

07 | Workflow设计模式:让你在大规模数据世界中君临天下
蔡元楠
该思维导图由 AI 生成,仅供参考
你好,我是蔡元楠。
今天我要与你分享的主题是“Workflow 设计模式”。
在上一讲中,我们一起学习了大规模数据处理的两种处理模式——批处理和流处理。
利用好这两种处理模式,作为架构师的你就可以运筹帷幄,根据实际需求搭建出一套符合自己应用的数据处理系统。
然而,光是掌握了这两种数据处理模式就足够自如应对大规模数据世界中的需求挑战吗?从我的实战经验中看来,其实未必。
我们每个人在最开始学习大规模数据处理的时候,可能都是以 WordCount 作为教学例子来进行学习的。
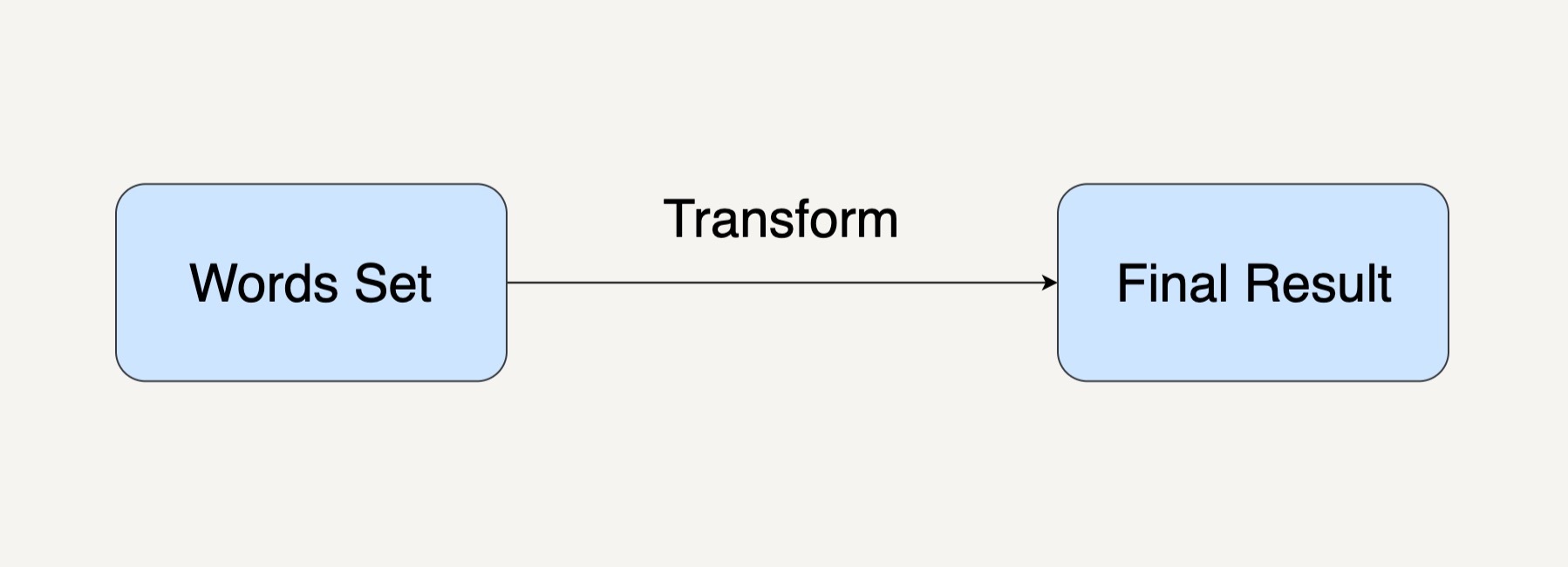
WordCount 这个例子,只需要一个单词集合作为输入,数据处理的结果是统计单词出现的次数,中间只需要经过一次数据处理的转换,就如同下图所示。
但在现实的应用场景种中,各式各样的应用需求决定了大规模数据处理中的应用场景会比 WordCount 复杂很多倍。
我还是以我在第一讲中所提到过的例子来说明吧。
在根据活跃在街头的美团外卖电动车的数量来预测美团的股价这个例子中,我们的输入数据集有可能不止一个。
例如,会有自己团队在街道上拍摄到的美团外卖电动车图片,会有第三方公司提供的美团外卖电动车数据集等等。
整个数据处理流程又会需要至少 10 个处理模块,每一个处理模块的输出结果都将会成为下一个处理模块的输入数据,就如同下图所示。
公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结

大规模数据处理中的Workflow设计模式是架构师在应对复杂数据处理需求时的得力工具。本文介绍了四种设计模式:复制模式、过滤模式、分离模式和合并模式。复制模式适用于对同一数据集进行多种不同处理转换,如YouTube视频平台的多分辨率视频处理;过滤模式用于筛选符合特定条件的数据,比如商城会员系统中对钻石会员的邮件邀请;分离模式则将数据按类别分类处理,如商城会员系统中根据会员等级发送不同活动邀请;而合并模式则将多个数据集整合成一个总数据集进行处理,如处理美团外卖电动车数量数据。这些设计模式为架构师提供了灵活的工具,帮助他们在设计大规模数据处理系统时有条不紊地规划工作流程。
仅可试看部分内容,如需阅读全部内容,请付费购买文章所属专栏
《大规模数据处理实战》,新⼈⾸单¥59
《大规模数据处理实战》,新⼈⾸单¥59
立即购买
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
全部留言(27)
- 最新
- 精选
 third用户注册,入库,合并模式 购买机票,分为查询机票和购买 查询机票,读取特定机票,过滤模式 购买机票,将所有渠道的票和合并起来,合并模式 24小时提醒,过滤出这班航班的机票,过滤模式 发送短信和电子邮箱,复制模式之后,进行分类模式发送
third用户注册,入库,合并模式 购买机票,分为查询机票和购买 查询机票,读取特定机票,过滤模式 购买机票,将所有渠道的票和合并起来,合并模式 24小时提醒,过滤出这班航班的机票,过滤模式 发送短信和电子邮箱,复制模式之后,进行分类模式发送作者回复: 总结得很好!
2019-05-0185 monkeyking这几个模式就是sql的几个operator吗? 复制 → subquery 过滤 → where 分离 → group by 合并 → join
monkeyking这几个模式就是sql的几个operator吗? 复制 → subquery 过滤 → where 分离 → group by 合并 → join作者回复: 谢谢你的留言!感觉我又学习到了,计算机的很多底层思想确实都是相通的。
2019-05-05348- 挖矿的小戈1. 注册:合并模式(因为注册渠道可能会有手机号注册、邮箱注册、微信注册等等不同的渠道,所以需要合并) 2. 购买机票:过滤+合并(首先过滤出用户查找的航班机票信息、之后查找出符合条件的机票由于可能来自不同的渠道,所有需要合并后返回给用户) 3. 提醒:复制+过滤+分离 过滤:根据时间、地点等因素过滤出需要给予提醒的用户 and 机票 复制:有可能需要对同一份数据(勾选多种提醒方式的用户)进行不同的处理(邮件通知 or 电话通知 or 短信通知) 分离:将前面过滤出的用户进行分成3组,分别对应(邮件通知 + 电话通知 +短信通知) 请大佬指教,理解有误没
作者回复: 谢谢大佬的答案!理解基本无误的!
2019-05-0131  缪斯用户注册需要用到合并模式(不同客户端),购票过程需要用到过滤模式(对时间地点进行筛选过滤选票),提醒需要用到分离模式(进行不同渠道的分发提醒通知,如短信,电话等)。
缪斯用户注册需要用到合并模式(不同客户端),购票过程需要用到过滤模式(对时间地点进行筛选过滤选票),提醒需要用到分离模式(进行不同渠道的分发提醒通知,如短信,电话等)。作者回复: 谢谢你的答案!
2019-05-018- nuclear感觉合并模式可能会有问题,如果两个流有差速怎么办?
作者回复: 谢谢你的提问,这个问题问得很好!对于有边界数据来说,也就是批处理,如果是读取两个流有速度上的误差是没有关系。如果你问的是无边界数据,那种有无止境数据的流处理的话,这里需要要求你在数据完整性和结果的延时上作出取舍了。具体的内容我会在介绍Beam的时候讲到。
2019-06-055 - linkzhang极客星球评论功能不好用啊(汗) 请问老师,看到很多回答里面都提到,提醒功能需要用到复制模式,但我理解只需要过滤和分离,过滤出需要提醒的用户后,如果一个用户需要多种方式通知,在分离的过程中是不是已经隐含了复制数据,不然上面的例子中,一个数据无法通过分离模式输入到两个处理模块
作者回复: 谢谢你的留言!其实还是需要用到复制模式的,分离的过程只是将用户划分在不同的类别中。如果同一个用户需要两种或以上的方式通知,那我们就需要把同一个用户采用复制模式复制到不同的模块中去处理了。
2019-06-023  珅剑workflow是否只适用于批处理?
珅剑workflow是否只适用于批处理?作者回复: 谢谢你的提问!Workflow作为一种数据处理设计思想是既适用于批处理也适用于流处理的。
2019-05-091 james题目用mq可以搞定,没啥模式信手拈来
james题目用mq可以搞定,没啥模式信手拈来作者回复: 谢谢你的答案!就问问你mq消息发丢了怎么办?
2019-05-0421 明翼注册如果多个系统对新用户都处理就复制,如果按照区域注册可能是分离模式,购买不知道是否有根据会员等级提供不同服务的如果有那就分离,买不同地方这个高并发先过滤到不同机器?至于通知,合并模式多个购买渠道信息合并一起通知所有用户
明翼注册如果多个系统对新用户都处理就复制,如果按照区域注册可能是分离模式,购买不知道是否有根据会员等级提供不同服务的如果有那就分离,买不同地方这个高并发先过滤到不同机器?至于通知,合并模式多个购买渠道信息合并一起通知所有用户作者回复: 总结得不错!
2019-05-011 朱同学如果用户从注册到购买到提醒是一个工作流的话,那么注册到购买是合并模式,因为并发的购买请求可能需要进入队列排队,到提醒的话,考虑到推送实时性,我会选择分类模式,如果系统按照整分钟推送,我会将未来几天的每分钟作为一个分类,下单处理完成后,我会把新的订单集合通过复制模式分发给不同的处理分支,推送只是其中的一个分支,推送提醒处理就是把订单分到以分钟为单位分类中,到了整分推送时间直接推送对应的分类即可。
朱同学如果用户从注册到购买到提醒是一个工作流的话,那么注册到购买是合并模式,因为并发的购买请求可能需要进入队列排队,到提醒的话,考虑到推送实时性,我会选择分类模式,如果系统按照整分钟推送,我会将未来几天的每分钟作为一个分类,下单处理完成后,我会把新的订单集合通过复制模式分发给不同的处理分支,推送只是其中的一个分支,推送提醒处理就是把订单分到以分钟为单位分类中,到了整分推送时间直接推送对应的分类即可。作者回复: 谢谢你的答案,分析得很不错!
2019-05-011
收起评论

