

22丨反范式设计:3NF有什么不足,为什么有时候需要反范式设计?
陈旸

该思维导图由 AI 生成,仅供参考
上一篇文章中,我们介绍了数据表设计的三种范式。作为数据库的设计人员,理解范式的设计以及反范式优化是非常有必要的。
为什么这么说呢?了解以下几个方面的内容之后你就明白了。
3NF 有什么不足?除了 3NF,我们为什么还需要 BCNF?
有了范式设计,为什么有时候需要进行反范式设计?
反范式设计适用的场景是什么?又可能存在哪些问题?
BCNF(巴斯范式)
如果数据表的关系模式符合 3NF 的要求,就不存在问题了吗?我们来看下这张仓库管理关系 warehouse_keeper 表:
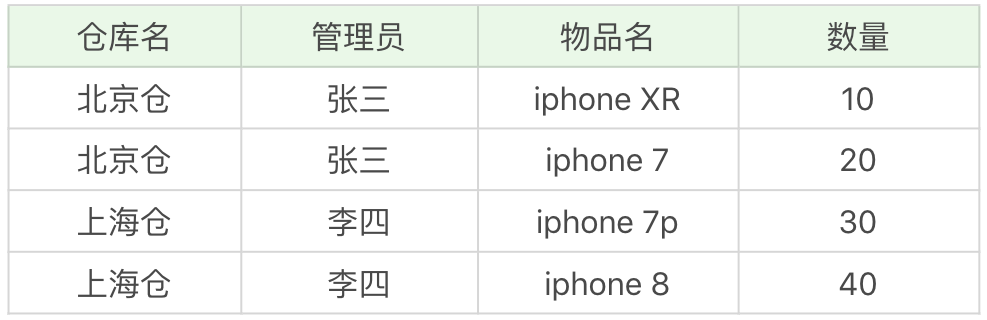
在这个数据表中,一个仓库只有一个管理员,同时一个管理员也只管理一个仓库。我们先来梳理下这些属性之间的依赖关系。
仓库名决定了管理员,管理员也决定了仓库名,同时(仓库名,物品名)的属性集合可以决定数量这个属性。
这样,我们就可以找到数据表的候选键是(管理员,物品名)和(仓库名,物品名),
然后我们从候选键中选择一个作为主键,比如(仓库名,物品名)。
在这里,主属性是包含在任一候选键中的属性,也就是仓库名,管理员和物品名。非主属性是数量这个属性。
如何判断一张表的范式呢?我们需要根据范式的等级,从低到高来进行判断。
首先,数据表每个属性都是原子性的,符合 1NF 的要求;其次,数据表中非主属性”数量“都与候选键全部依赖,(仓库名,物品名)决定数量,(管理员,物品名)决定数量,因此,数据表符合 2NF 的要求;最后,数据表中的非主属性,不传递依赖于候选键。因此符合 3NF 的要求。
公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结

本文深入介绍了数据库设计中的范式和反范式设计,重点讨论了BCNF(巴斯范式)的概念和应用,以及反范式设计对查询效率的提升。通过实验数据模拟了反范式优化的过程,展示了反范式设计的优势,即通过允许少量的数据冗余来换取查询效率的提升。文章指出范式和反范式设计各有适用场景,需要根据需求将二者混合使用。此外,还探讨了反范式设计在数据仓库中的应用,强调了数据仓库设计与数据库设计的区别。总的来说,本文通过理论讲解和实验演示,全面介绍了范式设计和反范式设计在数据库设计中的应用和优势,对于数据库设计人员具有一定的参考价值。
仅可试看部分内容,如需阅读全部内容,请付费购买文章所属专栏
《SQL 必知必会》,新⼈⾸单¥68
《SQL 必知必会》,新⼈⾸单¥68
立即购买
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
全部留言(26)
- 最新
- 精选
 DZ置顶一言以蔽之:反范式无处不在。😃 最近正在基于Hadoop建设某国企的数据集市项目(地域性非全网),恰如老师所言,我们就是在遵循反范式的设计。 简要来说,我们把数据加工链路分为四层,从下到上依次为:ODS贴源层、DWD明细层、DWS汇总层和ADS应用层。 多源异构的业务数据被源源不断ETL到ODS贴源层之后,经过清洗、规范、转换、拼接等,生成各类宽表存储在DWD明细层;再根据业务模型设计,以这些宽表为基础,生成各类标准的指标数据存储在DWS汇总层;ADS层则基于DWS层的汇总指标再度组合,计算得出应用层数据,直接面向业务需求。 在这样的系统设计中,反范式不仅体现在“宽表”的设计中,更体现在数据加工链路的完整生命周期中——上层都是对下层的冗余。
DZ置顶一言以蔽之:反范式无处不在。😃 最近正在基于Hadoop建设某国企的数据集市项目(地域性非全网),恰如老师所言,我们就是在遵循反范式的设计。 简要来说,我们把数据加工链路分为四层,从下到上依次为:ODS贴源层、DWD明细层、DWS汇总层和ADS应用层。 多源异构的业务数据被源源不断ETL到ODS贴源层之后,经过清洗、规范、转换、拼接等,生成各类宽表存储在DWD明细层;再根据业务模型设计,以这些宽表为基础,生成各类标准的指标数据存储在DWS汇总层;ADS层则基于DWS层的汇总指标再度组合,计算得出应用层数据,直接面向业务需求。 在这样的系统设计中,反范式不仅体现在“宽表”的设计中,更体现在数据加工链路的完整生命周期中——上层都是对下层的冗余。作者回复: 总结的不错
2019-07-31550 leslie个人对于反范式的理解是:它会造成数据的冗余甚至是表与表之间的冗余;不过它最大的好处是减少了许多跨表查询从而大幅减少了查询时间。早期的设计其实一直强调范式化设计,可是当memcache出现后-其实就反向在揭示范式的不足。 互联网行业和传统行业最大的区别是要求相应时间的短暂:这就造成了效率优先,这其实也是为何互联网行业的技术更新和使用走在最前面。曾经经历过设计表的过程中尽力追求范式,可是最终发现带来的问题就是性能的不足;范式其实就是规范,可是完完全全的规范-碰到特殊场景就不能那样使用。10年前接触到非关系型数据库时就引发了这种思考,sql server和mysql的机制和查询特长的不同更加引发了自己对于范式的反思。 其实不同数据库对于范式的操作应当是不同的不同行业对于效率的要求是不同的:我觉得范式与反范式的关系可能有点像现在关系型数据库和非关系型数据库的使用一样,已经不再是单一化,如何让二者合理结合最大发挥数据库的查询效率才是关键-只有最合适的没有最好的;当我们过度的追求标准化时反而会忽视了产品真实的功能者作用,如何充分合理发挥产品性能其实才是我们所追求的。 老师觉得呢:没有最标准的,任何方式都有缺陷,没有最好的只有最合适的;就像Google 的SRE中有句经典的话“没有问题的程序是程序的特殊状态”。
leslie个人对于反范式的理解是:它会造成数据的冗余甚至是表与表之间的冗余;不过它最大的好处是减少了许多跨表查询从而大幅减少了查询时间。早期的设计其实一直强调范式化设计,可是当memcache出现后-其实就反向在揭示范式的不足。 互联网行业和传统行业最大的区别是要求相应时间的短暂:这就造成了效率优先,这其实也是为何互联网行业的技术更新和使用走在最前面。曾经经历过设计表的过程中尽力追求范式,可是最终发现带来的问题就是性能的不足;范式其实就是规范,可是完完全全的规范-碰到特殊场景就不能那样使用。10年前接触到非关系型数据库时就引发了这种思考,sql server和mysql的机制和查询特长的不同更加引发了自己对于范式的反思。 其实不同数据库对于范式的操作应当是不同的不同行业对于效率的要求是不同的:我觉得范式与反范式的关系可能有点像现在关系型数据库和非关系型数据库的使用一样,已经不再是单一化,如何让二者合理结合最大发挥数据库的查询效率才是关键-只有最合适的没有最好的;当我们过度的追求标准化时反而会忽视了产品真实的功能者作用,如何充分合理发挥产品性能其实才是我们所追求的。 老师觉得呢:没有最标准的,任何方式都有缺陷,没有最好的只有最合适的;就像Google 的SRE中有句经典的话“没有问题的程序是程序的特殊状态”。作者回复: 总结和阐述的很好,大家都可以看下 “没有问题的程序是程序的特殊状态” 这个赞一下
2019-07-31254 Yuhui这个数据集都是百万条记录的,如果直接导入MySQL比较慢。如果先做以下设置会大大提高导入的速度: SET GLOBAL unique_checks=0; SET GLOBAL innodb_flush_log_at_trx_commit=0; SET GLOBAL sync_binlog=0; 当然这不是SQL的问题,是数据库工作方式的问题,不在本课讨论范围内,只是提供大家参考,节省准备的时间。 导入完成以后记得把所有设置都改回1。
Yuhui这个数据集都是百万条记录的,如果直接导入MySQL比较慢。如果先做以下设置会大大提高导入的速度: SET GLOBAL unique_checks=0; SET GLOBAL innodb_flush_log_at_trx_commit=0; SET GLOBAL sync_binlog=0; 当然这不是SQL的问题,是数据库工作方式的问题,不在本课讨论范围内,只是提供大家参考,节省准备的时间。 导入完成以后记得把所有设置都改回1。作者回复: 赞下Yuhui同学的分享
2019-09-1931 丁丁历险记反范式注意好同步。
丁丁历险记反范式注意好同步。作者回复: 同意
2019-12-288 董俊俊请问老师,冗余字段的更新有哪些方式啊?文中只是提到存储过程更新冗余字段
董俊俊请问老师,冗余字段的更新有哪些方式啊?文中只是提到存储过程更新冗余字段作者回复: 使用触发器,存储过程,或者自己写脚本自动执行更新都可以
2019-11-127- 夜路破晓范式与反范式,正如传统与解构,规则与务实,稳定与突破,守成与创新,是阴阳动静的矛盾关系,两者一而二,二而一,即和而不同、求同存异,落脚点是务实,也就是应用场景和业务需求。 所以说,这已经不单是数据库设计的问题,而中国哲学体系在互联网商业中实践指导。 数据库设计提出范式的同时存在反范式的要求,符合否定之否定的螺旋上升轨迹,是数据库也是SQL语言保持强壮生命力而经久不衰的重要原因,是现实生存逻辑的映射。
作者回复: 是的,很多设计思维都是相通的。不仅是正反两方面,有时候我们还会遇到 Exploit & Explore的问题,这个在探索未知世界,比如深度学习的收敛算法中会应用。
2019-07-316  川杰老师您好,想问个问题;假设我在存储过程中,用到了一个临时表(作用就是保存中间数据以便后续做其他操作),先对临时表进行数据删除操作,然后对临时表进行插入操作。假设现在有两个人A,B同时调用该存储过程,是否存在如下风险,即:A执行存储过程时,正在删除数据,同一时刻,B执行存储过程时,新增数据?
川杰老师您好,想问个问题;假设我在存储过程中,用到了一个临时表(作用就是保存中间数据以便后续做其他操作),先对临时表进行数据删除操作,然后对临时表进行插入操作。假设现在有两个人A,B同时调用该存储过程,是否存在如下风险,即:A执行存储过程时,正在删除数据,同一时刻,B执行存储过程时,新增数据?作者回复: 感谢提问,这种情况下会用到事务的隔离级别,MySQL的默认隔离级别是可重复读(Repeatable Read),数据同时删除,新增是不会有问题的。
2019-08-0135 梁olap可以用反范式,但oltp就不适合了,实时的交易和数据变化,反范式的空间换时间不适合
梁olap可以用反范式,但oltp就不适合了,实时的交易和数据变化,反范式的空间换时间不适合作者回复: 反范式在OLAP场景比较常见
2019-11-183- Cookie123456“”“在这里,主属性是包含在任一候选键中的属性,也就是仓库名,管理员和物品名。非主属性是数量这个属性。” 老师你你说的这句话我有点问题,按理说我们如果默认仓库名和物品名是候选键的话,那管理员就是非主属性, 候选键的一部分,也就是说仓库名可以推导出管理员,这不就存在局部依赖么。
作者回复: 感谢提问,不包含在任何一个候选键中的属性称为非主属性,所以管理员还不能算是非主属性,而属于候选键。
2020-03-272 - 博弈老师讲的浅显易懂,学完本章节,又重新温故了一下三范式。
作者回复: 哈哈 谢谢博弈同学
2020-03-252
收起评论

