

21 | Python并发编程之Futures

该思维导图由 AI 生成,仅供参考
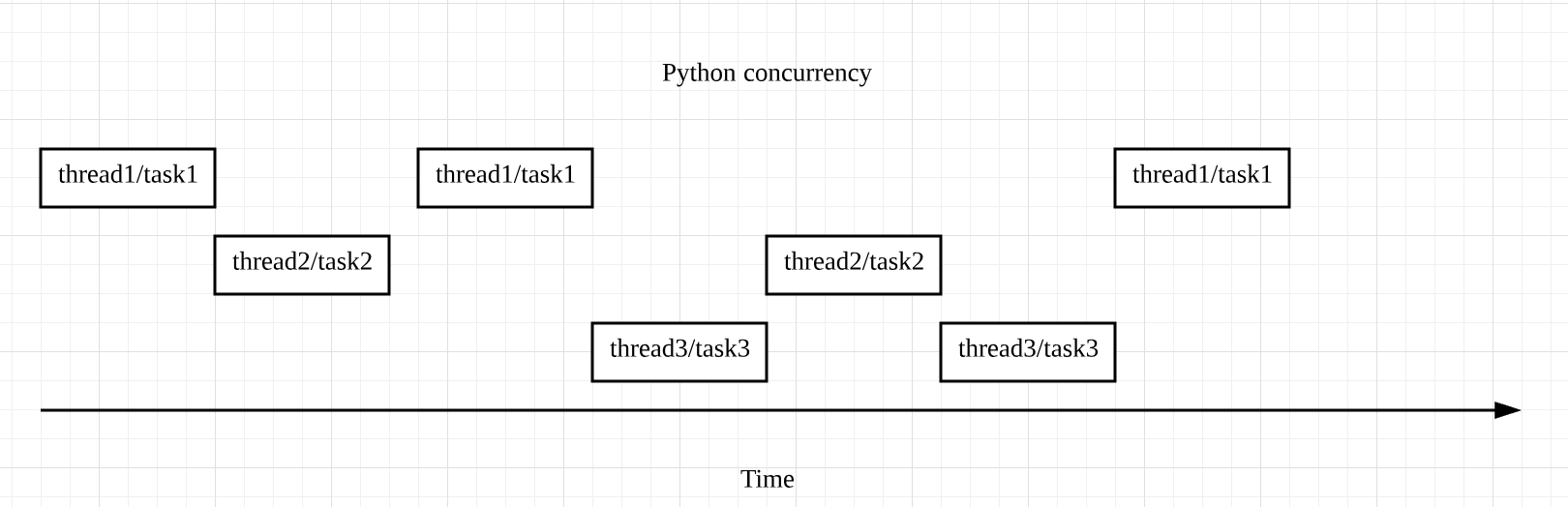
区分并发和并行
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

Python并发编程中的Futures技术概览 本文介绍了Python中的并发编程技术Futures,通过比较单线程和多线程的性能,展示了Futures的优势。文章通过实例代码演示了如何使用Futures实现多线程下载网站内容,并对比了单线程和多线程的性能差异。此外,还提到了使用多进程的并行方式,强调了多进程并不适用于I/O heavy的操作,而适用于CPU heavy的场景。最后,总结了并行和并发的适用场景,以及如何根据实际需求选择最优的线程或进程数量。通过本文的介绍,读者可以快速了解Python中的并发编程技术Futures,以及如何利用Futures提升程序性能,特别是在I/O操作频繁的场景下。
《Python 核心技术与实战》,新⼈⾸单¥59

全部留言(55)
- 最新
- 精选
 KaitoShy思考题: 1. request.get 会触发:ConnectionError, TimeOut, HTTPError等,所有显示抛出的异常都是继承requests.exceptions.RequestException 2. executor.map(download_one, urls) 会触发concurrent.futures.TimeoutError 3. result() 会触发Timeout,CancelledError 4. as_completed() 会触发TimeOutError
KaitoShy思考题: 1. request.get 会触发:ConnectionError, TimeOut, HTTPError等,所有显示抛出的异常都是继承requests.exceptions.RequestException 2. executor.map(download_one, urls) 会触发concurrent.futures.TimeoutError 3. result() 会触发Timeout,CancelledError 4. as_completed() 会触发TimeOutError作者回复: 回答的很对
2019-06-26471 Goal学习到的知识点: 1. 并发和并行的区别,大佬通俗易懂的方式让我更深刻的体会到了程序到底是如何跑在多核机器上的 2. python中 Futures 特性,第一次接触到这个模块,待后续继续加深了解; 3. Python 中之所以同一时刻只允许一个线程运行,大佬解释了这是因为全局解释器锁的存在,而全局解释器锁又是为了解决 race condition而引入的,这个也从另一方面验证了我之前学习到的,python中多线程是无法利用多核的; 但是多线程无法利用多核也并不是一无是处,就像大佬在文中聊到的,多线程主要的适用场景就是 有IO延迟的场景,因为一个线程遇到IO延迟,它占用的全局解释器锁就会释放,而另一个线程即可以拿到锁开始执行; 这种在IO延迟场景中的并发,高效也是显而易见的;
Goal学习到的知识点: 1. 并发和并行的区别,大佬通俗易懂的方式让我更深刻的体会到了程序到底是如何跑在多核机器上的 2. python中 Futures 特性,第一次接触到这个模块,待后续继续加深了解; 3. Python 中之所以同一时刻只允许一个线程运行,大佬解释了这是因为全局解释器锁的存在,而全局解释器锁又是为了解决 race condition而引入的,这个也从另一方面验证了我之前学习到的,python中多线程是无法利用多核的; 但是多线程无法利用多核也并不是一无是处,就像大佬在文中聊到的,多线程主要的适用场景就是 有IO延迟的场景,因为一个线程遇到IO延迟,它占用的全局解释器锁就会释放,而另一个线程即可以拿到锁开始执行; 这种在IO延迟场景中的并发,高效也是显而易见的;作者回复: 说的很对
2020-01-098 Steve老师,我有一个很类似的场景。之前我用单线程去下载所有页面。然后在每个页面解析出需要的内容放入一个集合里。如果改成并发的实现,多线程写一个集合(写文件也类似),是不是有线程安全的问题。有没有小例子可以学习一下~
Steve老师,我有一个很类似的场景。之前我用单线程去下载所有页面。然后在每个页面解析出需要的内容放入一个集合里。如果改成并发的实现,多线程写一个集合(写文件也类似),是不是有线程安全的问题。有没有小例子可以学习一下~作者回复: 可以用 python 线程安全的容器,例如 Queue. 如果内存存不下,可以用数据库,而不是直接写文件。
2020-05-157- Geek_5bb182老师你好,concurrent.futures 和 asyncio 中的Future 的区别是什么,在携程编程中
作者回复: 可以参考https://stackoverflow.com/questions/29902908/what-is-the-difference-between-concurrent-futures-and-asyncio-futures
2019-06-277  干布球请问老师,future任务是调用submit后就开始执行,还是在调用as_completed之后才开始执行呢?
干布球请问老师,future任务是调用submit后就开始执行,还是在调用as_completed之后才开始执行呢?作者回复: submit之后
2019-06-2634 helloworld总结下并发和并行的概念: 并发,是指遇到I/O阻塞时(一般是网络I/O或磁盘I/O),通过多个线程之间切换执行多个任务(多线程)或单线程内多个任务之间切换执行的方式来最大化利用CPU时间,但同一时刻,只允许有一个线程或任务执行。适合I/O阻塞频繁的业务场景。 并行,是指多个进程完全同步同时的执行。适合CPU密集型业务场景。
helloworld总结下并发和并行的概念: 并发,是指遇到I/O阻塞时(一般是网络I/O或磁盘I/O),通过多个线程之间切换执行多个任务(多线程)或单线程内多个任务之间切换执行的方式来最大化利用CPU时间,但同一时刻,只允许有一个线程或任务执行。适合I/O阻塞频繁的业务场景。 并行,是指多个进程完全同步同时的执行。适合CPU密集型业务场景。作者回复: 没错
2019-06-2633 LJK老师好,请问一下在python存在GIL的情况下,多进程是不是还是无法并发运行?谢谢老师
LJK老师好,请问一下在python存在GIL的情况下,多进程是不是还是无法并发运行?谢谢老师作者回复: 如果是多进程,则无所谓,可以并发运行。GIL是作用在线程上的,是不允许进程中的多线程同时运行
2019-06-2643 简传宝老师好,请问是否可以理解为计算密集型任务用多进程,io密集型用多线程
简传宝老师好,请问是否可以理解为计算密集型任务用多进程,io密集型用多线程作者回复: 没错。CPU-bound的任务主要是multi-processing,IO-bound的话,如果IO比较快,用多线程,如果IO比较慢,用asyncio,因为效率更加高
2019-06-272 MarDino想问下老师,该怎么向executor.map中的函数,传入多个参数?
MarDino想问下老师,该怎么向executor.map中的函数,传入多个参数?作者回复: 这个map函数的用法可以参照https://docs.python.org/3/library/concurrent.futures.html
2020-02-111 _stuView老师,请问什么是线程安全,什么是race condition呢?
_stuView老师,请问什么是线程安全,什么是race condition呢?作者回复: 可以参考https://en.wikipedia.org/wiki/Thread_safety
2019-06-261

