本次分享系统梳理了实时数字人开发技术,包括 AI Agent 与大模型的开源生态,以及详细介绍了实时数字人的三大技术路线。
1.0x
- 3.0x
- 2.5x
- 2.0x
- 1.5x
- 1.25x
- 1.0x
- 0.75x
- 0.5x
大家好,我是李锟。
我今天分享的主题是《玩转实时数字人开发:巧用 AI Agent 工作流与实用案例详解》。先简单做个自我介绍:我是一名资深软件架构师,曾在阿里巴巴、盛付通、唯品会等企业任职,主要从事电商、在线支付、互联网金融和量化投资等方向的业务开发。在 NLP、大模型及 AIGC 应用方面,我已有五年的实战经验。
今天分享的第一部分,是对当前 AI Agent 开源社区的生态系统做一个详细的梳理。尽管很多同学对 AI Agent 已有一定了解,但对背后的大模型开源生态可能还不完全熟悉。因此,我会系统性地为大家介绍目前国内外重要的开源语言模型。
目前,开源大语言模型领域发展非常活跃,国内外都涌现出众多有影响力的模型。先来看国外方面。最早开源的大语言模型之一,是 Meta 公司在 2023 年发布的 Llama 1.0,如今该系列已迭代到 Llama 4。Llama 4 其实是一个模型系列,主要包括 Llama 4 Scout(16 专家版本)和 Llama 4 Maverick(128 专家版本),这两个都属于多模态模型,不仅支持文本交互,还可处理图像与视频输入。此外,Meta 还推出专用于编程的模型 Code Llama,不过该模型已有一年多未更新。
Google 也紧随 Meta 步伐,很早就发布了开源大模型 Gemma,目前最新是 Gemma 3,同样为多模态模型,支持文本、图像和视频交互。Google 还拥有自研的代码生成模型 CodeGemma。法国公司 Mistral AI 也是开源领域的重要参与者,大约两年前就发布了其语言模型,最新版本 Mistral Small 3.2 同样支持多模态。马斯克旗下的 xAI 也开源了模型 Grok-1,并在几个月前透露 Grok-2 将在 Grok-3 稳定后开源,具体时间尚未确定。另外,AI 公司 Cohere 也推出了开源大模型 Command R。
事实上,海外开源模型多达数百个,在此我只列举了一些最具代表性的项目。接着,我们再看国内,开源语言模型生态同样丰富。
首先,最知名的是阿里云的千问系列(Qwen),最新版 Qwen3 已发布。其多模态版本包括 Qwen2.5-VL 和 Qwen2.5-Omini。阿里云在近期推出专用于编程的模型 Qwen-Coder,目前也非常受欢迎。
清华系公司智谱 AI 也一直大力推进开源,最新模型为 GLM-4.5,并提供轻量化版本 GLM-4.5-Air,他们的多模态开源模型包括 VisualGLM-6B 和 CogVLM-17B。
腾讯云开源了语言模型 HunyuanMoE-A52B,多模态模型则包括 Hunyuan-DiT 和 Hunyuan3D-2.0。
而今年最受关注的开源模型,应该是深度求索(DeepSeek)在春节期间发布的 DeepSeek-R1。与之前发布的 DeepSeek-V3 不同,R1 支持“深度思考”,可以完成数学推理和多步推导类任务,而 V3 响应更快、适用于通用问答。因此在开发 AI Agent 时,我们可以把这两个模型搭配使用。目前 R1 最新版为 0528 版本,V3 为 0324 版本。深度求索还曾推出编程模型 DeepSeek-Coder-V2,但已经很久没有更新了。
近期另一个热点是月之暗面(Moonshot)发布的 Kimi K2,是当前最受欢迎的国产开源模型。其前身为 5 个月前发布的 Moonlite-16B-A3B-Instruct,现已被 Kimi K2 完全替代。Kimi K2 在编程任务上表现突出,且推理成本极低,性价比很高。
百度也在今年 6 月发布了文心 4.5(ERNIE-4.5)系列开源模型,涵盖 8-9 种不同尺寸与用途的版本。其中包括多模态模型 ERNIE-4.5-VL,支持视觉输入(图像与视频)。
接下来,我为大家梳理一下当前全球范围内主流的开源大模型发布平台。目前主要有三个平台值得关注,首先是 Hugging Face Hub,这是全球最大的 AI 模型发布平台,可以把它比作“AI 界的 GitHub”。正如 GitHub 是全球最大的开源代码托管平台,Hugging Face Hub 则是 AI 模型领域最具影响力的开源社区。该平台涵盖了各类 AI 模型,语言模型只是其中之一。
在国内,我们有魔搭社区(ModelScope),由阿里巴巴达摩院推出。由于国内用户有时访问 Hugging Face Hub 可能不太方便,所以可以把 ModelScope 看作是 Hugging Face 的国内替代版。用户可在 ModelScope 上下载与 Hugging Face 相同的模型,平台上同样覆盖了多种 AI 模型类型,也包括语言模型。
最后是 OLlama,最初由 Meta 开发,并在大概两年前开源的。该平台专注于语言模型,不支持其他类型的 AI 模型发布。
接下来介绍几种常用的开源语言模型部署工具。
第一个是 Hugging Face 平台中广泛使用的 Transformers 库。该库基于 Python 和 PyTorch 实现,是一个功能全面的 AI 模型开发框架,既可用于模型推理,也支持训练和研发。目前绝大多数基于 Transformer 架构的语言模型,最初都是借助 Transformers 框架开发的。
第二个工具是 vLLM,同样使用 Python 语言编写,它也是基于 Transformers 构建,但它也只能做模型推理环节,不涉及训练与研发。尽管源于 Transformers,vLLM 在推理性能上实现了显著超越,部分场景下甚至可提升十倍以上。
第三个是 OLlama,它使用 Go 语言开发,与 vLLM 一样仅用于模型推理。得益于 Go 语言的高效特性,OLlama 具备优异的性能,并且不依赖 NVIDIA GPU,它能支持纯 CPU 推理,同时兼容 AMD、Intel 甚至华为的 GPU。OLlama 对硬件要求极低,可良好运行于树莓派等嵌入式设备及智能手机,并支持 Linux、Windows 和 macOS 等多平台。
除此之外,目前开源的大模型部署工具多达二三十种,相信未来还会持续涌现更多新的工具。
最后一部分是关于开源的 AI Agent 开发框架。首先来看通用型框架,最著名的是 LangChain,可以说它是最老牌的 AI Agent 开发框架,与之配套的还有 LangGraph,两者结合构成了当前应用最广泛的开发方案。不过 LangChain 属于相对重量级的框架,封装层次较深,因此学习和开发成本较高。
第二个是 CrewAI,它是基于 LangChain 开发出来的 Agent 开发框架。
第三个是 AgentSDK,它是 OpenAI 在 2025 年春节后发布的超轻量级 AI Agent 开发框架。
第四个是 AutoGPT Platform,这个框架的前身 AutoGPT 是全球首个自主型智能体(Autonomous Agent)开发框架。最新版 AutoGPT Platform 已取代旧版的 AutoGPT Classic。
第五个是微软推出的 AutoGen。另外还有 Meta GPT,去年曾备受关注,最新版本是 0.8.1,但目前开发已经停滞,1.0 正式版发布日期未知,因此选用时需谨慎。
其他还包括 AutoAgents,这是一个由国内开发者发起的项目;同样 CAMEL 这个框架也是以国内开发者为主,发起人为李国豪老师(现居海外);以及 BabyAGI,它是紧接 AutoGPT 之后出现的早期框架之一,但目前使用者已较为稀少。
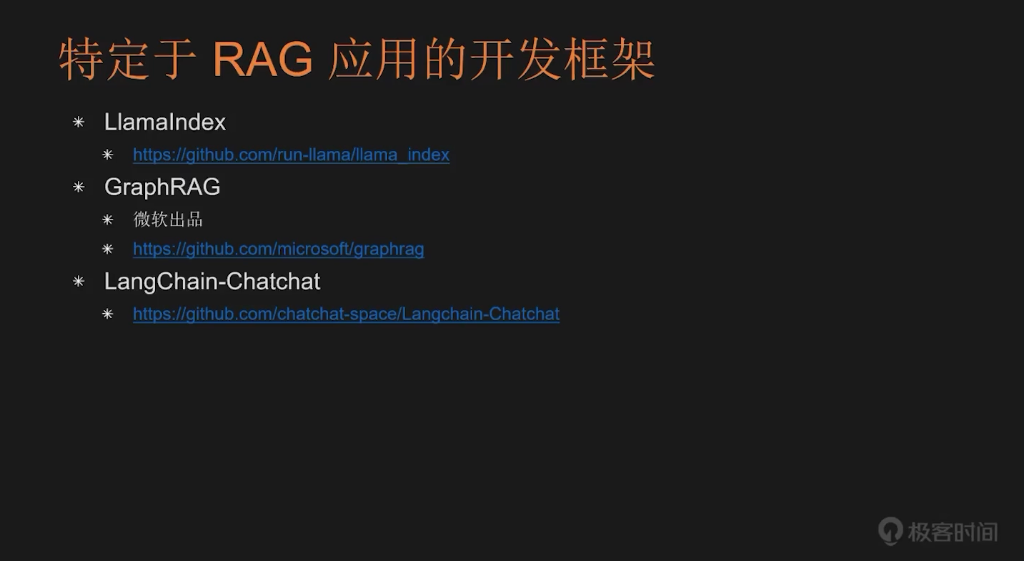
在介绍了通用的 AI Agent 开发框架之后,接下来我将为大家梳理一些专门面向特定类型应用的开发框架。这类框架通常专为开发 RAG(Retrieval-Augmented Generation,检索增强生成)类应用设计,并不太适合开发其他类型的 AI Agent,例如之前提到的 Autonomous Agent(自主型智能体)。这类特定用途的开发框架包括:LlamaIndex、微软推出的 GraphRAG,以及一个由国内开发者基于 LangChain 开发的框架:LangChain-Chat。
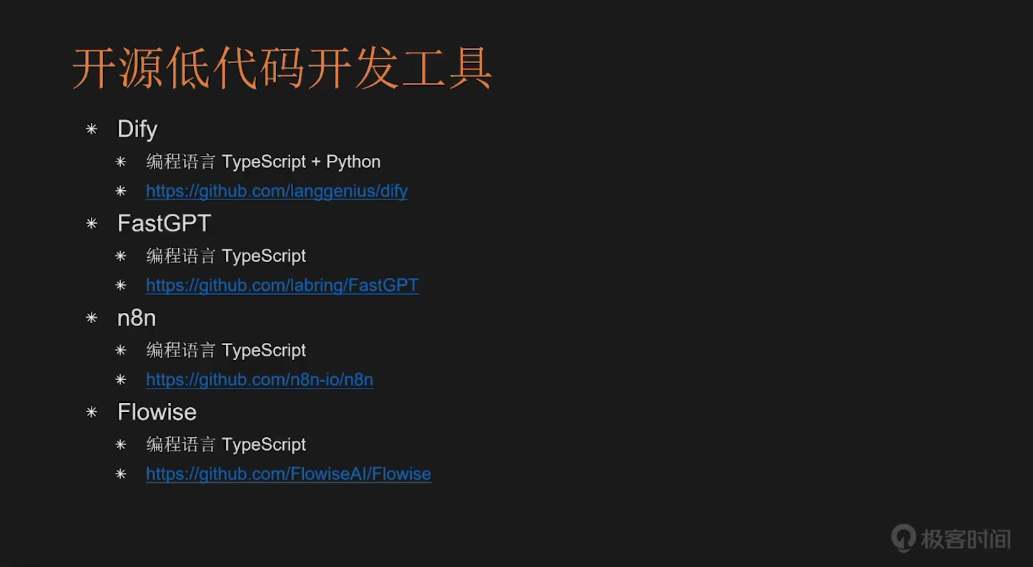
接下来,我们来看开源的低代码开发工具。目前已有不少优秀的开源低代码工具,其中最知名的是 Dify,支持 TypeScript 和 Python。另外还有 FastGPT,编程语言是 TypeScript,国外开发者推出的 n8n,编程语言同样是 TypeScript,以及 Flowable,编程语言也是 TypeScript。这些都是当前主流的开源低代码开发工具。
还有一类更高层的开发工具,我将其称为“类 Manus 工具”。之所以这样命名,是因为它们都是在国内知名产品 Manus 发布后相继出现的同类工具。Manus 自称为“全球首个通用 AI Agent”,但这一说法并未得到业界的广泛认可。在这些工具中,有三个较为知名:第一个是 OpenManus,由 MetaGPT 团队推出;第二个是 Owl,由 Camel 团队开发;第三个是 Minion-Agent,是郑炳南老师开发的。这三个项目都是开源的,如果无法获得 Manus 邀请码,可以尝试使用这些作为替代方案。
最后为大家介绍开源的 AI 辅助编程工具。当前这类工具的选择很多,而且多数都是开源的。我建议大家优先通过开源工具来体验 AI 辅助编程,因为它们的使用成本极低,几乎是零门槛,唯一需要投入的就是学习时间。
低成本意味着你可以更自由地进行尝试与探索,从而积累宝贵的实战经验。相反,如果一开始就选高端商业工具,如目前最热门的 Cursor(每月约 200 美元),除非预算充足,否则很难开展大量实验,反而不利于能力积累。
开源 AI 辅助编程工具中,例如 Codeium 和 Tabnine,都是以 VSCode 插件形式提供,可直接在编辑器内使用。谷歌的 Gemini CLI 则以命令行方式调用。国内也有祝威廉同学开发的 AutoCode,支持命令行调用,同时提供 VSCode 插件,方便在编辑器内集成。
接下来我们剖析 AI Agent 应用的四大类别。
第一类是最常见的 Chatbot,也叫聊天机器人,典型代表是 OpenAI 两年前发布的 ChatGPT,它是人类历史上用户增长至 1 亿活跃用户最快的应用,仅用了大约两个月就实现了这个成绩,可能以后也很难被超越了。这类 AI Agent 需用户反复对话交互,主要用来完成信息获取类需求,还可以配置外部工具方便接入更多数据源。
第二类是 Autonomous Agent,即自主型智能体。用户无需与其反复对话,它主要用于任务执行。用户只需明确任务目标、交付物及质量要求,并为 Agent 配置完成任务所需的外部工具即可。这类 AI Agent 通常是高度自动化的,甚至可能无用户界面,以后台服务的形式来运行。因此,Autonomous Agent 非常适用于工业场景,与传统领域的 RPA(机器人流程自动化)结合,用来构建高度自动化的应用。
第三类是辅助编程型 Agent。这类 AI Agent 的核心产出是代码,包括多种编程语言的源代码及相关软件设计文档(如架构设计、模块说明等)。这类工具现在又有一个广为接受的新名字:“氛围编程”工具。
第四类是通用型 AI Agent。这类 Agent 并非全新概念,因为早在两年前,AutoGPT 在某种程度上就已具备这类特性,只是未主动宣称自己是“通用 AI Agent”。而 Manus 是最早以“通用 AI Agent”自居的应用,但这一说法尚未得到业界的广泛认同。
这类 Agent 属于“万金油”型的产品,表面上能够处理多种任务,包括回答问题、生成代码、执行操作等,看似无所不能。但也正因如此,它们在各个垂直领域都不够专业,功能广度牺牲了深度,我认为可能难以形成稳定可靠的商业模式。很多通用型 AI Agent 还常宣称自己在追求 AGI(通用人工智能)。但目前我们距离真正被广泛认可的 AGI 仍然较远,我个人预计还需要 3~5 年的时间才有可能实现实质性突破。
最后我介绍一下选择 AI Agent 开发框架的原则。选择框架的核心原则只有一句话:取决于你的具体应用需求和运行环境。
如果应用仅仅是 Demo 级别的或者复杂度低、并发低的场景,可以优先选用低代码开发工具或类 Manus 工具,这样的工具很适合快速搭建原型或演示版本。如果应用是在生产环境,而且是以 Chatbot 为主,并发较高的时候,最好就避免使用低代码工具和类 Manus 方案,同时也可排除 AutoGPT Platform 和 BabyAGI(这两个都不是专门为 Chatbot 设计的),除此之外的大多数框架均可纳入选择范围。
那如果你的应用是用在生产环境,而且是以 Autonomous Agent(自主型智能体)为主时,这时候应该排除低代码工具、类 Manus 工具,以及专为 RAG 设计的开发框架(RAG 开发框架通常更偏向 Chatbot)。建议优先选择轻量级框架,避开 LangChain、LangGraph、CrewAI 等重量级方案。
接下来为大家介绍 AI 生成式数字人的开源项目。首先要讲的是非实时类 AI 生成数字人,即基于 AI 模型生成预渲染的数字人视频。目前开源社区中有众多优秀项目:
EchoMimic:由蚂蚁集团推出,支持通过输入图片和音频生成数字人视频。
Sonic:腾讯与浙江大学联合开发,同样基于图片输入生成数字人视频。
Live Portrait:快手团队开发,也是以图片为输入源生成视频。
HeZhen(黑帧):由硅基智能开发,支持基于视频输入生成数字人内容。
SideTalker:西安交通大学、腾讯 AI 实验室与蚂蚁集团合作开发。
Lentent-Sync:字节跳动与北京交通大学联合推出。
JoiZen:京东与香港大学合作开发。
JoiHollow:京东自研,目前支持中英双语。
MiniMetis:由个人开发者发起,作者宣称其生成速度比 Live Portrait、EchoMimic、MuseTop 等算法快 10~100 倍。
接下来是实时 AI 生成数字人,这类技术通常也被称为 2.5D 数字人。它们都基于 AI 模型实时生成视频流,并推送到前端应用进行展示。目前具有代表性的项目包括:腾讯开发的 MuseTalk、阿里巴巴通义实验室推出的 LaMDA、阿里巴巴达摩院开发的 Lite Avatar,以及 ER-NeRF、Wave2Lip 和 Auto-Avatar 等项目。这些都是通过 AI 模型实时生成数字人视频的解决方案。
这类数字人属于 2.5D 技术范畴,在低并发场景下能够实现近乎实时的响应效果。但当画面或任务复杂度变化较大时,可能会出现较明显的延迟。
除了实时 AI 生成数字人之外,我们还可以来了解一下实时非 AI 生成式数字人方案,这类方案主要分为两大类:2D 数字人和 3D 数字人。在 2D 数字人领域,最具代表性的是日本 Live2D 公司推出的 Live2D 技术。该技术最初是为二维游戏开发的,比如大家熟悉的日系养成类游戏,至今已有超过 15 年的历史,技术非常成熟,能够实现复杂的交互效果。
Live2D 数字人还有一个显著优势:它完全运行在客户端,对硬件要求很低,能够很好地支持手机等嵌入式设备,甚至连一些老旧的低端智能手机都能流畅运行。除了 Live2D,国内还有一些厂商提供私有 2D 解决方案,在此就不详细展开了。
在 3D 数字人领域,主要分为两大类:一是基于 Unreal 引擎的 MetaHuman,二是基于 Unity 引擎的 Digital Human。这两种方案都是通过游戏引擎实现 3D 数字人,相关素材也主要应用于游戏开发领域。
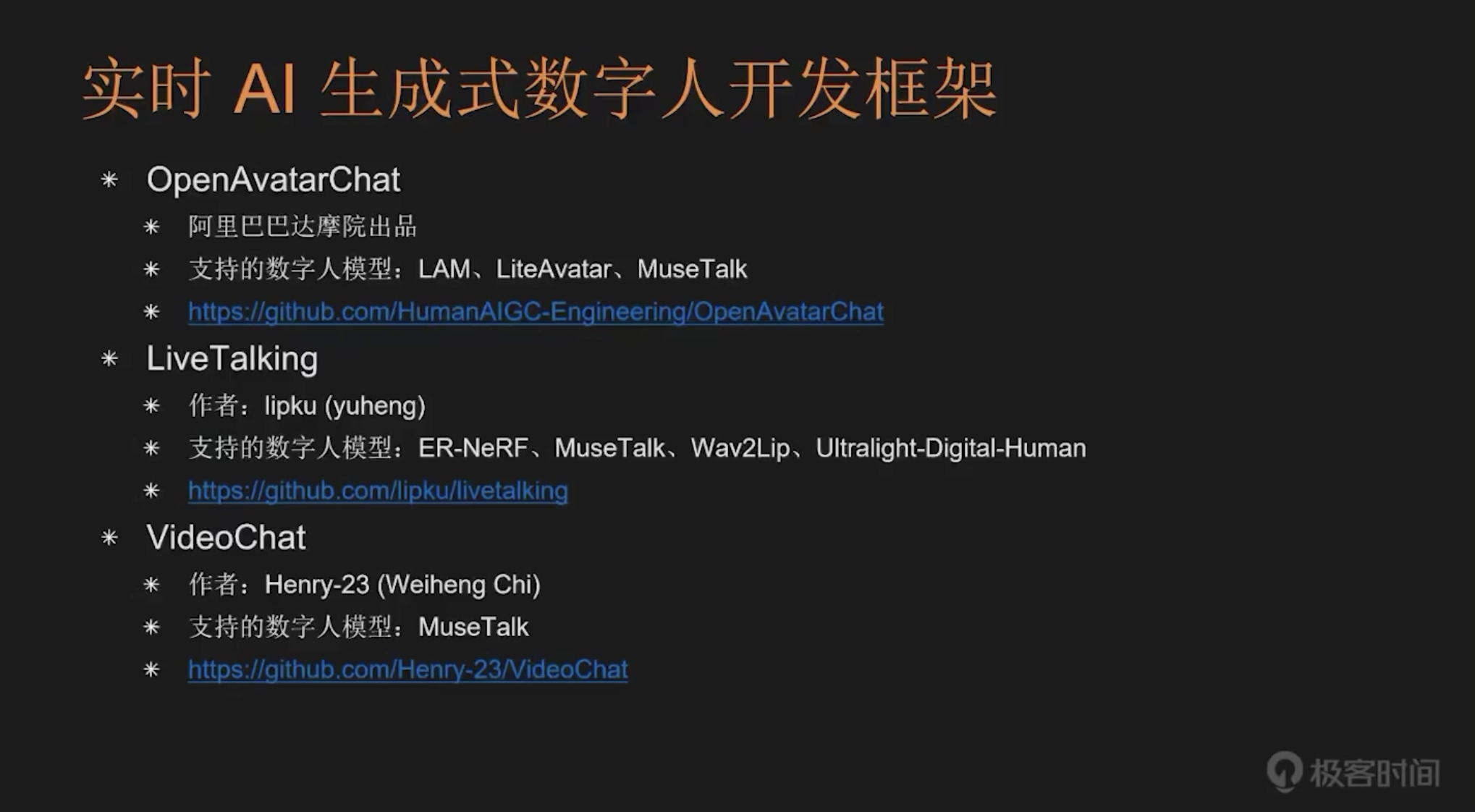
在介绍了实时数字人的三大技术路线后,我们需要继续了解实时 AI 生成式数字人的开发框架。这类框架与前面提到的单纯数字人生成方案不同,它们不仅支持数字人生成,还集成了多种语音处理能力,包括 ASR(语音转文本)和 TTS(文本转语音)等功能。基于这些框架,开发者可以构建出既能进行实时交互,又能支持语音对话,还能实现精准口型同步的数字人应用。
目前主要的开发框架包括:阿里巴巴达摩院推出的 OpenAvatar Chat,它支持 Lite Avatar 和 MuseTalk 等数字人模型;Live Talking 框架支持更丰富的模型,包括 ER-NeRF、NewsTalk、Wave2Lip、ArchTech Digital Human 等;Video Chat 框架目前仅支持 MuseTalk 一种数字人模型。
此外还有一个重要的框架 FAY,它不仅支持 AI 生成式数字人(如 Wave2Lip、ER-NeRF、MuseTalk),还支持基于 Unreal 的 MetaHuman 和 Unity 的 Digital Human,同时还能集成硅基智能开发的在线实时数字人平台 Duix 的安卓客户端,以及国内厂商开发的 2D 实时 AI 数字人模型 Aibote。因此 FAY 框架能够同时支持 2D、3D 和 2.5D 三种技术路线。
最后还有一个实时非 AI 生成式数字人开发框架 ADH(Awesome Digital Human),由一力辉老师开发,基于 Live2D 模型,只支持 2D 技术路线。
最后我们来看看选择实时数字人技术路线的原则。这个原则同样取决于我们具体的需求和运行环境。如果我们的数字人应用是面向企业内网,并且并发很低,那么可以选择 2D 或基于 AI 的 2.5D 数字人技术路线。3D 技术路线通常来说过于复杂,我一般不会推荐。如果客户可以接受 2D 卡通形象,从性价比角度出发,建议优先选择 2D 技术路线。2.5D 数字人技术路线的开发和运维成本都比较高,如果贸然选择,可能会事倍功半。
如果开发的应用是面向互联网,并且并发较高的话,2D 数字人技术路线是唯一可行的选择。因为基于 AI 模型的 2.5D 技术路线对服务器端硬件要求较高,其在并发支持和系统性能方面的表现较差,不太适合开发高并发的互联网应用。在这种情况下,我们只能选择 2D 数字人技术路线。目前 Live2D 是 2D 数字人领域的事实标准,所以如果选择 2D 数字人技术路线,基本上就只有 Live2D 这一个选择。
以上就是我今天分享的全部内容,重点为大家系统梳理了实时数字人开发所涉及的各项关键技术。从 AI Agent、开源大模型的选择与部署,到实时数字人的 2D、2.5D 及 3D 技术路线,每一部分都蕴藏着强大的创新潜力。
想要真正掌握实时数字人开发,关键在于动手实践,基于应用场景选择适合的开源工具和框架,参考所讲案例,从简单场景入手,逐步构建属于自己的数字人应用。数字人技术正以前所未有的速度演进,无论是互动娱乐、在线教育还是企业服务,都有巨大的应用空间等待大家来探索。
希望本次分享能为大家打开一扇新的大门。欢迎加入实时数字人开发的实践课程,勇于尝试、敢于创造,用技术打造更生动、更智能的人机交互未来!














 荧光笔
荧光笔 直线
直线 曲线
曲线
