

10 | Lambda架构:Twitter亿级实时数据分析架构背后的倚天剑
该思维导图由 AI 生成,仅供参考
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

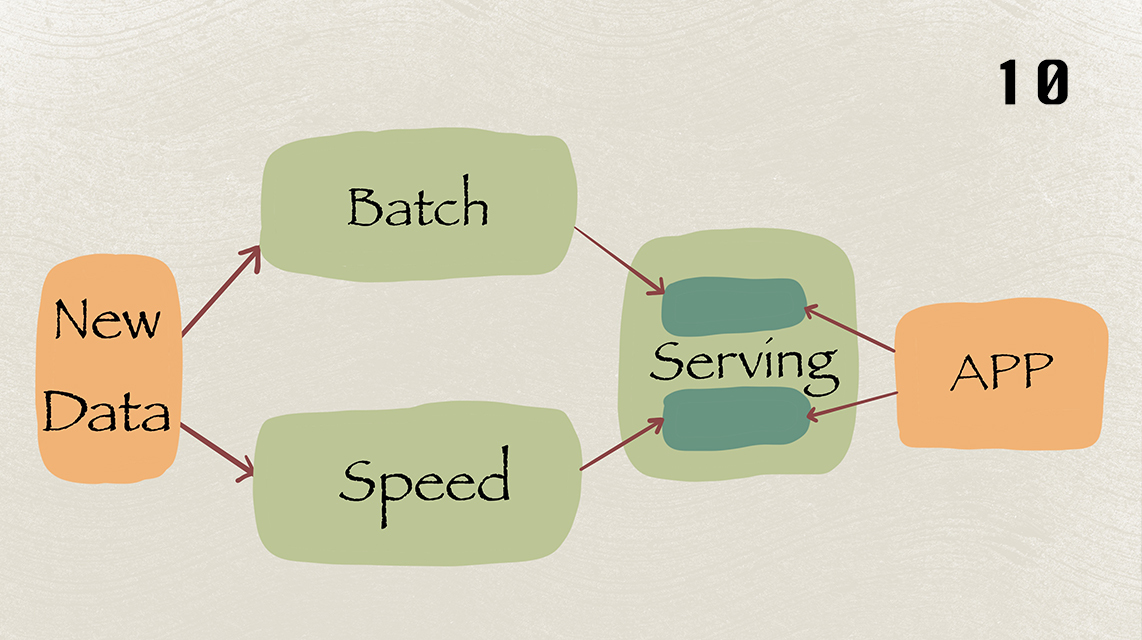
Lambda架构是Twitter亿级实时数据分析架构的核心,由批处理层、速度处理层和服务层组成。其灵活性和可扩展性使其成为处理大规模分布式数据的理想选择。在Twitter的数据分析案例中成功应用于实时分析Most Popular Hashtags,展现了其在实际场景中的灵活性和可靠性。Lambda架构适用于不同规模和阶段的数据场景,展现了其普适性和实用性。 在智能停车App中,Lambda架构可以应用于推荐停车位。通过批处理层处理停车场的历史数据和速度处理层处理实时GPS数据,结合预测模型,可以提升停车位推荐的准确率。Lambda架构的灵活性和可扩展性使其能够适应不同的数据处理场景。 Lambda架构具有很好的灵活性和可扩展性,能够方便地套用现有的开源平台,并具备良好的容错性。开发者可以迁移平台而无需改变整体架构,只需将逻辑迁移到新平台中。此外,Lambda架构也提供了纠正逻辑错误的机制,使得整体逻辑可以被修正。 在项目开发中,可以考虑利用Lambda架构来处理大规模分布式数据,提升数据处理的效率和准确性。生活中的大数据处理场景,如智能停车、广告精准投放等,也可以借助Lambda架构来实现实时数据分析和处理。 Lambda架构的应用不仅体现了其在实际场景中的灵活性和可靠性,也为开发者提供了思考现有架构改善的机会。作为一名优秀的架构师,思考现有架构的改善是一个需要经常思考的问题。 总之,Lambda架构在实时数据处理和分析方面具有广泛的应用前景,为处理大规模分布式数据提供了一种灵活、可靠的解决方案。
《大规模数据处理实战》,新⼈⾸单¥59

全部留言(45)
- 最新
- 精选
 :)我们公司做的实时数仓 就满足Lambda 架构。1.批处理部分。定时拉取业务库的数据,并在hive做批处理计算。 2.速度部分。通过订阅mysql数据库的binlog,实时获取数据库的增删改等的操作,通过kafka和flink,生成相关结果。
:)我们公司做的实时数仓 就满足Lambda 架构。1.批处理部分。定时拉取业务库的数据,并在hive做批处理计算。 2.速度部分。通过订阅mysql数据库的binlog,实时获取数据库的增删改等的操作,通过kafka和flink,生成相关结果。作者回复: 谢谢你的经验分享!
2019-05-08445- JohnT3elambda架构是不是可能会导致相似的处理逻辑在batch层和speed层都要开发一遍?
作者回复: 谢谢你的提问!没错,这也是Lambda架构的一个缺点,开发者必须要把同样的逻辑在两个地方维护,特别是当技术栈不一样的时候会很头疼。
2019-05-0839  命缘老师,想请问下服务层具体是怎们兼容批处理层和实时处理层的结果的,有没实际例子
命缘老师,想请问下服务层具体是怎们兼容批处理层和实时处理层的结果的,有没实际例子作者回复: 谢谢你的提问!之前有另外一个同学让我讲述一下广告精准投放的实际例子,我就引用一下那个回答吧。 广告投放预测这种推荐系统一般都会用到Lambda架构。一般能做精准广告投放的公司都会拥有海量用户特征、用户历史浏览记录和网页类型分类这些历史数据的。业界比较流行的做法有在批处理层用Alternating Least Squares (ALS)算法,也就是Collaborative Filtering协同过滤算法,可以得出与用户特性一致其他用户感兴趣的广告类型,也可以得出和用户感兴趣类型的广告相似的广告,而用k-means也可以对客户感兴趣的广告类型进行分类。这里的结果是批处理层的结果。在速度层中根据用户的实时浏览网页类型在之前分好类的广告中寻找一些top K的广告出来。最终服务层可以结合速度层的top K广告和批处理层中分类好的点击率高的相似广告,做出选择投放给用户。
2019-05-1522 leeon目前是通过Kafka将行为数据收集到hdfs,然后spark批处理t+1计算长期数据,生成固定格式的特征同步到kv上线,同时实时收集服务也从Kafka中消费最新的行为,两层输出特征格式统一,供画像服务使用
leeon目前是通过Kafka将行为数据收集到hdfs,然后spark批处理t+1计算长期数据,生成固定格式的特征同步到kv上线,同时实时收集服务也从Kafka中消费最新的行为,两层输出特征格式统一,供画像服务使用作者回复: 谢谢你的经验分享!
2019-05-08215 明翼简单又实用的lambda架构,如果实时和批量不能同时满足那就分开吧,用的时候综合下,让我想到现在开源的数据湖,delta data lake,如果批量和实时矛盾就分开吧,读写分,采用不同行式或列式存储,实时和历史分开,实时数据再定期变成历史,这个架构最大难点是如何合并speed和batch
明翼简单又实用的lambda架构,如果实时和批量不能同时满足那就分开吧,用的时候综合下,让我想到现在开源的数据湖,delta data lake,如果批量和实时矛盾就分开吧,读写分,采用不同行式或列式存储,实时和历史分开,实时数据再定期变成历史,这个架构最大难点是如何合并speed和batch作者回复: 谢谢你的经验之谈!
2019-05-0911 ¾关于为什么叫lamda架构有一个猜想。lamda的希腊字母是λ,这正好表示batch 和 speed两种最后汇聚到一起。不知道猜想对不对,但是感觉通过希腊字母,象形的代表架构模式还是挺有意思的。
¾关于为什么叫lamda架构有一个猜想。lamda的希腊字母是λ,这正好表示batch 和 speed两种最后汇聚到一起。不知道猜想对不对,但是感觉通过希腊字母,象形的代表架构模式还是挺有意思的。作者回复: 谢谢你的分享!Bingo,我觉得是完全正确的!以前在读技术文章的时候就看到过一种说法是:完整的数据集 = λ (实时数据) * λ (历史数据)。
2019-05-0928- Codelife原来这就是Lambda架构,其实,我们现在就用的Lambda 架构,kafka+storm+MR+Hbase来实现,现在的问题是: 1.storm是用java开发,MR是用python开发,导致同一逻辑需要两种实现 2.storm窗口期数据一般在5-10分钟,由于我们的数据有时间和空间属性的时序数据,前后关联性比较大,中间可能有噪点数据,所以很容易出现实时和历史分析结果不一致的问题,虽然最终用历史覆盖了实时,保持了最终一致性。
作者回复: 谢谢你的经验分享! 是的啊,有时候不知不觉就会发现自己原来就已经在使用了某个特定技术。这让我想起设计模式,早期阶段在代码中自己已经在实现某个设计模式了,但是因为那时候还没有系统地去学习设计模式,没察觉到而已。
2019-05-088  越甲非甲老师您好!lambda架构的思路中,感觉最终决定结果的还是批处理结果。而流处理结果更多的是满足实时性的需求。不同的业务场景下,综合两种处理结果获得对外服务的结果模型,其模型和算法应该都不相同。这种处理结果的合并方面,是否有某些原则范式或者思路呢?谢谢老师!
越甲非甲老师您好!lambda架构的思路中,感觉最终决定结果的还是批处理结果。而流处理结果更多的是满足实时性的需求。不同的业务场景下,综合两种处理结果获得对外服务的结果模型,其模型和算法应该都不相同。这种处理结果的合并方面,是否有某些原则范式或者思路呢?谢谢老师!作者回复: 您好,谢谢提问! 其实Lambda架构的应用场景最终还是会去服务同一种业务,毕竟流处理结果是对批处理结果延时的一种补偿。即便用到的算法不尽相同,但是合并的时候,最后存储的模型或者是存储数据的Schema都还是要一致的。
2019-05-088 yiwu实时报表,实时数仓,实时用户画像标签,实时反欺诈,实时风控,以前很多需要批量计算的数据都可以变成batch+speed或speed替代
yiwu实时报表,实时数仓,实时用户画像标签,实时反欺诈,实时风控,以前很多需要批量计算的数据都可以变成batch+speed或speed替代作者回复: 谢谢你的经验之谈!
2019-05-088 LJK老师您好,请问lambda架构可以看成一种在线学习的实现方式么?
LJK老师您好,请问lambda架构可以看成一种在线学习的实现方式么?作者回复: 您好,谢谢提问!可以的,Lambda架构不仅仅可以应用在在线学习上,有非常多应用场景都可以应用上。
2019-05-087

