

27 | Pipeline I/O: Beam数据中转的设计模式
蔡元楠

该思维导图由 AI 生成,仅供参考
你好,我是蔡元楠。
今天我要与你分享的主题是“Pipeline I/O: Beam 数据中转的设计模式”。
在前面的章节中,我们一起学习了如何使用 PCollection 来抽象封装数据,如何使用 Transform 来封装我们的数据处理逻辑,以及 Beam 是如何将数据处理高度抽象成为 Pipeline 来表达的,就如下图所示。
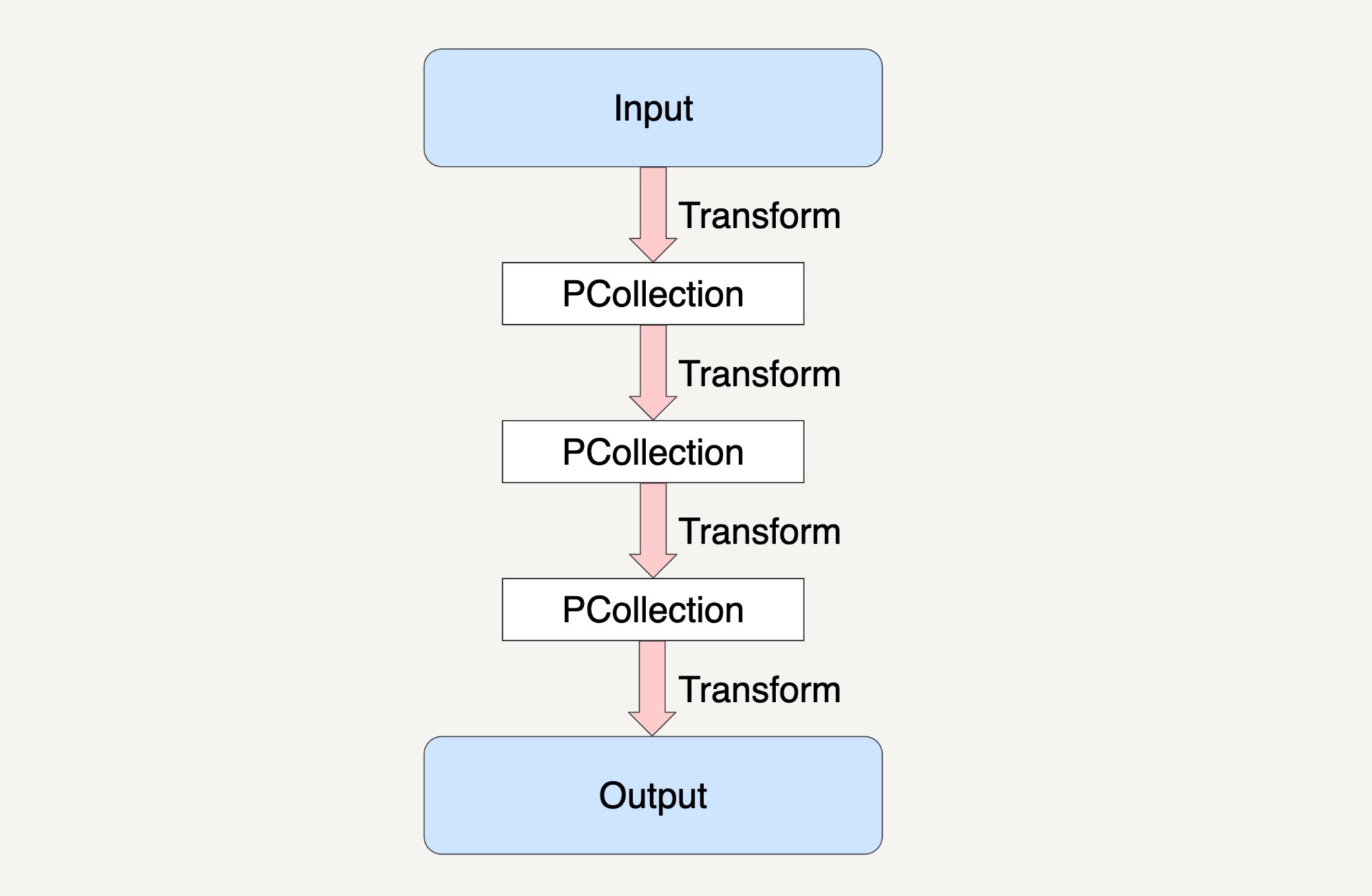
讲到现在,你有没有发现我们还缺少了两样东西没有讲?没错,那就是最初的输入数据集和结果数据集。那么我们最初的输入数据集是如何得到的?在经过了多步骤的 Transforms 之后得到的结果数据集又是如何输出到目的地址的呢?
事实上在 Beam 里,我们可以用 Beam 的 Pipeline I/O 来实现这两个操作。今天我就来具体讲讲 Beam 的 Pipeline I/O。
读取数据集
一个输入数据集的读取通常是通过 Read Transform 来完成的。Read Transform 从外部源 (External Source) 中读取数据,这个外部源可以是本地机器上的文件,可以是数据库中的数据,也可以是云存储上面的文件对象,甚至可以是数据流上的消息数据。
Read Transform 的返回值是一个 PCollection,这个 PCollection 就可以作为输入数据集,应用在各种 Transform 上。Beam 数据流水线对于用户什么时候去调用 Read Transform 是没有限制的,我们可以在数据流水线的最开始调用它,当然也可以在经过了 N 个步骤的 Transforms 后再调用它来读取另外的输入数据集。
公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结

Beam数据处理框架的Pipeline I/O设计模式为读取和输出数据集提供了灵活的解决方案。通过Pipeline I/O,可以轻松地从外部源读取数据,并将结果数据集输出到任意步骤。文章介绍了如何使用Beam的Pipeline I/O来实现这两个操作,包括从不同外部源读取数据和将结果数据输出到文件。此外,还介绍了Beam原生支持的I/O连接器以及如何自定义I/O连接器来满足特定需求。自定义I/O连接器可以通过实现Read Transform和Write Transform来实现对有界和无界数据集的读取操作。文章深入浅出地介绍了Beam数据中转的设计模式,为读者提供了全面的技术指导。总的来说,Beam的Pipeline I/O设计模式为数据处理提供了灵活、可扩展的解决方案,使得读者能够快速了解并应用于实际场景中。
仅可试看部分内容,如需阅读全部内容,请付费购买文章所属专栏
《大规模数据处理实战》,新⼈⾸单¥59
《大规模数据处理实战》,新⼈⾸单¥59
立即购买
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
全部留言(3)
- 最新
- 精选
 cricket1981自定义输入输出能个代码示例吗?按时间分区以parquet格式写入hdfs,代码要怎么写?2019-07-173
cricket1981自定义输入输出能个代码示例吗?按时间分区以parquet格式写入hdfs,代码要怎么写?2019-07-173 Mr.Tree之前讲PCollection不会写磁盘,读取操作时,会将读取的结果全部存入到一个PCollection里面,如果返回的数据很巨大,或者说读取的数据是无边界的,该如何处理?2023-02-15归属地:四川
Mr.Tree之前讲PCollection不会写磁盘,读取操作时,会将读取的结果全部存入到一个PCollection里面,如果返回的数据很巨大,或者说读取的数据是无边界的,该如何处理?2023-02-15归属地:四川 Junjie.M一个pipeline可以有多个input和output吗2020-04-111
Junjie.M一个pipeline可以有多个input和output吗2020-04-111
收起评论

