

33丨如何使用性能分析工具定位SQL执行慢的原因?
陈旸

该思维导图由 AI 生成,仅供参考
在上一篇文章中,我们了解了查询优化器,知道在查询优化器中会经历逻辑查询优化和物理查询优化。需要注意的是,查询优化器只能在已经确定的情况下(SQL 语句、索引设计、缓冲池大小、查询优化器参数等已知的情况)决定最优的查询执行计划。
但实际上 SQL 执行起来可能还是很慢,那么到底从哪里定位 SQL 查询慢的问题呢?是索引设计的问题?服务器参数配置的问题?还是需要增加缓存的问题呢?今天我们就从性能分析来入手,定位导致 SQL 执行慢的原因。
今天的内容主要包括以下几个部分:
数据库服务器的优化分析的步骤是怎样的?中间有哪些需要注意的地方?
如何使用慢查询日志查找执行慢的 SQL 语句?
如何使用 EXPLAIN 查看 SQL 执行计划?
如何使用 SHOW PROFILING 分析 SQL 执行步骤中的每一步的执行时间?
数据库服务器的优化步骤
当我们遇到数据库调优问题的时候,该如何思考呢?我把思考的流程整理成了下面这张图。
整个流程划分成了观察(Show status)和行动(Action)两个部分。字母 S 的部分代表观察(会使用相应的分析工具),字母 A 代表的部分是行动(对应分析可以采取的行动)。
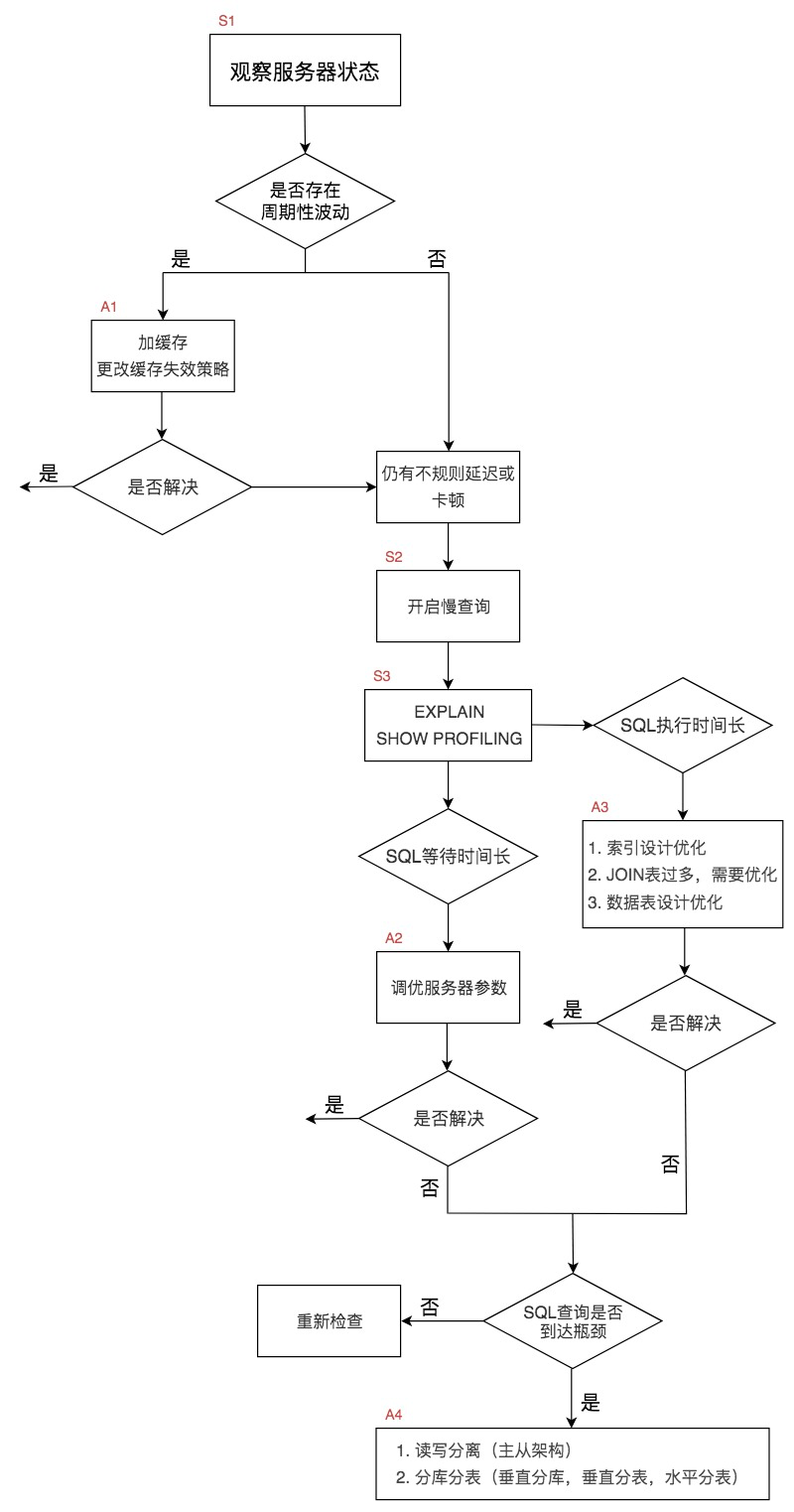
我们可以通过观察了解数据库整体的运行状态,通过性能分析工具可以让我们了解执行慢的 SQL 都有哪些,查看具体的 SQL 执行计划,甚至是 SQL 执行中的每一步的成本代价,这样才能定位问题所在,找到了问题,再采取相应的行动。
公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结

本文详细介绍了如何使用性能分析工具来定位SQL执行慢的原因。首先,通过观察服务器状态、开启慢查询、使用EXPLAIN查看执行计划以及使用SHOW PROFILING分析执行步骤时间等数据库服务器的优化分析步骤,读者可以快速定位SQL执行慢的原因。其次,文章详细介绍了如何使用慢查询日志来定位执行慢的SQL语句,包括开启慢查询日志、设置时间阈值以及使用mysqldumpslow工具提取慢查询语句。最后,文章总结了数据库调优的流程思路,包括观察、行动和相应的优化措施。通过这些步骤和工具,读者可以快速定位SQL执行慢的原因,从而进行相应的优化和调整。文章还介绍了EXPLAIN和SHOW PROFILE这两个工具,以及数据表连接的多种访问类型,如ref、eq_ref和const,并探讨了它们的区别和查询效率。整体而言,本文为读者提供了全面的SQL性能分析工具和优化思路,对于需要进行数据库性能优化的技术人员具有很高的参考价值。
仅可试看部分内容,如需阅读全部内容,请付费购买文章所属专栏
《SQL 必知必会》,新⼈⾸单¥68
《SQL 必知必会》,新⼈⾸单¥68
立即购买
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
全部留言(18)
- 最新
- 精选
 DZ如果两表关联查询,可以这样理解: 1. ref - 双层循环,直到找出所有匹配。 2. eq_ref - 双层循环,借助索引的唯一性,找到匹配就马上退出内层循环。 3. const: 单层循环。 按照循环次数递减的顺序排列它们,应该是 ref > eq_ref > const,循环次数越少,查询效率越高。
DZ如果两表关联查询,可以这样理解: 1. ref - 双层循环,直到找出所有匹配。 2. eq_ref - 双层循环,借助索引的唯一性,找到匹配就马上退出内层循环。 3. const: 单层循环。 按照循环次数递减的顺序排列它们,应该是 ref > eq_ref > const,循环次数越少,查询效率越高。作者回复: 对的,所以效率上来说一般是 ref < eq_ref < const
2019-08-2636 土土人oracle是否有对应工呢?
土土人oracle是否有对应工呢?作者回复: 有的,比如Oracle自带的AWR工具
2019-08-268 LJKSHOW PROFILE还会再有细致一点的说明么?一般看到都是sending data这个时间最长,不知道包含了哪些具体操作在里面?
LJKSHOW PROFILE还会再有细致一点的说明么?一般看到都是sending data这个时间最长,不知道包含了哪些具体操作在里面?作者回复: 一般来说sending data相比于其他部分会比较长。你也可以查看不同的模块时间,比如SHOW PROFILE cpu,block_io for query ...
2019-08-275 leslieexplain看的东西不止这点吧:老师是不是针对错了DB,至少现实生产这点东西的定位完全不够;老师在生产中不看表的状态就做explain么?如果表的DML过高的话,explain的操作完全没有价值。 如果一张表的自增跑到了100万,数据量只有10万;说明这张表可能已经损坏了,第一步就是修复表而不是一开始做explain。就像我们拿到一台设备不是先去测功能,首先应当坚持设备是否完全OK再去测试,数据库不可能拿到的是一张全新的表;首先应当是表的性能评估,然后再说相关的检查吧。 个人觉得今天的讲解的时候漏了真正的第一步:设备没坚持就开始检查设备性能了。2019-08-27230
leslieexplain看的东西不止这点吧:老师是不是针对错了DB,至少现实生产这点东西的定位完全不够;老师在生产中不看表的状态就做explain么?如果表的DML过高的话,explain的操作完全没有价值。 如果一张表的自增跑到了100万,数据量只有10万;说明这张表可能已经损坏了,第一步就是修复表而不是一开始做explain。就像我们拿到一台设备不是先去测功能,首先应当坚持设备是否完全OK再去测试,数据库不可能拿到的是一张全新的表;首先应当是表的性能评估,然后再说相关的检查吧。 个人觉得今天的讲解的时候漏了真正的第一步:设备没坚持就开始检查设备性能了。2019-08-27230 许童童你可以讲一下 ref、eq_ref 和 const 这三种类型的区别吗?查询效率有何不同? ref 是使用了非唯一索引 eq_ref 是使用了主键或唯一索引,一般在两表连接查询中索引 const 是使用了主键或唯一索引 与常量值进行比较 查询效率 ref < eq_ref < const2019-08-265
许童童你可以讲一下 ref、eq_ref 和 const 这三种类型的区别吗?查询效率有何不同? ref 是使用了非唯一索引 eq_ref 是使用了主键或唯一索引,一般在两表连接查询中索引 const 是使用了主键或唯一索引 与常量值进行比较 查询效率 ref < eq_ref < const2019-08-265 学无涯用EXPLAIN查看SQL执行顺序:如果SQL使用EXISTS嵌套子查询,按说,执行顺序是先执行主查询,再执行子查询,但是EXPLAIN出来的结果是主查询的id为1,子查询的id为2,也就是说是先执行的子查询,这是为什么呢2019-08-2713
学无涯用EXPLAIN查看SQL执行顺序:如果SQL使用EXISTS嵌套子查询,按说,执行顺序是先执行主查询,再执行子查询,但是EXPLAIN出来的结果是主查询的id为1,子查询的id为2,也就是说是先执行的子查询,这是为什么呢2019-08-2713 靠人品去赢想问一下,运维的那个MySQL慢SQL的页面怎么弄出来的的,就是甩给我一个网页地址,里面是SLOW LOG PLATFORM里面的详细慢sql日志,毕竟是页面,感觉看起来要比去服务器看输出友好一点。 是什么工具,搭建在自己的服务器,可以选择数据库,选择用户的查看日志详情,自己玩,安装的话对服务器要求高吗2021-04-292
靠人品去赢想问一下,运维的那个MySQL慢SQL的页面怎么弄出来的的,就是甩给我一个网页地址,里面是SLOW LOG PLATFORM里面的详细慢sql日志,毕竟是页面,感觉看起来要比去服务器看输出友好一点。 是什么工具,搭建在自己的服务器,可以选择数据库,选择用户的查看日志详情,自己玩,安装的话对服务器要求高吗2021-04-292 尔冬橙当前会话是代表什么,当前事务么2020-03-272
尔冬橙当前会话是代表什么,当前事务么2020-03-272 安静的boyindex_merge的那个例子中,查询的type怎么是ref2019-08-262
安静的boyindex_merge的那个例子中,查询的type怎么是ref2019-08-262 学渣汪在央企打怪升级EXPLAIN那里有些不太清楚,还有要是有一些经验上的阈值分析就好了2020-03-271
学渣汪在央企打怪升级EXPLAIN那里有些不太清楚,还有要是有一些经验上的阈值分析就好了2020-03-271
收起评论

