

03丨学会用数据库的方式思考SQL是如何执行的

该思维导图由 AI 生成,仅供参考
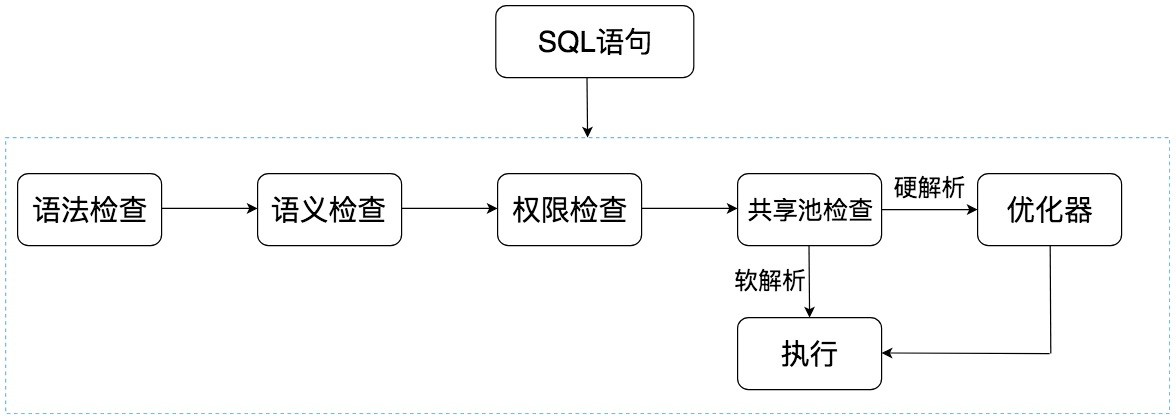
Oracle 中的 SQL 是如何执行的
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

SQL在Oracle和MySQL中的执行过程有着相似之处,但也存在一些显著差异。在Oracle中,SQL语句经历了语法检查、语义检查、权限检查、共享池检查、优化器和执行器等步骤。共享池的存在决定了SQL语句是否需要进行硬解析,而绑定变量可以减少硬解析的次数。而在MySQL中,SQL语句经历了连接层、SQL层和存储引擎层的处理,其中解析器、优化器和执行器的功能与Oracle类似。MySQL的存储引擎采用了插件的形式,每个存储引擎都面向一种特定的数据库应用环境。此外,MySQL的8.0版本后不再支持查询缓存,直接执行解析器→优化器→执行器的流程。读者通过本文可以快速了解SQL在不同数据库管理系统中的执行原理和特点,以及如何优化SQL的执行效率。 Oracle中的绑定变量可以减少SQL语句的硬解析次数,提高执行效率,但需要注意绑定变量的使用方式和管理。MySQL的存储引擎中,MyISAM适合读密集型应用,而InnoDB适合写密集型应用,读者可以根据具体需求选择合适的存储引擎。最后,解析后的SQL语句在Oracle中进行缓存的区域是共享池。通过本文的内容,读者可以全面了解SQL在Oracle和MySQL中的执行过程及相关特性,为数据库应用和优化提供了有益的参考。
《SQL 必知必会》,新⼈⾸单¥68

全部留言(113)
- 最新
- 精选

 Frank置顶老师,那两张,oracle,mysql 的大图。是哪儿的。有没有高清的啊。很多小字看不清楚。能否给个高清的链接。
Frank置顶老师,那两张,oracle,mysql 的大图。是哪儿的。有没有高清的啊。很多小字看不清楚。能否给个高清的链接。编辑回复: 请您点击这里进行下载:https://github.com/cystanford/SQL-XMind
2019-06-19214 FATMAN89置顶老师讲的挺好的,想请问老师,课程所用到的数据库在哪里可以获得呢,多谢
FATMAN89置顶老师讲的挺好的,想请问老师,课程所用到的数据库在哪里可以获得呢,多谢编辑回复: 第五篇文章会给出下载链接~
2019-06-1810 刘桢今年考研必上北京邮电大学!
刘桢今年考研必上北京邮电大学!作者回复: 加油~ 没问题的
2019-06-181349- NO.9C,共享池。 讲的好系统啊,有种想学个花拳绣腿,结果教我九阳神功的感觉。
作者回复: 很好 加油~
2019-06-3015  张驰皓感觉 MySQL 部分的第二张图(流程图)有点问题,“缓存查询”后“找到”分支的箭头应该不用再指向”缓存查询“吧?
张驰皓感觉 MySQL 部分的第二张图(流程图)有点问题,“缓存查询”后“找到”分支的箭头应该不用再指向”缓存查询“吧?作者回复: 感谢认真提问,缓存查询后,如果找到了就直接输出结果。如果没有找到就执行 解析器=>优化器=>执行器的流程,然后可以将结果存储到 缓存中方便后续进行查询。所以箭头回向指的是这个
2019-12-0113- qf年间文中多次提到执行计划,这是一个什么东西呢,可否具体讲解一下,或者举例说明
作者回复: 最简单的方式,你可以使用explain来查看某一条SQL语句的执行计划,这样比较直观,比如 EXPLAIN SELECT * FROM player 你能看到在MySQL查询优化器中是如何执行SQL语句的
2019-09-108  allean共享池
allean共享池作者回复: 对的
2019-06-177 leslie再次听一遍不一样的东西还是会发现不一样的收货:这大概就是数据库用的多了有时代码层确实没啥 ,可是切换中的优化过程还是会疏漏某些分析细节。 explain已经用到了极致,忘了优化的极限其实是多种方式的相辅相成;profile早期用过,反而这几年用的很少很少;explain更加管用-在多种数据库中,反而忘了有时需要一些简单的手段辅以。
leslie再次听一遍不一样的东西还是会发现不一样的收货:这大概就是数据库用的多了有时代码层确实没啥 ,可是切换中的优化过程还是会疏漏某些分析细节。 explain已经用到了极致,忘了优化的极限其实是多种方式的相辅相成;profile早期用过,反而这几年用的很少很少;explain更加管用-在多种数据库中,反而忘了有时需要一些简单的手段辅以。作者回复: 加油~ 哈哈
2019-06-176- firstbloodMyISAM 和InnoDB的比较参考https://www.jianshu.com/p/a957b18ba40d 这个文章
作者回复: 多谢分享
2019-09-251 - Geek_d3a509Oracle中绑定变量:SQL语句中相同的操作对不同的变量值用一个变量来代替,使得Oracle中要做硬解析变成软解析,以减少Oracle在解析上花费的时间 优点:减少了很多不必要的硬解析,将由软解析代替,大大降低数据库花费在SQL解析上的资源开销(时间与空间的浪费)。 缺点:绑定了变量之后优化比较困难,使用绑定之后可能对执行计划有一定的影响,导致执行计划的出错。比如很多重复的语句使用一个变量代替,那么可能就第一条解析正确,余下的就不能正确执行。 InnoDB的特性与使用场景(mysql5.5及以后版本默认存储引擎):事务型存储引擎,支持ACID特性;支持行级锁。适用大多数OLTP应用 MyISAM的特性与使用场景:不支持事务,表级锁。适用(1)非事务性应用 (2)只读型应用 (3)空间型应用 选择题选C
作者回复: 正确 & Geek总结的不错
2019-12-04

