

22丨SVM(上):如何用一根棍子将蓝红两色球分开?

该思维导图由 AI 生成,仅供参考
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

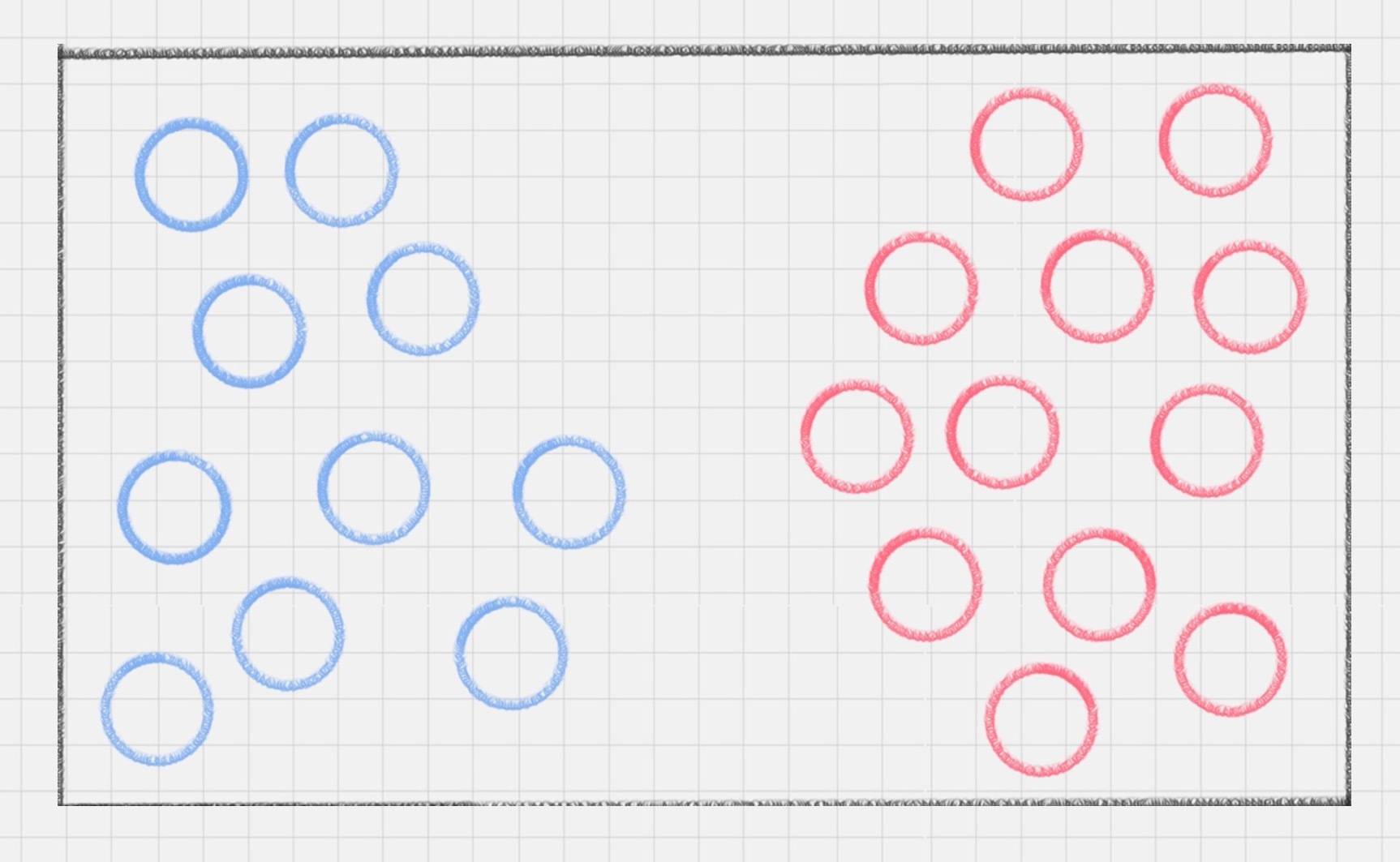
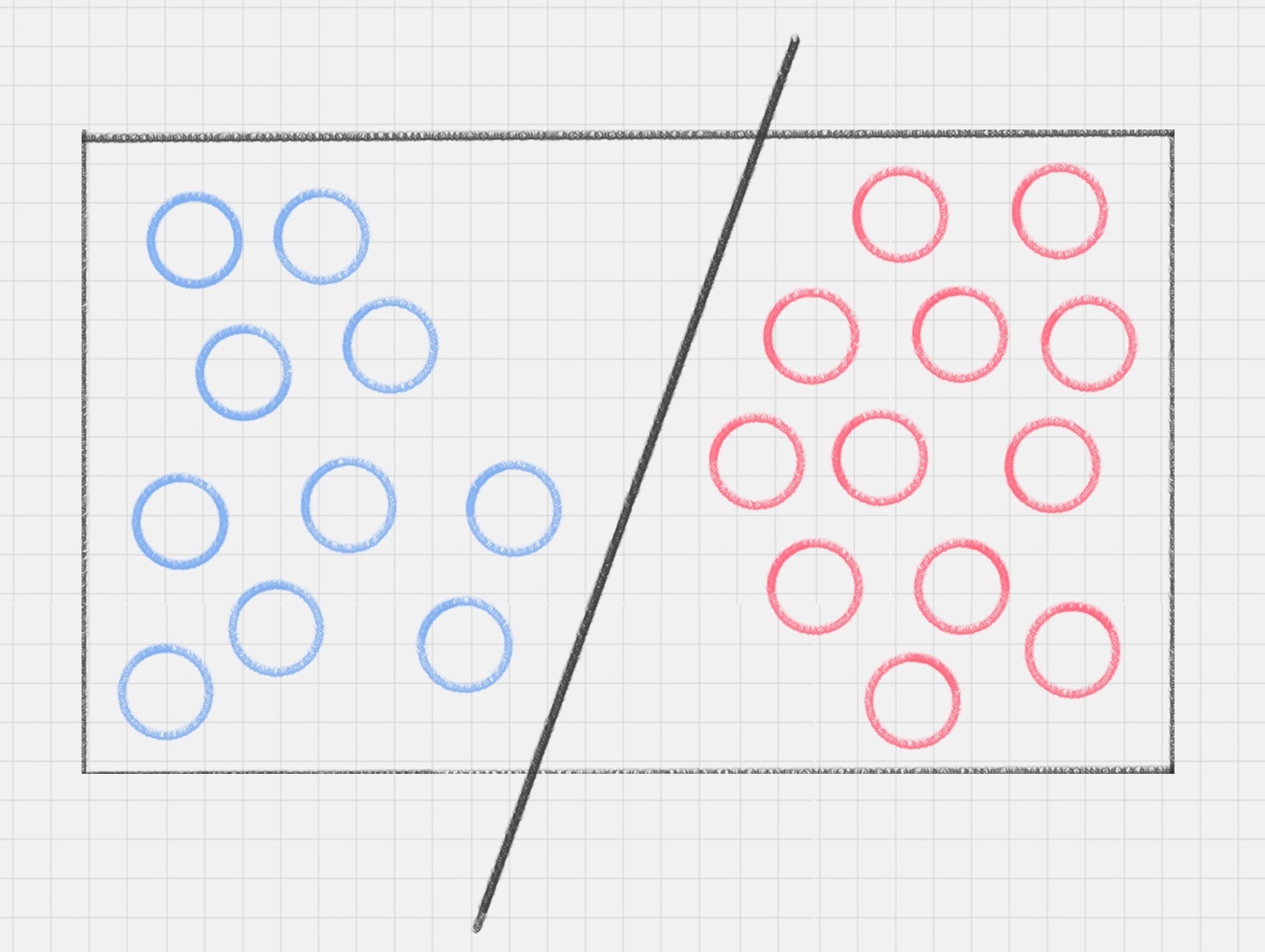
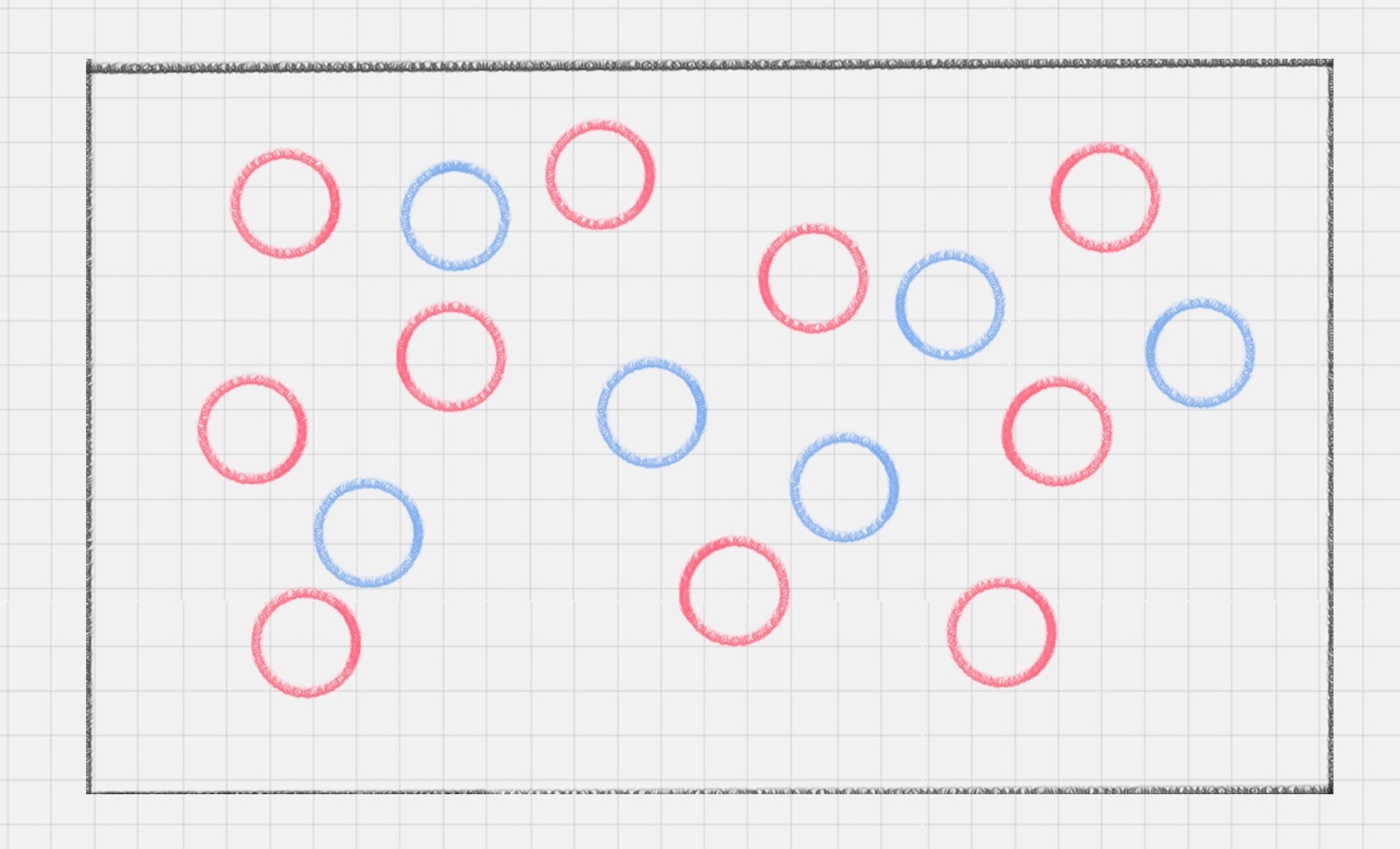
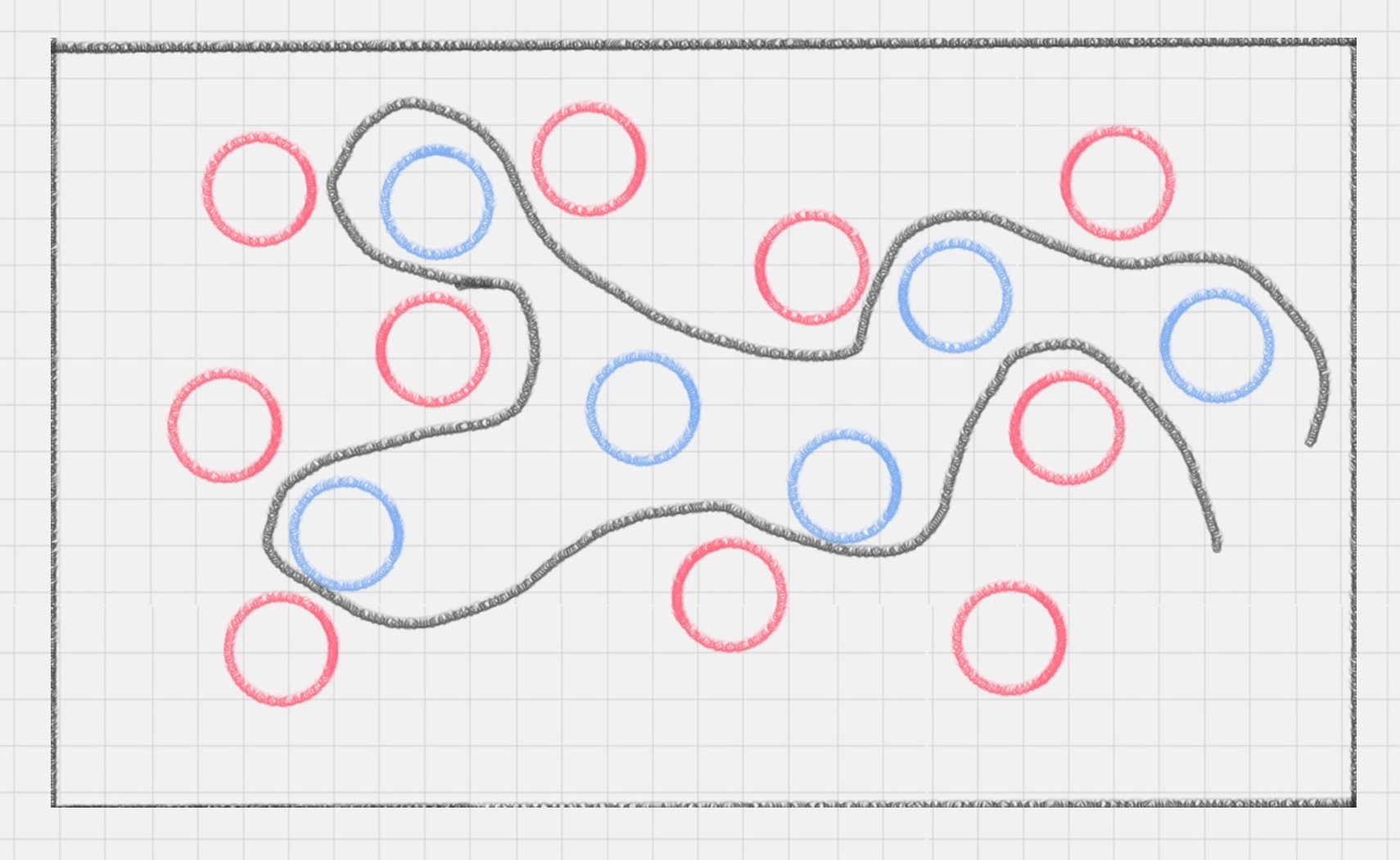
SVM(支持向量机)是一种有监督学习模型,用于模式识别、分类和回归分析。它通过找到一个超平面来对数据进行分类,其中最优的超平面是指具有最大分类间隔的超平面。支持向量是离分类超平面最近的样本点,决定了分类间隔的大小。文章介绍了SVM的工作原理,包括分类间隔的概念和最大间隔的优化模型。此外,还介绍了硬间隔、软间隔和非线性SVM,以及核函数的作用。核函数可以将样本从原始空间映射到一个更高维的特征空间,使得样本在新的空间中线性可分。针对多分类问题,文章提出了一对多法和一对一法两种方法,将多个二分类器组合成一个多分类器。总的来说,SVM是一种强大的分类方法,可以处理线性可分和非线性可分的数据,并且具有较强的鲁棒性。
《数据分析实战 45 讲》,新⼈⾸单¥59

全部留言(28)
- 最新
- 精选
- captain老师好,最近几期的算法课内容量比较大,麻烦推荐一些相关的理论或案例的书籍,谢谢
编辑回复: 关于书籍: 《Python数据挖掘与机器学习实战》 因为我在代码中用到sklearn比较多,可以结合这个来看,里面有一些关于sklearn数据集的练习,我在专栏中也用到过,你可以对应起来看 《白话大数据与机器学习》这本书主要讲算法原理,没有太多实战。想要对原理更深入了解的话可以看看 《利用Python进行数据分析》 这本相对基础,没有太多算法部分,主要是关于Python的使用:数据结构,NumPy,Pandas,数据加载、存储、清洗、规整、可视化等。 《精益数据分析》 这本书是将业务场景的,里面没有算法的部分,所以如果你想对业务场景有更深刻的理解,可以看下这本 关于项目实战 可以配合 https://www.kaggle.com/ 比如你想做和SVM相关的,可以在kernels中搜索SVM https://www.kaggle.com/kernels?sortBy=relevance&group=everyone&search=SVM&page=1&pageSize=20
2019-02-0159  third有监督学习,就是告诉他这个是红的那个是蓝的。你给我分出红蓝 无监督,自己学会认识红色和蓝色,然后再分类 硬间接,就是完美数据下的完美情况,分出完美类 软间隔,就是中间总有杂质,情况总是复杂,分类总是有一点错误 核函数,高纬度打低纬度,
third有监督学习,就是告诉他这个是红的那个是蓝的。你给我分出红蓝 无监督,自己学会认识红色和蓝色,然后再分类 硬间接,就是完美数据下的完美情况,分出完美类 软间隔,就是中间总有杂质,情况总是复杂,分类总是有一点错误 核函数,高纬度打低纬度,编辑回复: 这个解释比较通俗易懂,大家都可以看看。
2019-02-1844 李沛欣核函数,是一种格局更高的分类模式。通过它我们可以把原本混沌的一堆数据映射到高维,从上帝视角来对这些数据进行线性分类。 来,扔个二向箔🤣
李沛欣核函数,是一种格局更高的分类模式。通过它我们可以把原本混沌的一堆数据映射到高维,从上帝视角来对这些数据进行线性分类。 来,扔个二向箔🤣编辑回复: 对的,核函数就是从低维到高维的映射关系。如果从高维到低维进行维度压缩的话,可能就会变得混沌不可分。但是从低维到高维,属性维度增加了,可以在另一个空间中变得线性可分。
2019-02-09318 fancy1. 有监督学习and无监督学习 有监督学习,即在已有类别标签的情况下,将样本数据进行分类。 无监督学习,即在无类别标签的情况下,样本数据根据一定的方法进行分类,即聚类,分类好的类别需要进一步分析后,从而得知每个类别的特点。 2. 硬间隔、软间隔、核函数 使用SVM算法,是基于数据是线性分布的情况,这时使用硬间隔的方法分类数据即可。但实际情况下,大部分数据都不属于线性分布,即通过软间隔、核函数处理后,使得数据可以利用SVM算法进行分类。软间隔是通过允许数据有误差,不是绝对的线性分布;核函数是通过将非线性分布的数据映射为线性分布的数据。
fancy1. 有监督学习and无监督学习 有监督学习,即在已有类别标签的情况下,将样本数据进行分类。 无监督学习,即在无类别标签的情况下,样本数据根据一定的方法进行分类,即聚类,分类好的类别需要进一步分析后,从而得知每个类别的特点。 2. 硬间隔、软间隔、核函数 使用SVM算法,是基于数据是线性分布的情况,这时使用硬间隔的方法分类数据即可。但实际情况下,大部分数据都不属于线性分布,即通过软间隔、核函数处理后,使得数据可以利用SVM算法进行分类。软间隔是通过允许数据有误差,不是绝对的线性分布;核函数是通过将非线性分布的数据映射为线性分布的数据。编辑回复: 解释的很清晰,大家可以看下。
2019-02-2710- 霸蛮人核函数,是使用变换思维,当数据从一个角度无法进行分类,就变换一个角度来分。就比如,两个人的声音混在一起,要区分开来的话,从时域的角度去看,互相叠加,根本就无法区分,但通过傅里叶变换到频域之后,通过频率的不同就能轻松地区分开来了。在这里,傅里叶变换就相当于核函数的作用。面对不同的数据常见,需要使用不同的变换角度,也就是不同的核函数。
作者回复: 总结的不错!!!
2020-04-0726  Python硬间隔,我认为就像线性回归一样,一条直线粗暴的画出边界,然后回答YES OR NO。 软间隔,我认为类似逻辑回归,会绕一下弯子,最后给出的答案是一个概率。 以上两种方式都是处理线性可分的数据,但碰到线性完全分布开的非线性数据的时候,就需要用到核函数,核函数主要是通过把低维的数据映射到高纬,产生一个落差,并给出一个超平面来划分。 不知道我理解的对不对,希望老师回答YES OR NO
Python硬间隔,我认为就像线性回归一样,一条直线粗暴的画出边界,然后回答YES OR NO。 软间隔,我认为类似逻辑回归,会绕一下弯子,最后给出的答案是一个概率。 以上两种方式都是处理线性可分的数据,但碰到线性完全分布开的非线性数据的时候,就需要用到核函数,核函数主要是通过把低维的数据映射到高纬,产生一个落差,并给出一个超平面来划分。 不知道我理解的对不对,希望老师回答YES OR NO编辑回复: 是的,可以这么理解。核函数与硬间隔、软间隔 不是在同一个维度,是从低维到高维空间的映射,因为在同一个维度上已经无法线性可分。而硬间隔、软间隔主要对线性可分的容错率。硬间隔可以完美切分样本,但是软间隔就需要允许有一定的样本分类错误。
2019-02-035 林老师好,这一块的数学原理讲的有点少了吧,能不能讲讲拉格朗日对偶和kkt
林老师好,这一块的数学原理讲的有点少了吧,能不能讲讲拉格朗日对偶和kkt编辑回复: 这一块适当屏蔽了一些数学原理,关于拉格朗日对偶和kkt的推导就省略了,感兴趣的同学可以看下SVM原理中的这部分。
2019-02-163 深白浅黑核心在于数据是否线性可分,以及容错能力强弱。 硬间隔和软间隔都是处理线性可分的情况,区别在于容错能力。 核函数用于处理线性不可分情况,将现有数据进行升维,达到线性可分,再进行类别划分处理。
深白浅黑核心在于数据是否线性可分,以及容错能力强弱。 硬间隔和软间隔都是处理线性可分的情况,区别在于容错能力。 核函数用于处理线性不可分情况,将现有数据进行升维,达到线性可分,再进行类别划分处理。作者回复: 对的
2019-02-153 一纸书那句"灵机一动,猛拍一下桌子"真的是神来一笔,哈哈哈哈哈哈
一纸书那句"灵机一动,猛拍一下桌子"真的是神来一笔,哈哈哈哈哈哈作者回复: 哈哈 确实 很形象
2019-11-132 滢告诉机器,给它一些数据,这部分数据一些是数据集合A,一部分是属于集合B,然后让机器去把数据往集合A和集合B里去划分,这是有监督学习;同样的数据给机器,只是告诉它去做划分和归类,这是无监督学习,类似于孩子的放养。 硬间隔:表示得到的分类间隔即超平面 能完美的划分数据,不存在划分错误的情况,即零误差 软间隔:表示得到的分类间隔,没有达到完美的程度,对数据划分存在一定的误差 核函数:在数据分布无法用线性函数来表示的时候,需要对数据进行划分的标准变成来非线性的,这个时候就需要用到一种函数名叫核函数,核函数要做的工作是将原来的映射关系在更高维度的空间重新映射,使得新的映射关系变得线性可分。
滢告诉机器,给它一些数据,这部分数据一些是数据集合A,一部分是属于集合B,然后让机器去把数据往集合A和集合B里去划分,这是有监督学习;同样的数据给机器,只是告诉它去做划分和归类,这是无监督学习,类似于孩子的放养。 硬间隔:表示得到的分类间隔即超平面 能完美的划分数据,不存在划分错误的情况,即零误差 软间隔:表示得到的分类间隔,没有达到完美的程度,对数据划分存在一定的误差 核函数:在数据分布无法用线性函数来表示的时候,需要对数据进行划分的标准变成来非线性的,这个时候就需要用到一种函数名叫核函数,核函数要做的工作是将原来的映射关系在更高维度的空间重新映射,使得新的映射关系变得线性可分。作者回复: 对的 整理的不错 滢
2019-04-182

