

11 | Kappa架构:利用Kafka锻造的屠龙刀
该思维导图由 AI 生成,仅供参考
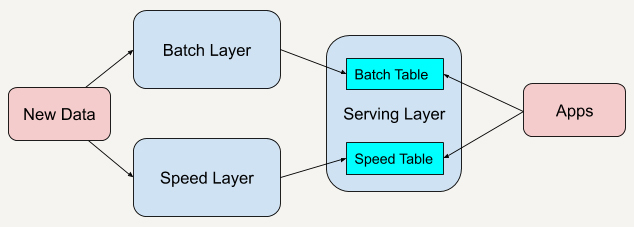
Lambda 架构的不足
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

Kappa架构是一种新兴的大规模数据处理架构,与传统的Lambda架构相比,Kappa架构去除了批处理层,仅保留速度层,通过改进系统性能来处理数据的完整性和准确性问题。该架构利用Apache Kafka的流处理平台,具有永久保存数据日志的功能,可通过重新处理历史数据改进逻辑算法。Kappa架构简化了系统维护,提供灵活性,并支持A/B测试,为大规模数据处理提供了新思路。《纽约时报》的内容管理系统架构实例展示了Kappa架构的应用。Kappa架构统一了开发接口,解决了API规范化问题,实现了实时数据传输,避免了轮询操作,同时具备重新读取所有内容的特性。然而,Kappa架构也存在一些不足,如在速度层处理大规模数据可能出现数据更新错误,且不适用于批处理和流处理代码逻辑不一致的场景。总之,Kappa架构适用于需要高实时性和灵活性的业务逻辑,而Lambda架构则更适合需要稳健机器学习模型的场景。
《大规模数据处理实战》,新⼈⾸单¥59

全部留言(44)
- 最新
- 精选
 程序设计的艺术有几个地方没太明白: 1.批处理数据具有很高的准确性,实时运算处理就没有? 2.关于数据错误,两者应该都有吧?数据错误后两者的处理不一样吗?比如10个任务中的3个有错误,批处理和实时处理都应该可以找到3个任务重新计算吧? 为什么实时运算需要完全从头计算所有任务? 谢谢
程序设计的艺术有几个地方没太明白: 1.批处理数据具有很高的准确性,实时运算处理就没有? 2.关于数据错误,两者应该都有吧?数据错误后两者的处理不一样吗?比如10个任务中的3个有错误,批处理和实时处理都应该可以找到3个任务重新计算吧? 为什么实时运算需要完全从头计算所有任务? 谢谢作者回复: 谢谢你的提问! 1. 批处理和实时运算中的处理肯定都具有准确性的,只是这里所说的高准确性是批处理结果相对于流处理结果而言的,因为毕竟批处理所处理的数据是历史数据。举个例子,假设我们拥有一个人近几年的上班目的地的历史数据,大部分时间这个人上班都在A地,只有少部分时间在B地。那批处理层所处理完这些历史数据之后可能会判断出这个人的常规上班地点是A,出差地点是B。如果是实时处理的话,可能刚好拿到的数据就是出差的那几天地点B,那实时处理的判断可能会判断出这个人的常规上班地点是B了。所以相对而言,批处理具有高准确性。 2. 无论是数据出错或者还是逻辑出错,批处理和实时处理肯定都会发生的。流处理的处理方式并不是按照任务为单位来计算的,通常都是把每一份数据当作是一个消息,流入的消息处理过了就不会再回头了。批处理的处理方式就是不断的有定时任务去重新处理所有历史数据。在Kappa架构下,除非你的logging做得非常好,能够知道在从哪一个数据时间点上出错了,那就把offset调回那个点重新从那个点开始重新计算。如果是逻辑有所改变了,那肯定是要全部数据从头完全重新计算了。
2019-05-10227 朱同学我感觉这是用队列代替了hdfs
朱同学我感觉这是用队列代替了hdfs作者回复: 谢谢你的留言!哈哈,可以这么理解,而且这个队列还必须具有重新处理所有历史数据的能力。
2019-05-11323 :)1.kappa架构使用更少的技术栈,实时和历史部分都是同一套技术栈。lambda架构为了解决历史部分和实时部分可能会使用不同的技术栈。 2.kappa架构使用了统一的处理逻辑。而lambda架构分别为历史和实时部分使用了两套逻辑。一旦需求变更,两套逻辑都要同时变更。 3.kappa架构具有流式处理的特点和优点。比如可以具有多个订阅者,比如具有更高的吞吐量。
:)1.kappa架构使用更少的技术栈,实时和历史部分都是同一套技术栈。lambda架构为了解决历史部分和实时部分可能会使用不同的技术栈。 2.kappa架构使用了统一的处理逻辑。而lambda架构分别为历史和实时部分使用了两套逻辑。一旦需求变更,两套逻辑都要同时变更。 3.kappa架构具有流式处理的特点和优点。比如可以具有多个订阅者,比如具有更高的吞吐量。作者回复: 谢谢你的留言!不错的总结!
2019-05-1021 Rainbowspark算kappa架构吗?批处理 流处理一套
Rainbowspark算kappa架构吗?批处理 流处理一套作者回复: 谢谢你的提问!Spark不算Kappa架构,Spark是有能力可以处理批处理和流处理,我们可以利用Spark搭建Kappa架构出来,但是它本身不具备这种架构的思想在里面。这就好比我们可以借助编程语言实现一些算法,但是我们不会说这种编程语言就属于这种算法一样。
2019-05-1018 Tl有个问题不明白,实时数据量很大的化,每次都从头计算,是否削弱了速度层实时性的特点,这样不和初心违背了么?
Tl有个问题不明白,实时数据量很大的化,每次都从头计算,是否削弱了速度层实时性的特点,这样不和初心违背了么?作者回复: 谢谢你的提问!Kappa架构是具有从头计算的能力,但是这个架构并不太适用于需要经常重新计算历史数据的应用场景。当我们发现有重大逻辑错误出现或者修改的时候才会从头计算所有的数据。
2019-05-17210 孙稚昊这样批和流的压力就全压到kafka 上了,对kafka并发的要求也非常高,应该只有kafka 能做到这件事了吧
孙稚昊这样批和流的压力就全压到kafka 上了,对kafka并发的要求也非常高,应该只有kafka 能做到这件事了吧作者回复: 谢谢你的留言!是的呢,现在只有用Kafka来实现Kappa架构。
2019-05-108 CoderLean不可能啊,如果要保存长久的数据,那么kafka的集群容量得有多大,按每天就一个t来说,加上默认副本3,那一年要存的数据量就得很多了。 这还可能只是其中一个业务。国内有小公司敢这样做吗
CoderLean不可能啊,如果要保存长久的数据,那么kafka的集群容量得有多大,按每天就一个t来说,加上默认副本3,那一年要存的数据量就得很多了。 这还可能只是其中一个业务。国内有小公司敢这样做吗作者回复: 谢谢你的留言!你说得也没有错,现在硅谷这边实践得比较多的可能就Linkedin或者Confluent了。
2019-05-1027 西南偏北如果批处理比较多的话,每次都从kafka的earlist offset消费的话,第一会耗费很长很长时间,而且消费者如果资源不够多,会导致任务堆积的吧。所以kappa不适合批处理多的架构。 Kappa架构因为整合了批处理层和速度层,优势就是: 1. 实时性比较高,适合对实时性要求高的场景 2. 业务逻辑可以使用统一的API来编写,那么对于之后的业务需求变更和代码维护都比较友好
西南偏北如果批处理比较多的话,每次都从kafka的earlist offset消费的话,第一会耗费很长很长时间,而且消费者如果资源不够多,会导致任务堆积的吧。所以kappa不适合批处理多的架构。 Kappa架构因为整合了批处理层和速度层,优势就是: 1. 实时性比较高,适合对实时性要求高的场景 2. 业务逻辑可以使用统一的API来编写,那么对于之后的业务需求变更和代码维护都比较友好作者回复: 谢谢你的留言总结!是的,现在Kappa架构用得比较多的是Confluent的数据平台,不过他们也没有放出Benchmark,具体和Lambda相比性能差距多少还不确定。不过我赞同你说kappa不适合批处理多的架构,毕竟如果常常要重做批处理的话,性能肯定会受影响的。
2019-05-106 又双叒叕是一年啊处理这种大数据量有窗口期的比如近30天的任务聚合计算可以用这种模式吗?是需要用kafka stream?每天都需要计算一次近30天的任务计算全量数据很大都是离线日志产生的数据
又双叒叕是一年啊处理这种大数据量有窗口期的比如近30天的任务聚合计算可以用这种模式吗?是需要用kafka stream?每天都需要计算一次近30天的任务计算全量数据很大都是离线日志产生的数据作者回复: 谢谢你的提问!按照你的说法你的应用需求是需要定时处理离线数据的,Kappa还是不太适合这种应用场景。这种应用场景可以用crontab加batch job完成。
2019-05-164 Zoe老师,请问一下,纽约时报这个例子,是不是每次只处理delta部分而不是把log offset设成0更好一些? 我粗浅的理解是可以把batch layer想成一个cache,感觉这种基于time series的每次只需要处理new data的部分再把结果和之前的cache聚合在一起就可以了? 还是说业界普遍的做法都是从头开始处理,因为相较于找delta考虑overlap的困难就不那么意额外的处理时间和机器运行的成本?
Zoe老师,请问一下,纽约时报这个例子,是不是每次只处理delta部分而不是把log offset设成0更好一些? 我粗浅的理解是可以把batch layer想成一个cache,感觉这种基于time series的每次只需要处理new data的部分再把结果和之前的cache聚合在一起就可以了? 还是说业界普遍的做法都是从头开始处理,因为相较于找delta考虑overlap的困难就不那么意额外的处理时间和机器运行的成本?作者回复: 谢谢你的提问!你的理解没有错,一般来说是只处理delta部分就可以了。需要从头开始处理的场景一般都是在发现之前的逻辑有重大的错误或者说新加了一些字段需要backfill以前的数据。
2019-05-293

