以看下。采用的是graphviz这个库,你需要先安装,然后使用。
2019-01-272 Mi compaero de armas老师您好,请问采用CART算法时,如果离散型属性的值不止两种还能使用CART算法吗
Mi compaero de armas老师您好,请问采用CART算法时,如果离散型属性的值不止两种还能使用CART算法吗作者回复: 可以用CART算法,另外GBDT里面默认使用的是CART,这是个在数据分析,机器学习中常用的模型
2019-11-191 Ronnyz
Ronnyz 第二问 ``` from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score from sklearn.tree import DecisionTreeClassifier from sklearn.datasets import load_digits digits = load_digits() # print(digits) features=digits.data labels = digits.target train_features,test_features,train_labels,test_labels=train_test_split(features,labels,test_size =0.33,random_state=0) clf = DecisionTreeClassifier(criterion='gini') clf=clf.fit(train_features,train_labels) predict_labels=clf.predict(test_features) print('分类准确度:',accuracy_score(test_labels,predict_labels)) ``` 分类准确度: 0.8619528619528619
第二问 ``` from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score from sklearn.tree import DecisionTreeClassifier from sklearn.datasets import load_digits digits = load_digits() # print(digits) features=digits.data labels = digits.target train_features,test_features,train_labels,test_labels=train_test_split(features,labels,test_size =0.33,random_state=0) clf = DecisionTreeClassifier(criterion='gini') clf=clf.fit(train_features,train_labels) predict_labels=clf.predict(test_features) print('分类准确度:',accuracy_score(test_labels,predict_labels)) ``` 分类准确度: 0.8619528619528619作者回复: 代码正确
2019-11-111 许宇宝老师,看了两遍还是不明白分类的这个决策树是依据什么画出来的?
许宇宝老师,看了两遍还是不明白分类的这个决策树是依据什么画出来的?作者回复: take it easy
2019-07-181- 羊小看1、为什么CRAT的基尼系数比C4.5的信息增益率好呢?既然sklearn库默认用的基尼系数,应该是这个好一些吧? 2、from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score from sklearn.tree import DecisionTreeClassifier #from sklearn.datasets import load_iris from sklearn.datasets import load_digits # 准备数据集 #iris=load_iris() digits=load_digits() # 获取特征集和分类标识 #features = iris.data #labels = iris.target features = digits.data labels = digits.target # 随机抽取 33% 的数据作为测试集,其余为训练集 train_features, test_features, train_labels, test_labels = train_test_split(features, labels, test_size=0.33, random_state=0) # 创建 CART 分类树 clf = DecisionTreeClassifier(criterion='gini') # 拟合构造 CART 分类树 clf = clf.fit(train_features, train_labels) # 用 CART 分类树做预测 test_predict = clf.predict(test_features) # 预测结果与测试集结果作比对 score = accuracy_score(test_labels, test_predict) print("CART 分类树准确率 %.4lf" % score) CART 分类树准确率 0.8636
作者回复: Good Job
2019-05-101

