

02丨数据结构原理:Hash表的时间复杂度为什么是O(1)?

该思维导图由 AI 生成,仅供参考
数组
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

本文深入浅出地解释了Hash表的原理和实现,以及其他数据结构如数组、链表、栈和队列的特点和应用。文章首先介绍了数组和链表的存储方式及时间复杂度,然后深入讲解了Hash表的工作原理,通过计算Key的哈希值得到数组下标,实现了快速查找。同时,文章也提到了Hash冲突可能导致时间复杂度退化为O(N),但通过链表法可解决此问题。此外,文章还介绍了栈和队列的操作限制及应用场景。总之,本文通过对各种数据结构的解释,深入浅出地解答了Hash表时间复杂度为O(1)的原因,对读者快速了解Hash表的原理和实现具有重要参考价值。文章还提到了树的应用场景和遍历方式,以及对面试中数据结构问题的重视。文章以思考题的形式引发读者思考,增加了互动性。整体而言,本文内容丰富,涵盖了多种数据结构的知识,适合对数据结构感兴趣的读者阅读。
《后端技术面试 38 讲》,新⼈⾸单¥59

全部留言(67)
- 最新
- 精选
 _funyoo_说说我的思考: 方法1:在遍历链表1,看该结点是否在2中存在,若存在,即为合并。 遍历的方法:①两个for嵌套 ②根据1建立hash表,遍历2时在1中查找 方法2:计算两个链表的长度,谁长谁先“往前走”,待长链表未查看长度等于短链表是,两两元素比较,遍历完未出现相同时,则没有合并 方法3:直接比较两个链表的最后一个元素,相等即合并
_funyoo_说说我的思考: 方法1:在遍历链表1,看该结点是否在2中存在,若存在,即为合并。 遍历的方法:①两个for嵌套 ②根据1建立hash表,遍历2时在1中查找 方法2:计算两个链表的长度,谁长谁先“往前走”,待长链表未查看长度等于短链表是,两两元素比较,遍历完未出现相同时,则没有合并 方法3:直接比较两个链表的最后一个元素,相等即合并作者回复: √ 方法2 👍
2019-11-203178 Geek_9c3134老师 你这问题我问了别人 发现只回答到了数组下标 没有人讲到内存 还说我的问题太简单了
Geek_9c3134老师 你这问题我问了别人 发现只回答到了数组下标 没有人讲到内存 还说我的问题太简单了作者回复: 那就继续问下去~~ Hash表数组长度不足怎么办? 多线程并发修改Hash表怎么办?如何保证线程安全?JDK的ConcurrentHashMap是如何解决的? 如何使Hash表中的数据分布更加均匀,减少Hash聚集? 余数Hash算法应用于分布式缓存路由的时候有什么问题?如何解决?一致性Hash算法原理是什么? 用你熟悉的编程语言20分钟写一个一致性Hash算法实现。
2019-11-28756 breezeQian步骤一:将长度短的链表的元素构造成哈希表,key是指针,value是节点值。 步骤二:遍历较长链表找出合并的节点
breezeQian步骤一:将长度短的链表的元素构造成哈希表,key是指针,value是节点值。 步骤二:遍历较长链表找出合并的节点作者回复: √
2019-11-20313 晶晶是我听过的课程里面觉得最让我思路清晰的课程~所以先打卡沙发一下☺
晶晶是我听过的课程里面觉得最让我思路清晰的课程~所以先打卡沙发一下☺作者回复: 🌹
2019-11-2028- Geek_ac779f老师,为什么有些数据结构的内存空间不要求是连续的?都是连续的内存空间不好吗。既然连续和不连续的内存空间都可以实现这些数据结构,使用不连续的内存空间实现有什么好处呢,利用率更高吗。为什么利用率更高呢,不都是以字节为基本单位吗
作者回复: 程序运行过程中,内存不断被申请、释放,内存的空闲空间呈碎片化,本身就是不连续的。
2019-11-2726 
 Better me老师,文中这段话“想在 b 和 c 之间插入一个元素 x,只需要将 b 指向 c 的指针修改为指向 x,然后将 x 的指针指向 c 就可以了”感觉反过来说更合理一些,如果按以上顺序代码实现会出现指针丢失内存泄漏的情况吧。
Better me老师,文中这段话“想在 b 和 c 之间插入一个元素 x,只需要将 b 指向 c 的指针修改为指向 x,然后将 x 的指针指向 c 就可以了”感觉反过来说更合理一些,如果按以上顺序代码实现会出现指针丢失内存泄漏的情况吧。作者回复: 是的,你描述的算法过程更合理。 文中只是想表达这个插入节点,修改指针的逻辑,文中描述不作为算法过程。
2019-11-3022 郭刚类似Oracle中的hash join的算法
郭刚类似Oracle中的hash join的算法作者回复: √
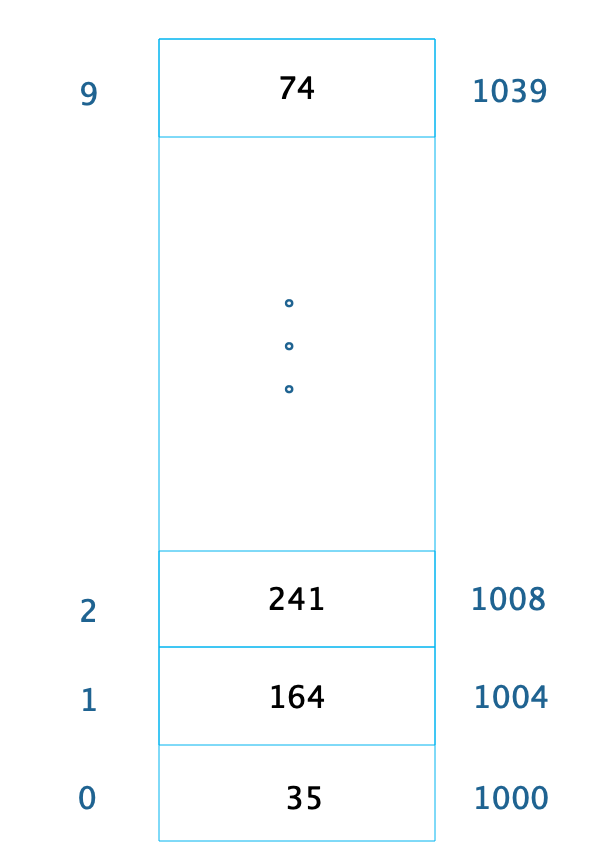
2019-11-2022 恺撒之剑课程中的数组示意图,长度为10的整数数组,地址从1000开始,下标为9的数组对应的起始地址应该为1036,而不是1039
恺撒之剑课程中的数组示意图,长度为10的整数数组,地址从1000开始,下标为9的数组对应的起始地址应该为1036,而不是1039作者回复: 已改正,谢谢~
2019-11-261 远心实现了同时遍历两个单向链表的方法,欢迎拍砖:https://github.com/Huan-Rong/geektime-backend-technology-basics/blob/master/sources/2-the-time-complexity-of-hash-table/src/main/java/site/blbc/MergeDetect.java
远心实现了同时遍历两个单向链表的方法,欢迎拍砖:https://github.com/Huan-Rong/geektime-backend-technology-basics/blob/master/sources/2-the-time-complexity-of-hash-table/src/main/java/site/blbc/MergeDetect.java作者回复: 思路很赞👍 你这里利用了LinkedList的特性,按照题意,应该无法直接得到两个链表的长度。
2019-11-2021 幸福来敲门由于每个整型数据占据 4 个字节的内存空间,因此整个数组的内存空间地址是 0x1000~0x1039,根据这个,我们就可以轻易算出数组中每个数据的内存下标地址。利用这个特性,我们只要知道了数组下标,也就是数据在数组中的位置,比如下标 2,就可以计算得到这个数据在内存中的位置 0x1008。 请问这个内存16进制地址是怎么得出来的? 0x1000~0x1039
幸福来敲门由于每个整型数据占据 4 个字节的内存空间,因此整个数组的内存空间地址是 0x1000~0x1039,根据这个,我们就可以轻易算出数组中每个数据的内存下标地址。利用这个特性,我们只要知道了数组下标,也就是数据在数组中的位置,比如下标 2,就可以计算得到这个数据在内存中的位置 0x1008。 请问这个内存16进制地址是怎么得出来的? 0x1000~0x1039作者回复: 谢谢指正,应该用十进制
2019-11-2031

