

14 | 弹性分布式数据集:Spark大厦的地基(下)

该思维导图由 AI 生成,仅供参考
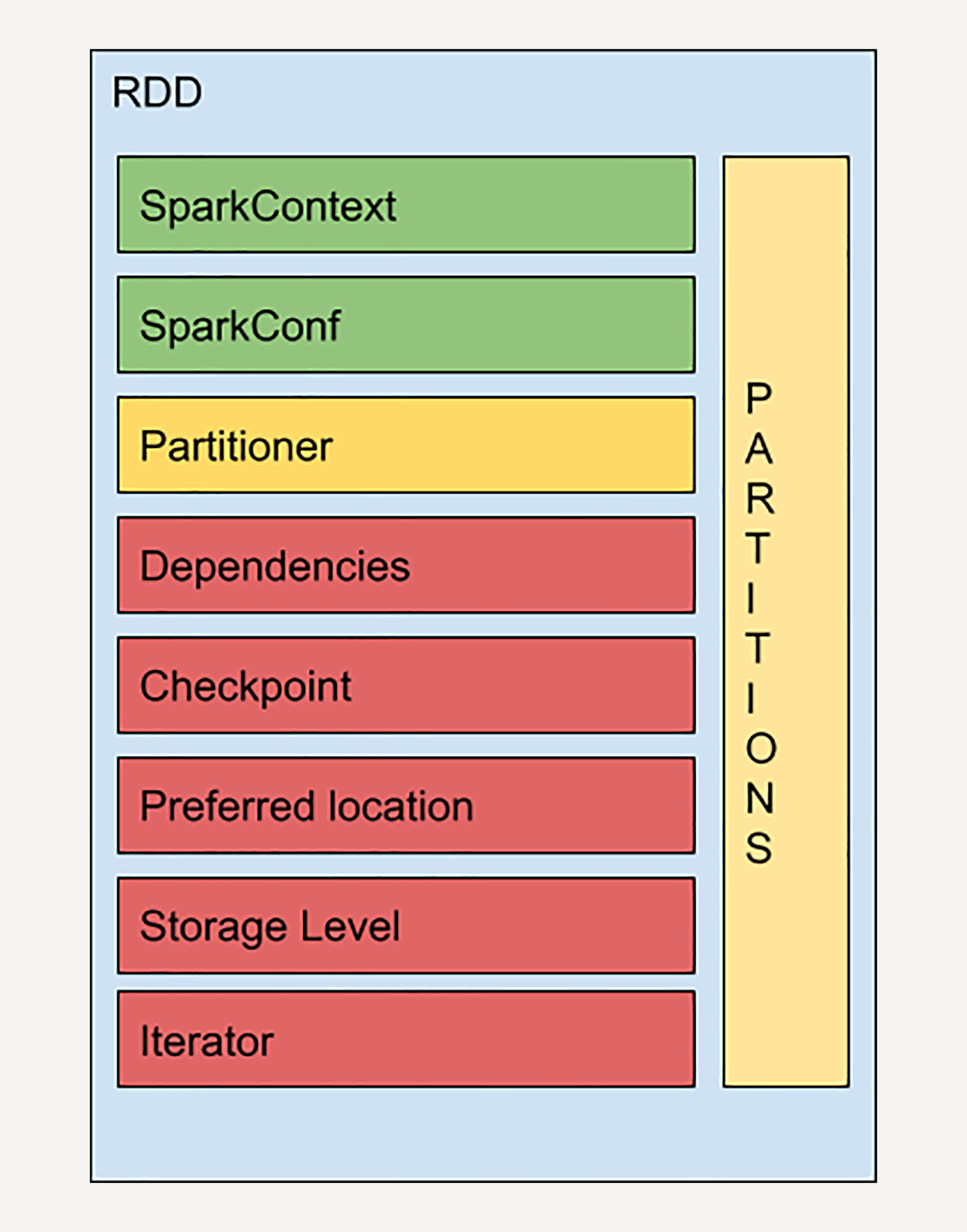
RDD 的结构
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

本文深入介绍了弹性分布式数据集(RDD)的结构和特性,包括RDD的持久化和缓存操作,以及其与记录Checkpoint的区别。文章首先详细介绍了RDD的结构,包括检查点、存储级别和迭代函数,强调了转换操作和动作操作的区别,以及Spark的惰性求值设计优势。接着,文章重点讲解了RDD的持久化操作,通过示例代码展示了如何提高Spark的计算效率,同时提及了持久化的存储级别选择和自动容错机制。此外,文章还总结了Spark在转换操作和动作操作中的计算逻辑链条,以及通过持久化处理提升计算效率的方法。最后,文章提出了思考题,引发读者对RDD的持久化操作和记录Checkpoint的区别进行思考和讨论。整体而言,本文通过详细介绍RDD的结构和操作,帮助读者快速了解了RDD的基本概念和使用方法,同时突出了Spark在计算效率和容错机制方面的优势。
《大规模数据处理实战》,新⼈⾸单¥59

全部留言(32)
- 最新
- 精选
 锦区别在于Checkpoint会清空该RDD的依赖关系,并新建一个CheckpointRDD依赖关系,让该RDD依赖,并保存在磁盘或HDFS文件系统中,当数据恢复时,可通过CheckpointRDD读取RDD进行数据计算;持久化RDD会保存依赖关系和计算结果至内存中,可用于后续计算。
锦区别在于Checkpoint会清空该RDD的依赖关系,并新建一个CheckpointRDD依赖关系,让该RDD依赖,并保存在磁盘或HDFS文件系统中,当数据恢复时,可通过CheckpointRDD读取RDD进行数据计算;持久化RDD会保存依赖关系和计算结果至内存中,可用于后续计算。作者回复: 👍🏻
2019-05-17462 RocWay主要区别应该是对依赖链的处理: checkpoint在action之后执行,相当于事务完成后备份结果。既然结果有了,之前的计算过程,也就是RDD的依赖链,也就不需要了,所以不必保存。 但是cache和persist只是保存当前RDD,并不要求是在action之后调用。相当于事务的计算过程,还没有结果。既然没有结果,当需要恢复、重新计算时就要重放计算过程,自然之前的依赖链不能放弃,也需要保存下来。需要恢复时就要从最初的或最近的checkpoint开始重新计算。
RocWay主要区别应该是对依赖链的处理: checkpoint在action之后执行,相当于事务完成后备份结果。既然结果有了,之前的计算过程,也就是RDD的依赖链,也就不需要了,所以不必保存。 但是cache和persist只是保存当前RDD,并不要求是在action之后调用。相当于事务的计算过程,还没有结果。既然没有结果,当需要恢复、重新计算时就要重放计算过程,自然之前的依赖链不能放弃,也需要保存下来。需要恢复时就要从最初的或最近的checkpoint开始重新计算。作者回复: 这位同学的理解是很准确的
2019-05-1730 hua168老师,我想问下,如果是linux 命令分析单机300G log日志,内存只有16G,怎搞? 如果用spark思想,,从io读很卡,直接内存爆了。 如果先分割日志为100份,再用shell,一下10个并发执行,最后结果合并。感觉还是有点慢。
hua168老师,我想问下,如果是linux 命令分析单机300G log日志,内存只有16G,怎搞? 如果用spark思想,,从io读很卡,直接内存爆了。 如果先分割日志为100份,再用shell,一下10个并发执行,最后结果合并。感觉还是有点慢。作者回复: 如果限定为单机处理,我觉得你的第二个思路是可行的,第一个行不通。
2019-05-1727- JohnT3e两者区别在于依赖关系是否保留吧。checkpoint的话,检查点之前的关系应该丢失了,但其数据已经持久化了;而persist或者cache保留了这个依赖关系,如果缓存结果有丢失,可以通过这个关系进行rebuild。
作者回复: 这位同学的理解很准确
2019-05-1725 - 挖矿的小戈1. 前者:persist或者cache除了除了持久化该RDD外,还会保留该RDD前面的依赖关系 2. 后者:将该RDD保存到磁盘上,并清除前面的依赖关系 感觉后者的开销会大很多
作者回复: 理解的很对
2019-05-174  miwucc手动调用缓存函数和checkpoint本质上是一样的吧。就是一个手动控制落盘时间,一个自动控制。
miwucc手动调用缓存函数和checkpoint本质上是一样的吧。就是一个手动控制落盘时间,一个自动控制。作者回复: 并不是,checkpoint会将一些RDD的结果存入硬盘,但是不会保留依赖关系;缓存函数或者持久化处理会保留依赖关系,所以错误恢复会更方便。
2019-05-173 廖师虎记不太清除了,checkpoint清除血缘关系,一般保存在类hdfs文件系统,目的是容错,缓存是保留血缘关系,并保存在本机,的目的是提高效率,High performance Spark书讲得很详细。 第一次遇到把driver翻译成驱动程序的,个人感觉还是保留Driver,Action为佳。
廖师虎记不太清除了,checkpoint清除血缘关系,一般保存在类hdfs文件系统,目的是容错,缓存是保留血缘关系,并保存在本机,的目的是提高效率,High performance Spark书讲得很详细。 第一次遇到把driver翻译成驱动程序的,个人感觉还是保留Driver,Action为佳。作者回复: 翻译也是为了方便英文不好的同学理解,但是每个名次第一次出现我都会标出英文。
2019-05-173 Steven缓存了之后,第一个action还是需要从头计算的吧? "所以无论是 count 还是 first,Spark 都无需从头计算", 这句话是不是有误?
Steven缓存了之后,第一个action还是需要从头计算的吧? "所以无论是 count 还是 first,Spark 都无需从头计算", 这句话是不是有误?作者回复: 你的观察很仔细,这里确实是笔误。持久化处理过的RDD只有第一次有action操作时才会从源头计算,之后就把结果存储下来。所以在这个例子中Count需要从源头开始计算,而first不需要。
2019-05-1732 joncheckpoint不会存储该rdd前面的依赖关系,它后面的rdd都依赖于它。 persist、 cache操作会存储依赖关系,当一个分区丢失后可以根据依赖重新计算。
joncheckpoint不会存储该rdd前面的依赖关系,它后面的rdd都依赖于它。 persist、 cache操作会存储依赖关系,当一个分区丢失后可以根据依赖重新计算。作者回复: 👍🏻
2019-05-172 cricket1981终于明白spark惰性求值的原理了。我理解对 RDD 进行持久化操作和记录 Checkpoint的区别是:前者是开发人员为了避免重复计算、减少长链路计算时间而主动去缓存中间结果,而后者是spark框架为了容错而提供的保存中间结果机制,它对开发人员是透明的,无感知的。
cricket1981终于明白spark惰性求值的原理了。我理解对 RDD 进行持久化操作和记录 Checkpoint的区别是:前者是开发人员为了避免重复计算、减少长链路计算时间而主动去缓存中间结果,而后者是spark框架为了容错而提供的保存中间结果机制,它对开发人员是透明的,无感知的。作者回复: 这些机制对开发者并不是透明的,开发者可以手动调用checkpoint和cache方法来存储RDD。他们的主要区别是是否存储依赖关系。
2019-05-172

