

27丨从数据页的角度理解B+树查询

该思维导图由 AI 生成,仅供参考
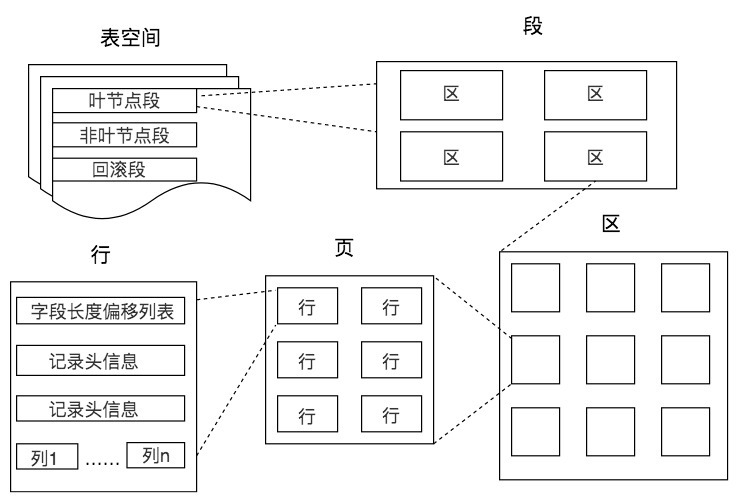
数据库中的存储结构是怎样的
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

本文深入解析了B+树查询的原理,从数据页的角度出发,介绍了数据库中的存储结构,包括页、区、段和表空间的概念及其关系。详细讲解了数据页内的结构,包括文件头、页头、记录部分、空闲空间、页目录等组成部分的作用和结构。通过图示和实例,生动地解释了这些概念和结构在数据库中的作用和运行机制。读者可以深入了解数据库存储结构和页的内部结构,从而对索引的存储、查询原理有更深的理解。文章还探讨了B+树的结构,如叶子节点和非叶子节点的特点,以及B+树进行记录检索的原理。此外,还对普通索引和唯一索引在查询效率上的不同进行了分析。总结了数据库中的基本存储单位,页的特点,以及链表数据结构的应用。文章以问题引导思考,鼓励读者参与交流讨论。
《SQL 必知必会》,新⼈⾸单¥68

全部留言(44)
- 最新
- 精选
 我行我素1.逻辑上连续的,在文中有说采用链表的结构让数据页之间不需要是物理上的连续,而是逻辑上的连续; 2.二分查找发,在总结图中有详细的说明,首先是从B+树的根开始,逐层检索直到叶子节点,找到叶子节点对应的数据页,将数据页加载到内存中,通过页目录中的槽采用二分查找的方式先找到一个粗略的记录分组,在分组中通过链表遍历的方式进行记录的查找
我行我素1.逻辑上连续的,在文中有说采用链表的结构让数据页之间不需要是物理上的连续,而是逻辑上的连续; 2.二分查找发,在总结图中有详细的说明,首先是从B+树的根开始,逐层检索直到叶子节点,找到叶子节点对应的数据页,将数据页加载到内存中,通过页目录中的槽采用二分查找的方式先找到一个粗略的记录分组,在分组中通过链表遍历的方式进行记录的查找作者回复: 总结的不错
2019-08-12532 吴小智请问一下老师,这些内容的源头是在哪里呢?想去源头看看
吴小智请问一下老师,这些内容的源头是在哪里呢?想去源头看看作者回复: 感谢兴趣,最直接的来源就是官方的Document,比如 https://dev.mysql.com/doc/internals/en/innodb-fil-header.html 而且检索起来也很方便,比如你想要查询优化器的cost model是如何设计的,就可以找到 https://dev.mysql.com/doc/refman/8.0/en/cost-model.html
2019-08-2314 程序员花卷第一个问题 我认为物理上是连续的(具体原因我现在还说不出来,因为这个问题感觉逻辑连续和物理连续都没有绝对的说法,后面补上) 第二个问题 B+树的检索流程是一个自顶向下,逐层检索的过程!具体的过程老师在24讲以及这一讲中已经说的很明白了! 我得认真思考!老师的问题总是很耐人寻味! 题外话:希望大家都继续坚持学习,学习是一辈子的事,不要渴望一遍两遍就掌握某个东西!很多东西都是在反反复复的学习之中的某个时刻突然领悟的!加油!
程序员花卷第一个问题 我认为物理上是连续的(具体原因我现在还说不出来,因为这个问题感觉逻辑连续和物理连续都没有绝对的说法,后面补上) 第二个问题 B+树的检索流程是一个自顶向下,逐层检索的过程!具体的过程老师在24讲以及这一讲中已经说的很明白了! 我得认真思考!老师的问题总是很耐人寻味! 题外话:希望大家都继续坚持学习,学习是一辈子的事,不要渴望一遍两遍就掌握某个东西!很多东西都是在反反复复的学习之中的某个时刻突然领悟的!加油!作者回复: 学习是一辈子的事,感谢加武同学的分享
2019-12-234 梁聚集索引是在物理上的顺序和逻辑上的顺序相同
梁聚集索引是在物理上的顺序和逻辑上的顺序相同作者回复: 对的
2019-11-224 往事随风,顺其自然逻辑上连续的,记录之间采用单链表方式实现
往事随风,顺其自然逻辑上连续的,记录之间采用单链表方式实现作者回复: 对的
2019-08-124 geraltlaushA clustered index, on the other hand, is actually the table. It is an index that enforces the ordering on the rows of the table physically.物理上连续的
geraltlaushA clustered index, on the other hand, is actually the table. It is an index that enforces the ordering on the rows of the table physically.物理上连续的作者回复: 对的
2019-09-1262 习惯沉淀老师,“在B+树中,每一个节点都是一个页”这句,有点不太理解,非叶子节点不是不存放行记录吗,非叶子节点就是页,只不过页里面不存放数据是这意思吗?
习惯沉淀老师,“在B+树中,每一个节点都是一个页”这句,有点不太理解,非叶子节点不是不存放行记录吗,非叶子节点就是页,只不过页里面不存放数据是这意思吗?作者回复: 对 B+树的非叶子节点不存放具体的行记录数据。
2019-08-202 Yuhui请教一下老师,”通过文件尾的校验和(checksum 值)与文件头的校验和做比较“来判断页数据传输是否完整这个是怎么回事?谢谢!
Yuhui请教一下老师,”通过文件尾的校验和(checksum 值)与文件头的校验和做比较“来判断页数据传输是否完整这个是怎么回事?谢谢!作者回复: 校验和checksum经常用于数据传输过程中的数据完整性/准确性校验。checksum算法有很多,举个例子比如MD5算法,在文件头的时候给出完整的文件应该得到的MD5数值为多少,等到文件尾的时候,再使用MD5对整体进行运算,看下和文件头给出的是否一致。如果一致,则说明传输过程是完整正确的,如果不一致则存在错误,需要重新传输。
2019-09-1921 asdf100对页里查找记录时,可先根据二分查找法,先找到记录所有在槽,时间复杂度为O(log2n)。槽内有多条记录,再遍历所有记录,直到找到指定记录为止,时间复杂度为O(n)。
asdf100对页里查找记录时,可先根据二分查找法,先找到记录所有在槽,时间复杂度为O(log2n)。槽内有多条记录,再遍历所有记录,直到找到指定记录为止,时间复杂度为O(n)。作者回复: 正确
2019-08-131- asdf100遍历槽 3 中的所有记录,找到关键字为 9 的记录,取出该条记录的信息即为我们想要查找的内容。由于单链表,所以查询复杂度为O(n)
作者回复: 对的
2019-08-131

