

24|AIOps数据可靠性:如何预测磁盘故障
白园

你好,我是白园。今天我给你分享一下 AIOps 在数据可靠性层面的案例,其中最重要的就是磁盘的故障预测,磁盘故障预测对于数据可靠性有着非常重要的意义。
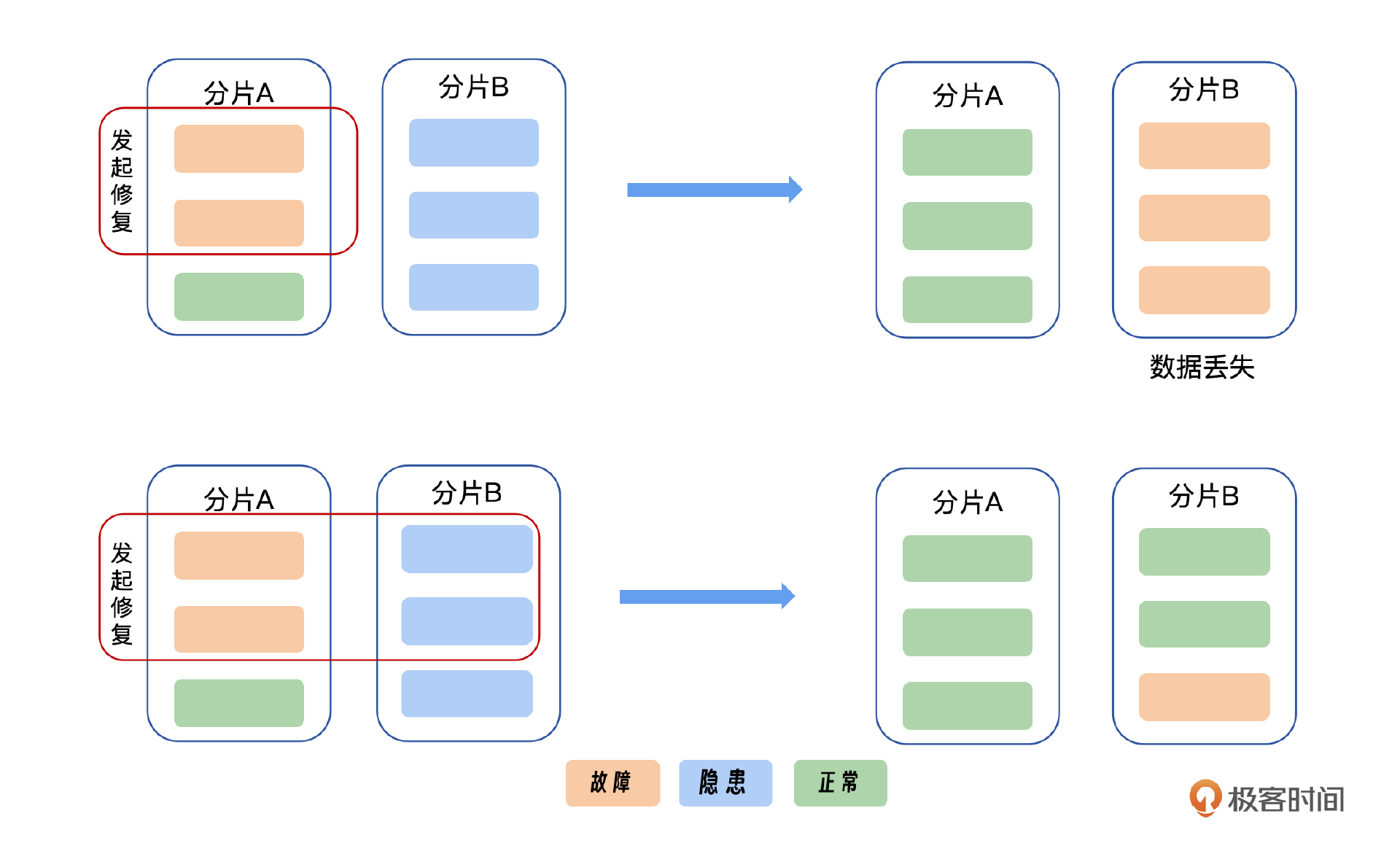
我们先来看百度网盘的一个场景,你可以看一下我给出的示意图。如果在第一时刻,分片 A 有两个副本出现故障,分片 B 有三个副本没有故障但是有隐患;如果没有磁盘故障预测的话,我们只会修复分片 A 的两个副本。然后第二时刻分片 A 完全修复,而分片 B 已经故障。这个时候分片 B 就会出现数据丢失的问题。
如果有磁盘故障预测的话,在第一时刻就会同时对分片 A 和分片 B 发起修复,然后完成修复,不会导致故障发生。所以如果能提前预测磁盘故障就会对数据可靠性有非常大的帮助。
如何实现上面的磁盘预测过程呢?我们从两个层面来看,一是算法和数据层面如何处理,二是工程层面如何处理。
算法流程
首先是算法和数据的处理,整体来说分为三个阶段。
数据获取:Smart 信息、业务信息、其他信息
准备阶段:数据探索、数据规范化、数据集划分
决策阶段:模型创建、模型训练、模型评估
数据获取
在监测磁盘故障异常时,业界普遍采用磁盘的 SMART(Self-Monitoring, Analysis, and Reporting Technology)信息来获取关键指标。然而,仅依赖 SMART 信息不足以全面反映业务性能。例如,即使磁盘的 SMART 预测显示正常,业务操作中的读写延迟已经显著增加,这种情况下,磁盘的实际表现已经受到影响,应被视为潜在故障。
公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结

1. 磁盘故障预测对数据可靠性至关重要,能够帮助提前修复潜在故障,确保数据的连续性和稳定性。 2. 在算法流程中,数据获取阶段需要综合使用SMART信息、业务信息和其他数据,以更全面地评估磁盘状态。 3. 降维处理是关键步骤,可以使用机器学习降维技术如主成分分析(PCA)或线性判别分析(LDA)来帮助减少数据的维度。 4. 在进行数据分类时,需要关注关键指标如真正类(TP)、假正类(FP)、真负类(TN)和假负类(FN),以评估分类模型的性能。 5. 随机森林算法在处理大量特征和捕捉非线性关系方面表现出色,适合用于磁盘故障预测模型构建。 6. 磁盘故障预测中心、副本安全控制中心、数据修复决策三者协同工作,确保数据的安全性和业务的连续性。 7. 在工程实施方面,采取了集中式训练和单机检测的模型架构,以实现高效的资源利用和快速的故障响应。 8. 在选择模型时,需要考虑数据规模、特征类型、模型解释性、训练和预测时间、模型复杂度等因素,并根据实际业务需求和资源限制进行选择。 9. SSD和HDD的磁盘故障预测存在明显不同,需要针对不同特性进行不同的预测策略。
仅可试看部分内容,如需阅读全部内容,请付费购买文章所属专栏
《SRE 实践:服务可靠性案例课》,新⼈⾸单¥59
《SRE 实践:服务可靠性案例课》,新⼈⾸单¥59
立即购买
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
精选留言
由作者筛选后的优质留言将会公开显示,欢迎踊跃留言。
收起评论