

05 | 分布式系统(下):架构师不得不知的三大指标

该思维导图由 AI 生成,仅供参考
可扩展性
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

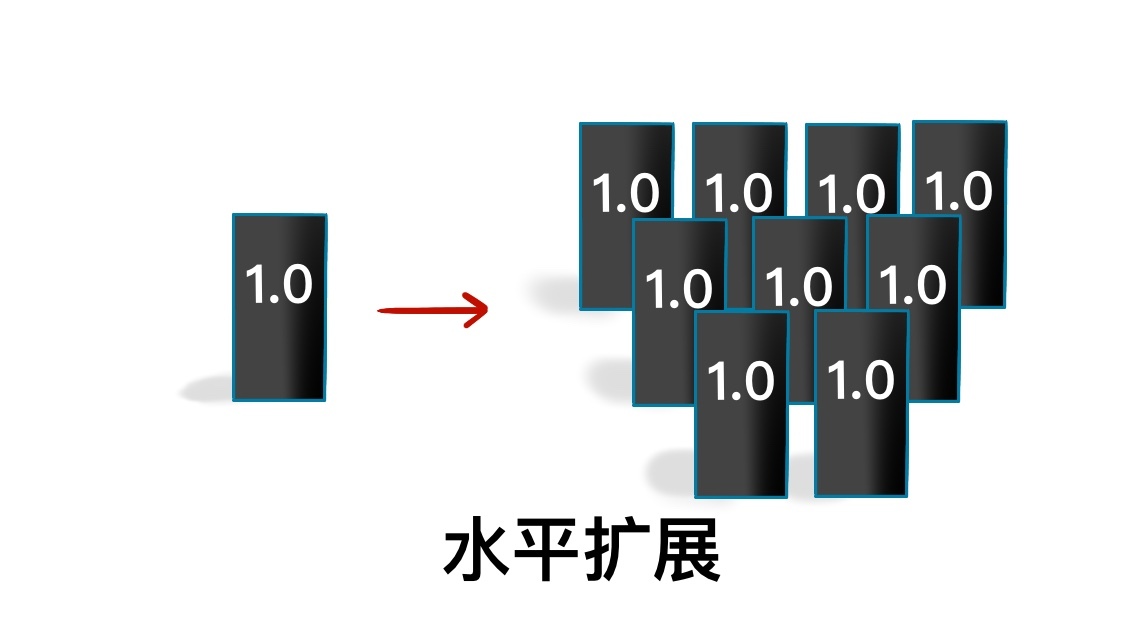
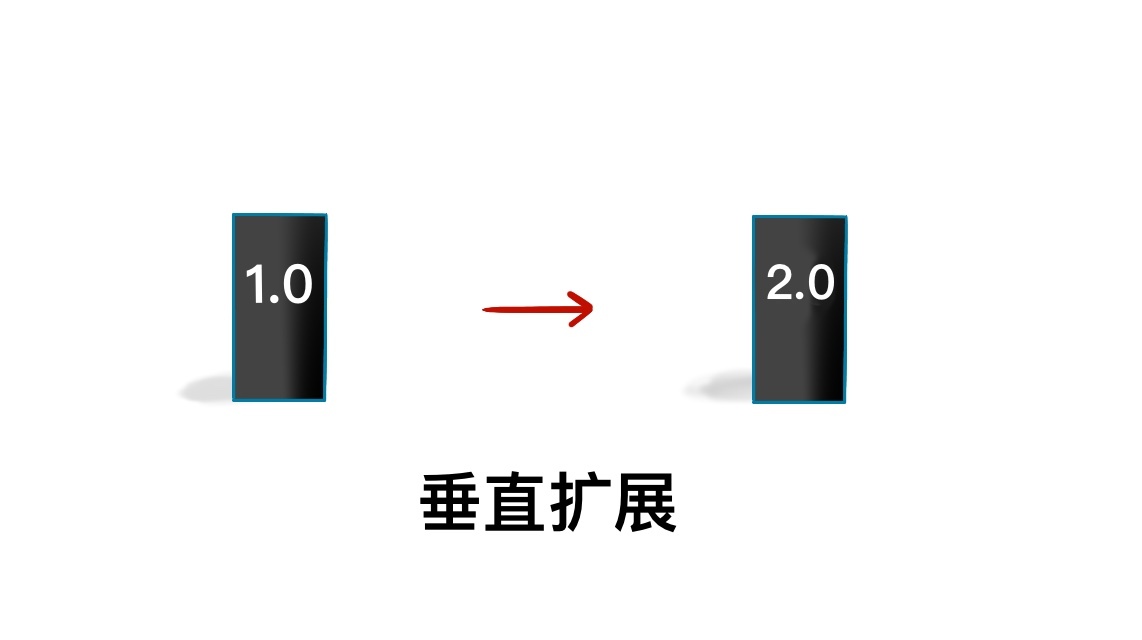
分布式系统的设计中,可扩展性、一致性和持久性是三大关键指标。可扩展性涵盖水平扩展和垂直扩展模型,适应大数据时代的数据存储需求。一致性包括强一致性、弱一致性和最终一致性模型,对系统可用性至关重要。数据持久性确保数据一旦存储成功就可以持续使用,包括数据复制和消息持久性等概念。这些指标对架构设计和评估分布式系统至关重要,有助于读者快速了解分布式系统的关键概念和技术特点。在实际应用中,系统架构师需要具体情况具体分析,找到最适合系统的指标,适当做出取舍。对于微信朋友圈的评论功能,需要考虑哪种一致性模型更适用,并思考其原因。这些讨论有助于深入理解分布式系统设计的复杂性和挑战,为读者提供了有益的思考和学习机会。
《大规模数据处理实战》,新⼈⾸单¥59

全部留言(34)
- 最新
- 精选
 3SKarl老师,我不太明白弱一致性和最终一致性的区别在哪里,文章对弱一致性提到 “经过不一致时间窗口这段时间后,后续对该数据的读取都是更新后的值” 这句描述的不就是最终一致性么 是不是说弱一致性允许数据始终不一致,而要求最终结果一致的弱一执性叫做最终一致性
3SKarl老师,我不太明白弱一致性和最终一致性的区别在哪里,文章对弱一致性提到 “经过不一致时间窗口这段时间后,后续对该数据的读取都是更新后的值” 这句描述的不就是最终一致性么 是不是说弱一致性允许数据始终不一致,而要求最终结果一致的弱一执性叫做最终一致性作者回复: 你好,这是个很棒的问题。简而言之,弱一致性是个很宽泛的概念,它是区别于强一致性而定义的。广义上讲,任何不是强一致的,而又有某种同步性的分布式系统,我们都可以说它是弱一致的。而最终一致性是弱一致性的一个特例,而且是最常被各种分布式系统用到的一个特例。其他的比如因果一致性、FIFO一致性等都可以看作是弱一致性的特例,不同弱一致性只是对数据不同步的容忍程度不同,但是经过一段时间,所有节点的数据都要求要一致。 学习时也没必要抠字眼,重要的是理解它们的区别。这部分知识是为了后边讲CAP理论服务的,实际的工作中不会像考试考概念题一样让你背写这些一致性的定义。 如果你还有疑问,欢迎继续留言。
2019-04-2640 leeon朋友圈保证最终一致性即可,消息发布后,先保证“端”是可见的,等待网络请求后会确认最终有无发布成功,成功后最终其他人的timeline会收到
leeon朋友圈保证最终一致性即可,消息发布后,先保证“端”是可见的,等待网络请求后会确认最终有无发布成功,成功后最终其他人的timeline会收到作者回复: 你的想法很好,但是有的场景下最终一致性还不够。试想这个场景,A发布了一张图片,B问他这是哪里,然后C回答B这里是北京。这个例子中,C的评论一定要在B之后,因为他俩有逻辑上的因果关系。所以微信朋友圈的评论要满足这样的因果一致性。因果一致性也是弱一致性的一个特例,感兴趣的话可以去多搜索点资料来学习~
2019-04-26320 hua168老师我想问一下,所谓的强一致性,它允许的误差是多少范围? 比如金融股票大厅显示屏数据,应该是强一致性的吧,全球显示误差不会超过0.2s吧? 这样强一致性怎达到?网络传输,路由处理都不止了,更何况还有网络延迟
hua168老师我想问一下,所谓的强一致性,它允许的误差是多少范围? 比如金融股票大厅显示屏数据,应该是强一致性的吧,全球显示误差不会超过0.2s吧? 这样强一致性怎达到?网络传输,路由处理都不止了,更何况还有网络延迟作者回复: 谢谢你的提问!强一致性并没有误差可言的,强一致性简单地说指的就是如果更新一条数据,那所有用户读取数据的时候必须都看到这条更新了的数据。 在这里我也分享一个自己的面试经历。其实这个问题恰好我当年在面试Bloomberg的时候面到过,是一道系统设计题。问的大概是在设计他们家股票信息系统的时候,数据的更新写入量太大,用户也需要读取最新的股票资讯,该如何设计这套系统。最后和它家的tech lead讨论发现,原来他们的股票系统显示的延迟范围是1分钟左右,因为应用场景上普通股民并不会需要实时关心每秒钟股票价格的动态,更多的是关心大盘走势。而金融巨头在操作股票的时候更多只关心特定的几只股票,所以这些股票的价格通常对于他们来说会更新快一点。 所以说金融股票大厅上的数据应该不会是强一致性的,延时误差也应该没有你想象的那么少。
2019-04-30312 Flash老师,消息队列的持久性第二点不是太能理解,意思是说消息发送者发完消息后,接收者下线了,然后接收者上线仍能收到吗?
Flash老师,消息队列的持久性第二点不是太能理解,意思是说消息发送者发完消息后,接收者下线了,然后接收者上线仍能收到吗?作者回复: 谢谢你的提问!没错,这里的持久性指的就是消息队列在接收到发送者发送的消息后,只要没有收到接收者的回应,就会一直尝试发送消息给接收者,直到收到回应为止。所以接收者下线了再上线仍是能收到消息队列发送的消息。当然中间如果超过了消息保留期限或者一定的重发次数也会消息队列也会停止发送。
2019-05-067 明翼笔记总结:扩展性包括水平和垂直,水平扩展是增加水平类似的机器打群架方式,垂直扩展是现有的每个人提升实力,提升整体实力;一致性,集群上的数据为了保证高可用性显然要存在不同机器上存多份,这就存在不同机器数量同步问题,要求同步造成才可以进行读写的就是最终一致性,中间准许有个不一致时间窗的就是弱一致性,时间窗更长但是最终会统一的就是最终一致性,比如发微博场景,还讲了数据持久性,消息的持久性,一般类似kafka之类消息总线系统可以配置各种持久性要求,比如要求所有主和副本都同步,要求只要发给主即可,有的发送不需要确认。 关于问题:朋友圈属于最终一致性,信息推送晚一会不是特别重要,所以最终一致性满足要求
明翼笔记总结:扩展性包括水平和垂直,水平扩展是增加水平类似的机器打群架方式,垂直扩展是现有的每个人提升实力,提升整体实力;一致性,集群上的数据为了保证高可用性显然要存在不同机器上存多份,这就存在不同机器数量同步问题,要求同步造成才可以进行读写的就是最终一致性,中间准许有个不一致时间窗的就是弱一致性,时间窗更长但是最终会统一的就是最终一致性,比如发微博场景,还讲了数据持久性,消息的持久性,一般类似kafka之类消息总线系统可以配置各种持久性要求,比如要求所有主和副本都同步,要求只要发给主即可,有的发送不需要确认。 关于问题:朋友圈属于最终一致性,信息推送晚一会不是特别重要,所以最终一致性满足要求作者回复: 很棒的总结。 对于思考题的答案,建议你再读读别的读者得留言,有的留言思考很深入~
2019-04-263 roaming看老师评论里说需要最终一致性和因果一致性,感觉这个因果一致性和Java内存模型里的happens-before好像
roaming看老师评论里说需要最终一致性和因果一致性,感觉这个因果一致性和Java内存模型里的happens-before好像作者回复: 谢谢你的留言!是的呢,在第九讲里面所讲到的线性一致性(Linearizability)其实也和Java Memory Model有关。如果在Java中修改的变量是volatile的话就会有这种线性一致性。
2019-05-091 Geek_b04b12这一节课,怎么让我想起了阿里李云华<从零到架构师>中提到的CAP理论,这大规模数据和架构师之间的知识看来是想通的着呀
Geek_b04b12这一节课,怎么让我想起了阿里李云华<从零到架构师>中提到的CAP理论,这大规模数据和架构师之间的知识看来是想通的着呀作者回复: 谢谢你的留言!有同感,其实当你学识更广之后会发现计算机中很多方向都是相辅相成的,并不会说某一块知识是相对独立起来的。
2019-05-021 西南偏北消息队列声明持久性的意思就是,比如kafka即可以作为消息队列,同时又可以将消息持久化到broker节点上?
西南偏北消息队列声明持久性的意思就是,比如kafka即可以作为消息队列,同时又可以将消息持久化到broker节点上?作者回复: 谢谢你的提问!Broker在Kafka的系统里可以看作是不同消息队列的容器。而消息队列中消息的持久性指的是一般broker都会将消息replicate到不同的节点上,这时候消息才能够被consumer接收。而如果consumer没有acknowledge接收到消息的话,消息队列会一直尝试发送给consumer。
2019-04-261 珅剑同问弱一致性和最终一致性的区别,最终一致性在弱一致性的基础上特殊在哪儿? 另外,最终一致性是保证每一次更新都会最终被同步还是只需要在没有新的更新时保证最后一条更新被同步?
珅剑同问弱一致性和最终一致性的区别,最终一致性在弱一致性的基础上特殊在哪儿? 另外,最终一致性是保证每一次更新都会最终被同步还是只需要在没有新的更新时保证最后一条更新被同步?作者回复: 谢谢你的回复!问的问题很棒! 对于最终一致性的理解,应该是你说的后者。 正如我在另一个回复中提到的,弱一致性是一个比较宽泛的概念,它是区别于强一致性的,包括各种不同容忍度的模型,比如因果一致性等都算它的特例。
2019-04-26- JohnT3e微信朋友圈评论主要由评论和后续回复组成: 首先,对于评论,评论内容对评论者而言应该要保证读写一致性(read-your-writes consistency),即评论一旦发出,那么对于该评论者无论在手机、网页还是其它城市应该都能看到其之前写的评论。而对于朋友圈可见的其它人来说,只要保证最终一致性(eventual consistency)就可以了(可能有时间要求),不同人的评论读取顺序无需和真实发生的顺序保持一致; 其次,对于评论的后续回复。回复内容对于回复者而言应该要保证读写一致性(read-your-writes consistency),而其它朋友圈可见的人一样,评论和回复内容应该按顺序被读取到,即需要保证一致前缀读(Consisten Prefix Reads)2019-04-26250

