如何快速上手AI算法?
Tyler

AI 系统需策略、模型、数据、架构四个团队的协作,懂 AI 的后端工程师将在多智能体系统中发挥关键作用,推动数字员工革命。
00:00 / 00:00
1.0x
- 3.0x
- 2.5x
- 2.0x
- 1.5x
- 1.25x
- 1.0x
- 0.75x
- 0.5x
大家好,我是 Tyler。
今天的内容主要是面向后端工程师同学,以及校招毕业生或希望转向 AI 技术栈的同学们。我将为大家介绍在这个过程中如何实现职业转型,并做好职业规划。
具体的议程会分为以下几个部分:首先,我会介绍 AI 目前对整个行业和社会的核心价值,以及核心技术的概况。之后,我会展开讨论 AI 各个学派的方法论,以及这些方法论在不同场景下的特点。
接下来,我们会探讨为什么在掌握了方法论后,开发 AI 产品时仍会感到无从下手,这主要是由于和 AI 系统之间存在鸿沟。最后,我会介绍如何通过本课程帮助大家跨越这个鸿沟,并提供更具体的指导。
首先,我来谈谈课程的缘起。大家可能已经注意到,市场上 AI 岗位的需求正在快速增长,媒体和各大大厂都将精力投入到了 AI 赛道。相信从业的同学们也能感受到,身边团队和公司高层都在推动 AI 项目。但在这个过程中,行业内部发现了一个严峻问题:AI 人才严重不足。科班出身的算法背景同学远远无法满足市场需求。
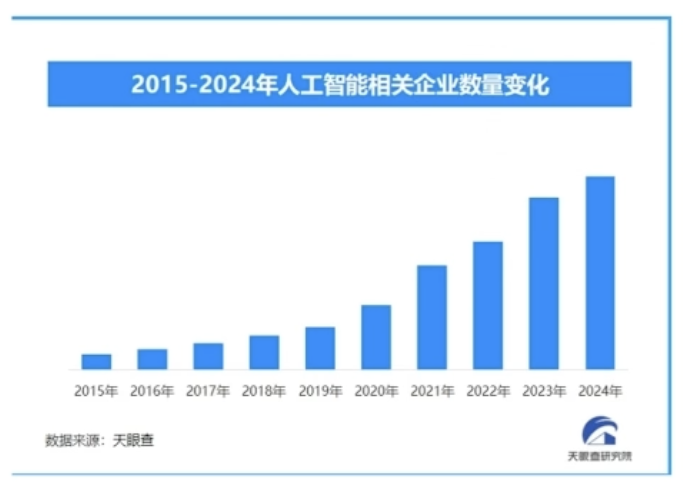
由于所有业务都在向 AI 转型,很多大厂都在强调 AI 岗位招聘无上限。当然,这并非字面意义上的无上限,每个公司都有招聘限制,但这句话反映出 AI 人才已出现严重短缺,各公司都在尽力囤积 AI 人才。其根本原因在于整个 AI 人才结构出现了断层。因此,作为行业从业者,我认为人才已成为瓶颈,我们有责任和义务去解决这个问题。从下图可以看出,AI 人才的需求正在逐年上涨,且增长速度只会越来越快。
现在我们开始进入正题。首先,我们来回答一个问题:为什么要学习工业级的 AI 系统?工业级体现在哪里?在了解 AI 的过程中,大家常会遇到一些现象,这也是校招同学、在校学生或希望转岗的同学经常提出的问题。人工智能听起来名称统一,都是 AI 或人工智能,但背后的落地场景和技术却显得非常碎片化,例如生成式 AI、自动驾驶和推荐系统,这些看起来似乎不是同一种 AI。
此外,大家可能之前了解过一些人工智能课程或公开课,觉得每个算法都很有趣,学完后也能训练一些模型。但当真正尝试开发市面上的产品项目时,仍会感到无从下手。同时,有些同学(尤其是在校学生)可能在 Kaggle 上取得过不错成绩,但一到面试时,被问及更深层次的 AI 系统相关内容,就会露怯,发现自己缺乏实战经验。
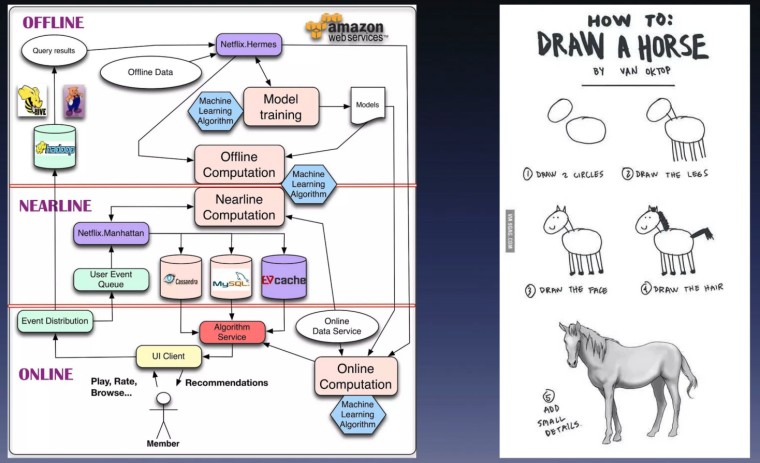
我相信大家或多或少也会有类似的困惑。右边有一个图,非常形象地描述了当前遇到的问题。例如,左边是 Netflix 基于 AWS 构建的一整套 AI 系统架构,包括 online、nearline 和 offline 的三层架构。但大家看到这个图后,如果想自己构建一个 AI 系统,就会像右边这张图所示:前四步看起来非常合理,但第四步到第五步的鸿沟却难以跨越。这其实不怪大家,因为鸿沟背后有许多复杂因素。稍后,我会层层剖析,揭示鸿沟背后的具体工作。
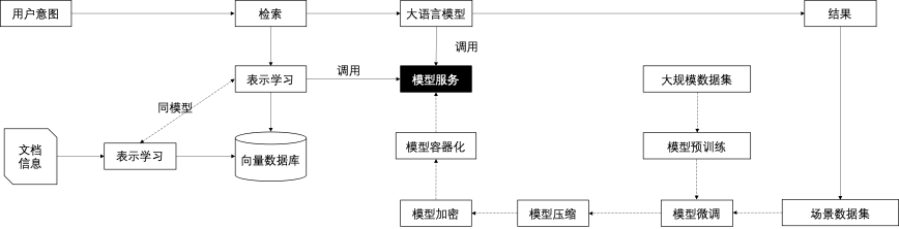
刚才介绍了大家在转岗过程中遇到的问题,在解决这些问题之前,我们先明确目标。来看一下 AI 市场上目前对人才需求最大的两个岗位。第一个岗位是传统的搜索推荐系统,因为搜索推荐系统是 AI 系统在人类社会中最大规模的落地应用,包括搜索、广告,以及 TikTok 和抖音所用的推荐系统,它们都基于用户行为进行在线闭环建模。第二类系统是新兴的 AI 大模型系统,其特点是通过预训练模型加上 Zero-shot 和 Few-shot 的激活,就能完成一个看似非常有竞争力的 AI 产品。
大家可以看蓝色箭头下面的两个架构图或流程图,它们代表了这两类不同需求背后的技术形态。虽然它们都是 AI 应用,但背后的架构大不相同。这两类架构既有共性也有区别,我相信大家在观看时很难发现它们的共性和区别在哪里。这正是学习过程中需要重点发现的。在课程设计中,我会帮助大家理解它们的共性和差异,这样大家就能在 AI 系统的共性基础上,逐步构建完整的知识结构。
刚才我们讲清楚了做这件事的动机和市场需求。既有动机又有市场需求,看来是可以做这件事的。但在开始之前,我相信大家都会有一些畏难情绪,毕竟面对不熟悉的知识时,人天性上都会有一些抗拒。
大家经常问的一个问题是:AI 这么难学,能学会吗?其实,大家觉得 AI 难学有两个原因。一个原因是,大部分公开资料都集中在 AI 理论、统计学和数学公式推导上,其中的形式化表达可能显得绕口且难以理解。另一个原因是,学完后不知道如何应用,不清楚落地实现时每一行代码怎么写。如果不掌握这些,就会觉得难学,因为不知道如何使用或价值所在。
为了解决这两个问题,我会提供一些非常现实和具体的案例。例如,为了理解机器学习过程,我经常用配钥匙的例子来描述。大家可能好奇这张图背后的含义,不用着急,后面我会展开这张图的细节继续讲解。

首先,我先来帮助大家建立一个体系,如左下角图所示,从人工智能大概念到机器学习、深度学习,再到最前沿的生成式人工智能发展。大家需要先掌握这个整体体系,然后在此基础上扩展其他知识。
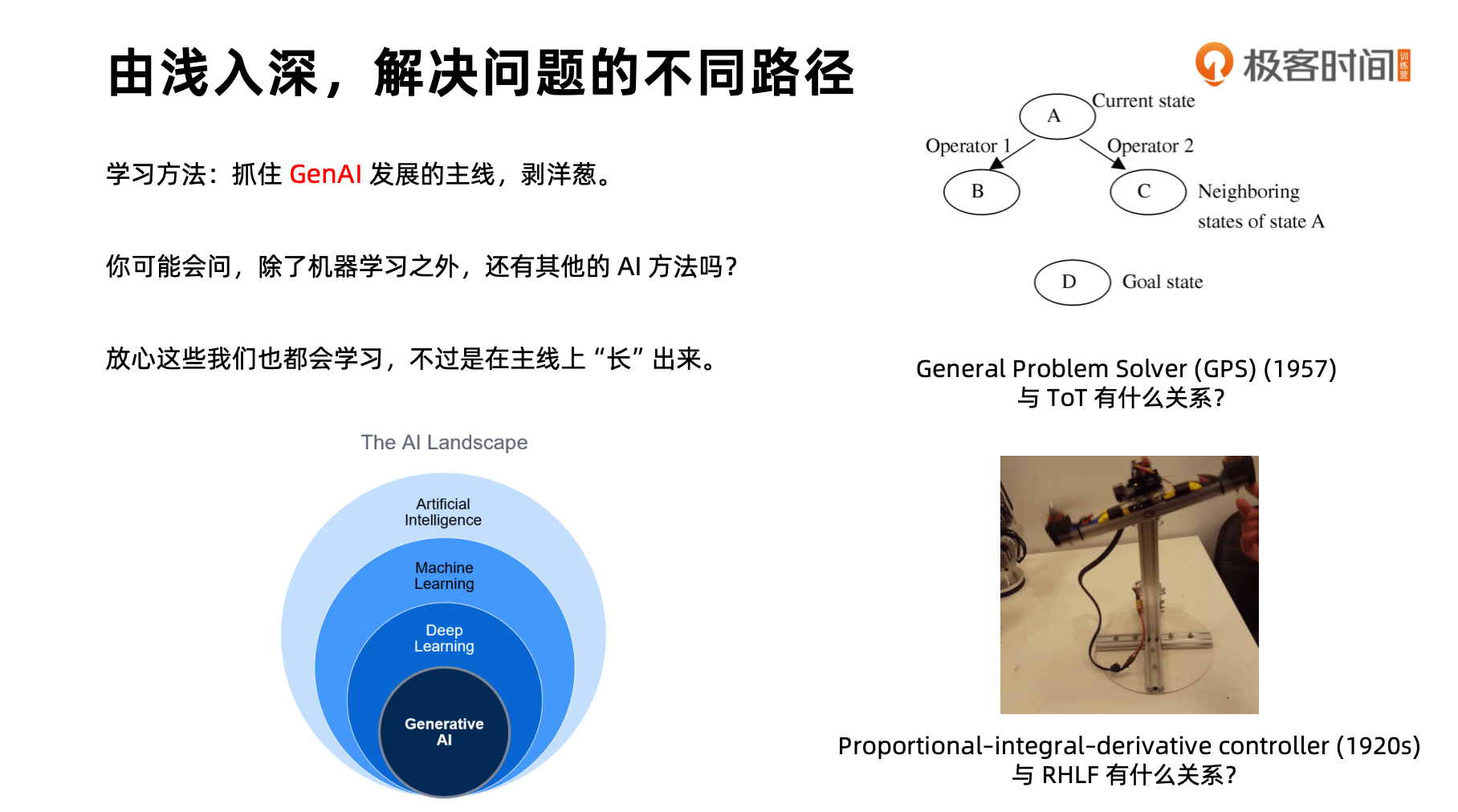
那人工智能还有其他知识吗?当然有。除了机器学习方法,AI 系统有多个学派。看右上角图,这是通用问题解决器(GPS),1957 年提出,也是在达特茅斯会议(人工智能术语确定的会议)上展示的最优秀人工智能程序。它使用类似树搜索的方法完成 AI 目标,将每个推理动作作为算子,推理状态作为状态机,通过算子流转解决数学推理问题。这是符号主义学派的典型工作,与神经网络学派不同。
再看右下角图,这是一个有两个螺旋桨的飞行器或机器人,如何保持平衡?算法使用控制论中的 PID 算法,与神经网络学派方式不同,属于行为主义学派。在课程中,我会介绍不同学派如何与以神经网络学派为主的主线(如左下角洋葱状图)产生关联。
大模型出现后,另外两个学派也焕发生机。例如,右上角的 GPS 发展到今天成为 Tree of Thought 中的主要算法,用于复杂思维链方法。右下角则演变为基于人类反馈的强化学习方法(RLHF)的理论来源,控制论学派演变出的强化学习方法。大家会看到,在神经网络学派主线上,又长出了其他学派的能力。这是我建立体系时的一个特点,我会结合各学派发展历史和大模型现状,梳理历史发展。
这样,大家学习后续知识时,会知道来源和发展脉络。讲完人工智能最外层及几大学派后,我们沿着神经网络主线和生成式人工智能主线继续深入。在机器学习相关课程中,我会展开各种方法。但在介绍前,这节课先让大家看看机器学习的本质是什么,让大家知道其实并不难。即使学习周边方法,都离不开主线本质:机器学习的本质就是数据压缩。
接下来,请看下面这个表格,它类似于数据库中的表,最上面一行是元数据(Meta Schema),描述了表中的信息。下面的每条记录就是一条数据,这些数据存储在数据库中会占用一定的空间资源。我们能否压缩这些数据呢?这个过程实际上就是机器学习或统计学习的过程,它非常像物理学家发现物理定律。
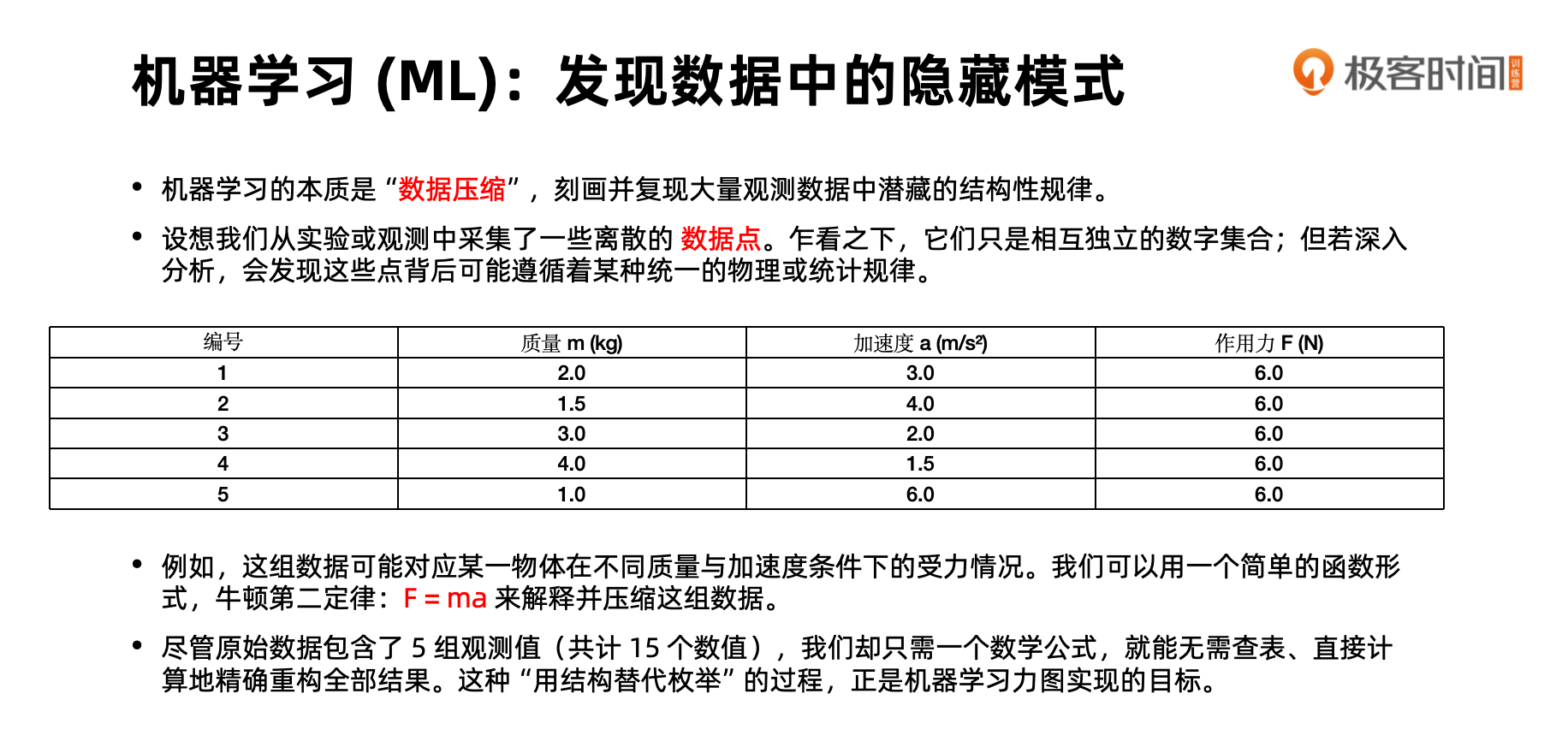
例如,物理学家在现实世界中采集许多天体或物体运动的记录,然后用这些记录进行数学建模,用一个数学公式表达所有采集的点。这本质上是一种数据压缩。我们用公式 F=ma 就可以表示表格中的所有点,以及世界上符合物理定律的无限点。当然,我们假设物理定律在世界中均匀存在,排除像《三体》中质子干扰地球的特殊情况。
基于已知经验,这种方式可以压缩规律。在人工智能中,规律发现本质上也是数据压缩,将数据集中的数据点用形式化的数学表达压缩,这种表达所占空间远小于所有数据点。因此,我们说机器学习本质上是在做数据压缩。从这个角度切入,大家能轻松理解机器学习在做什么。
刚才说了机器学习本质上在做压缩,那么它如何将无限数据压缩到有限参数上呢?这是一个很好理解的问题。回到左下角的图,训练数据表示现实世界存在的规律,可以用数据分布表示,但我们只能采集到观察到的数据,无法获取所有点。

现实世界的规律就像一把要配的钥匙。如何配出这把钥匙?首先,通过观察数据样式假设钥匙类型。然后,将左边锁上的每个数据点雕刻到右边的钥匙上。当所有点雕刻完成后,右边钥匙就会越来越像左边锁的信息。如果刻画了关键特征点,无需所有数据就能配出开锁的钥匙。右边钥匙用数学表达式或方程表示,雕刻数据的过程就是解方程的过程:通过代入已知条件解出模型中的未知数,即模型参数。
因此,模型参数越大,刻画细节的能力越强。例如,DeepSeek 模型参数已经超过 600B。同时,参数越多,要解的未知数越多,计算中需要的算力也越多。相信大家能通过这个隐喻快速理解机器学习训练的本质。

计算机科学家因此思考:能否用通用方式表达所有可能函数?只需激活部分参数,就能自由组合出符合目标场景的函数表达。后来,通过仿生人脑学习过程,使用深度学习方法实现了通用函数拟合。通过添加激活函数,深度网络可以拟合各种非线性表达。只要网络足够深,理论上能拟合各类函数。深度学习就像一把万能钥匙,可以拟合各种现实世界规律,只要参数足够多、网络层数足够深。为了加快收敛或高效处理信号,我们会引入仿生结构,例如用猫的神经结构处理视觉信号。
有了深度学习之后,大家可能会想:既然有了万能钥匙,把所有问题都交给它学习就好了。确实,前几年就是这样发展的。例如,在人脸识别、物体识别、NLP 分类和 embedding 计算中,都是将数据交给深度网络处理,过程中进行一些小修改,使模型结构更符合数据分布,提高参数利用效率。但本质上还是在利用深度学习的万能表达能力。
后来发现,每当新数据到来都需要重新训练模型,这严重违反了软件工程中的"Don’t repeat yourself"原则。于是大家思考:能否用一个模型一次训练,四处复用,解决所有下游任务?这就是生成式 AI 诞生的背景。
生成式 AI 要实现这个目标需要做两件事:第一,具备解决所有下游任务的知识,这需要超大参数容量来记忆知识,以及海量训练数据学习世界知识。GPT 通过全网爬取数据和大参数模型训练实现了这一点。第二,需要提供通用接口。原有的结构化接口针对特定任务,而自然语言对话接口可以解决所有问题,这就自然引入了提示工程方法。
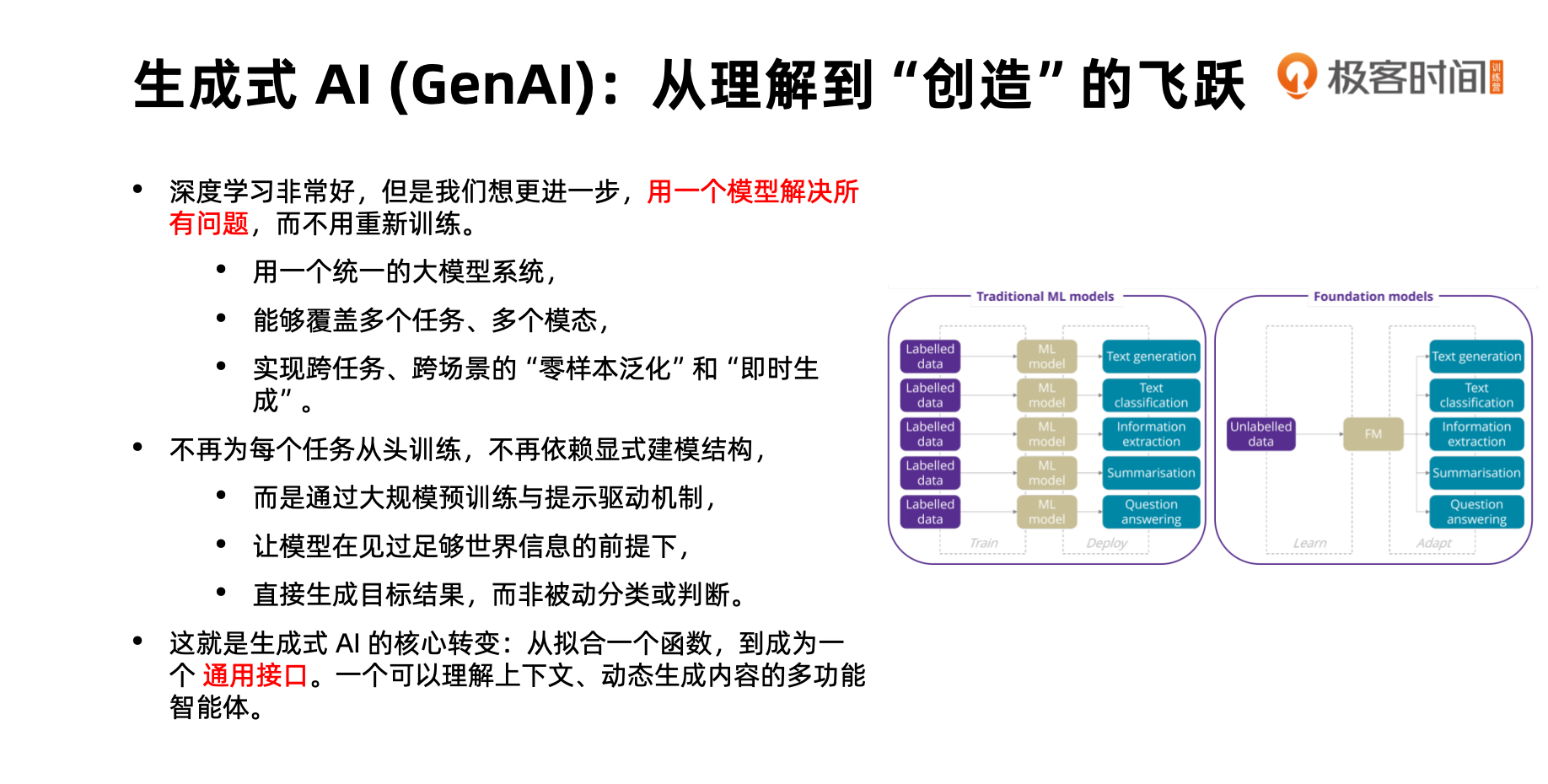
那么,人工智能发展到生成式 AI 就结束了吗?当然不是。现在各行各业都在拥抱 AI,担心被颠覆。但真正令人担忧的不是生成式 AI 本身的技术能力,而是其发展前景。
这次技术革命的不同之处在于:现在很少人讨论图灵测试有多难或多远,甚至不再将其视为终极目标。我们对 API 背后是人还是模型越来越难以分辨。这一轮生成式 AI 革命的终极目标是 AGI(通用人工智能)。
图灵对人工智能的构想即将实现,因为有理论支撑。左下角的智能体用生成式 AI 作为决策中心,配合工具和记忆,与外部环境交互,就能解决复杂问题。虽然智能体存在幻觉问题,但业界有整套解决方法,如添加安全护栏(guardrails)保证可用性。
更重要的是,我想证明为什么生成式 AI 驱动的智能体是图灵完备的。右下角的图灵机冯诺依曼实现包括控制单元、计算单元和记忆单元。生成式模型完全可以实现 CPU 的功能:发出控制指令、进行计算、控制外设和与存储交互。
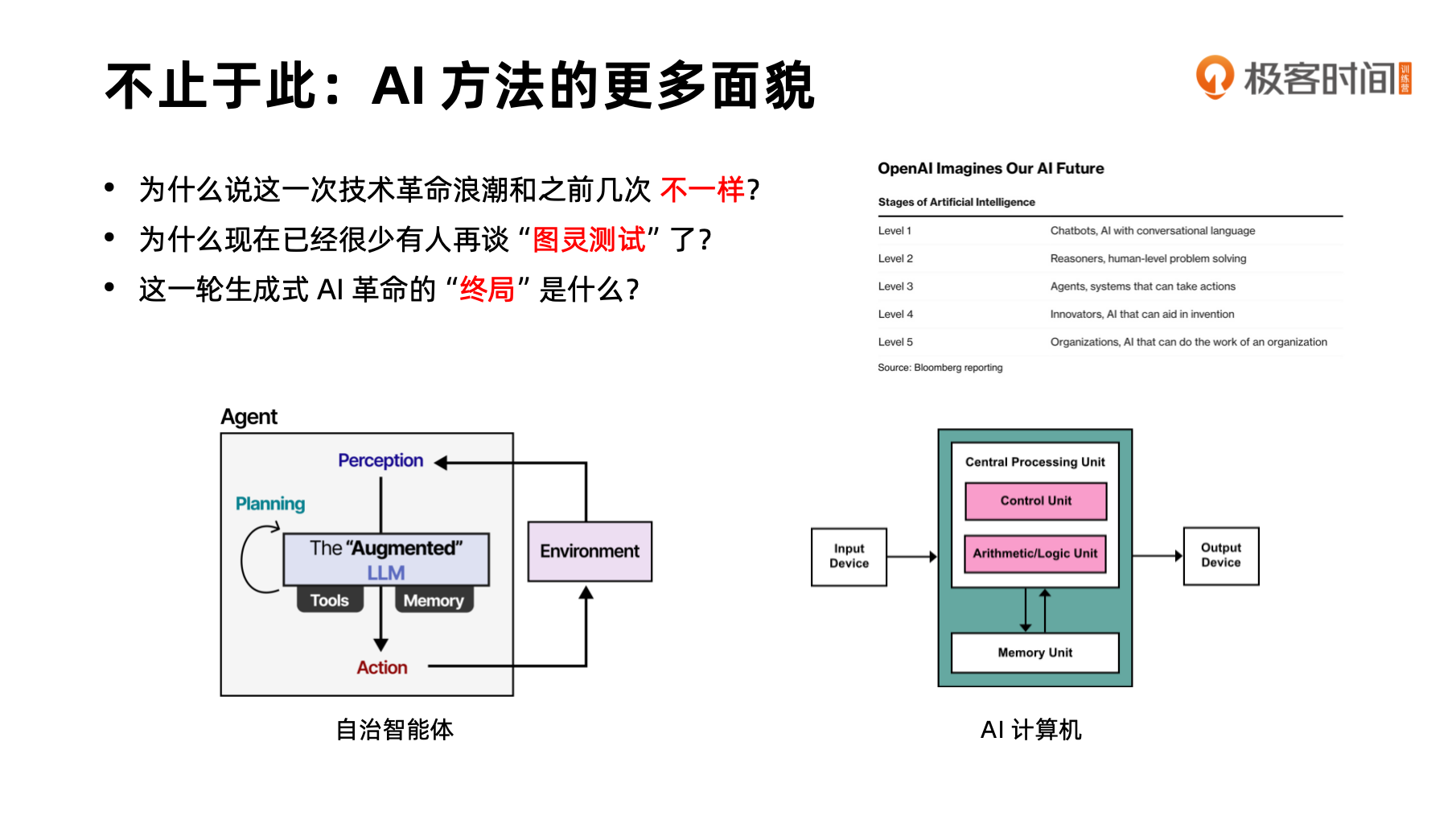
如果从这个角度还难以理解,可以用《三体》中的比喻:人类计算机让每个人抽象成门控单元,组成复杂计算机。生成式模型也可以作为门控单元完成逻辑运算,不受幻觉影响。用大模型组成计算机,自然是图灵完备的。随着能力增强,我们会让模型越来越强大,最终能完成所有任务。
因此,OpenAI 对 AGI 的规划正在逐步实现:从聊天机器人到推理能力,再到自由行动的智能体,进而完成创造类工作(如深度研究、算法发明),最后甚至能运营软件公司团队。
既然这轮技术革命的上限如此之高,大家就能理解为什么任何时候加入了解人工智能都不算晚了。这些知识会不断积累,渗透到各行各业,带来不可逆转的行业格局变革。
我们回到最开始提出的一个问题:在学习各种方法后,了解其历史、落地场景和关联后,如何完成工程项目呢?这里我先让大家思考一个问题:假如老板决定给你 1000 万,让你负责一个人工智能项目,作为技术团队负责人,你需要招募团队。你可以自由招募,但如何组建团队?你会招募什么样的人?肯定不能简单地招募一个有过算法经验的领导,然后委托他招募其他人,否则你可能被替代。那么你应该怎么做?
在思考这个问题时,不了解的同学可能有两块空白:第一,对 AI 系统架构的形成没有概念,因此不知道需要什么样的人;第二,即使对架构有概念,也不清楚团队成员如何合作,或自己如何参与合作。如果这两块是空白,就无法回答上述问题。

实际上,从业务场景到 AI 系统,这个过程中发生了多次转换。第一次转换是策略产品经理和策略团队将具体业务目标形式化,即业务问题抽象为数学问题。如果不转化为数学问题,就无法用 AI 方法优化。第二次转换是策略和架构团队将数学问题转化为工程问题。
以电商系统推荐为例,本质上是一个数学问题:我们希望推荐能最大化平台收益。平台收益如何计算?通过研究用户行为动线:浏览商品、进入落地页、加购、填地址、付款成功。我们需要预测整个行为链中每一步的概率,乘以客单价,得到最终收益,并最大化各因素的乘积。
第二步是实现算法,工程上如何推进?这其实是一个在线级联漏斗排序系统。这样,我们将 AI 业务问题转化为 AI 系统问题。但不同业务背景下,实现数学模型的架构选型不同,有各种 AI 架构模式或模板。课程中会结合内容展开,这里以电商系统为例。
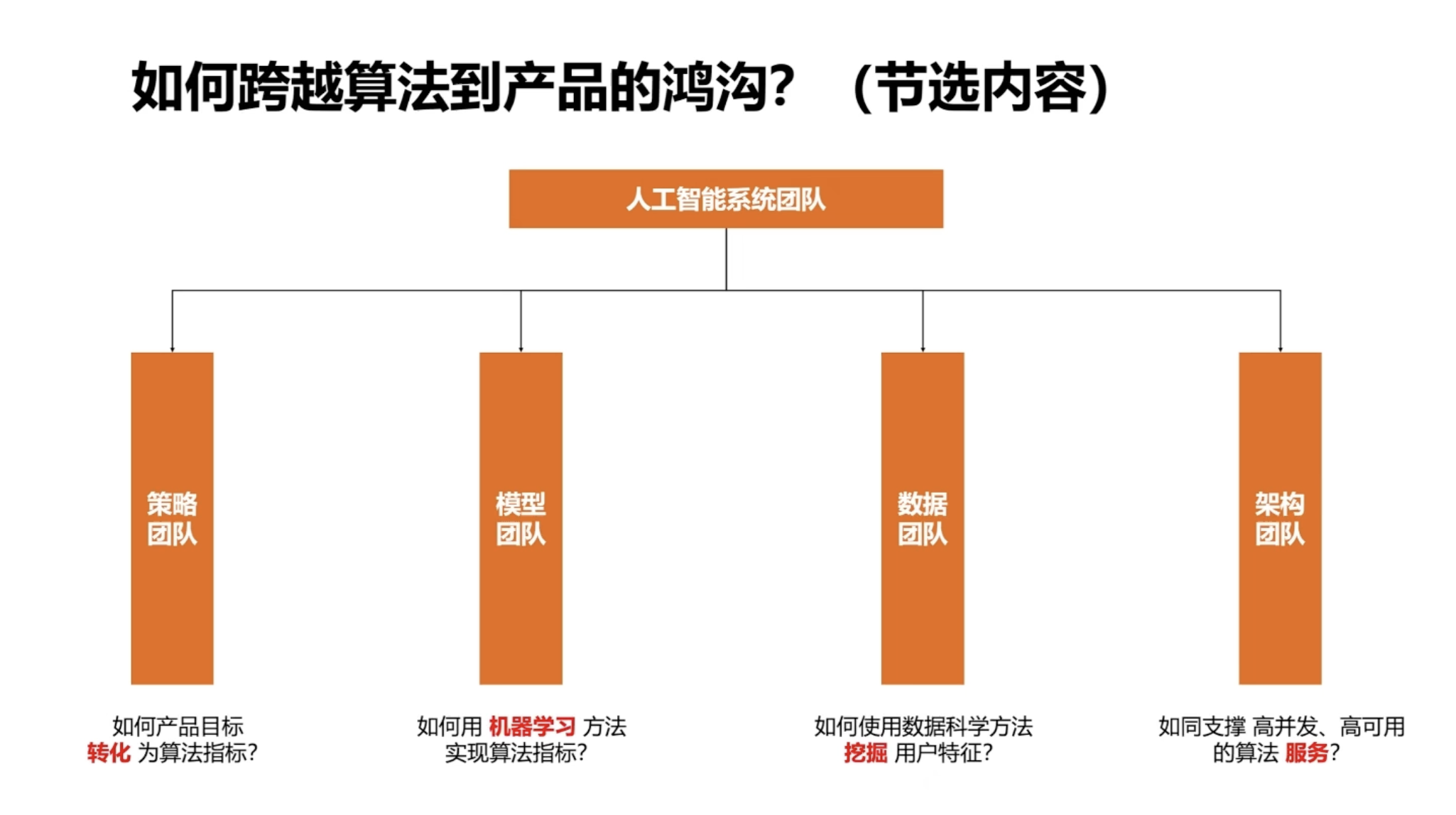
既然 AI 系统是多个团队合力的结果,架构形成后,他们如何合作?这里介绍一个最容易忽视的环节:AI 系统的团队组成。通常,在 AI 系统需求评审时,现场会有四个团队的代表:策略团队、模型团队、数据团队和架构团队。这对 AI 产品经理非常重要,需要知道合作方负责什么,如何形成系统。
策略团队负责结合产品经理的目标,将其转化为算法指标。模型团队使用机器学习方法优化各个算法指标。数据团队挖掘用户行为特征,提供给其他团队作为数据特征使用;数据团队还会搭建系统流水线,如批流一体的特征处理流水线和数据仓库,为其他团队提供接口。架构团队确保模型团队提供的在线模型能高效集成到系统中,并提供可靠的在线性能。
如果不了解这些团队背后的合作方式,就无从谈起如何搭建团队,或在加入 AI 团队后参与需求评审时,不知道面对的其他成员是谁,这会非常被动。AI 系统团队背后的故事,包括日常与产品经理的协作或与其他团队合作中可能遇到的问题。
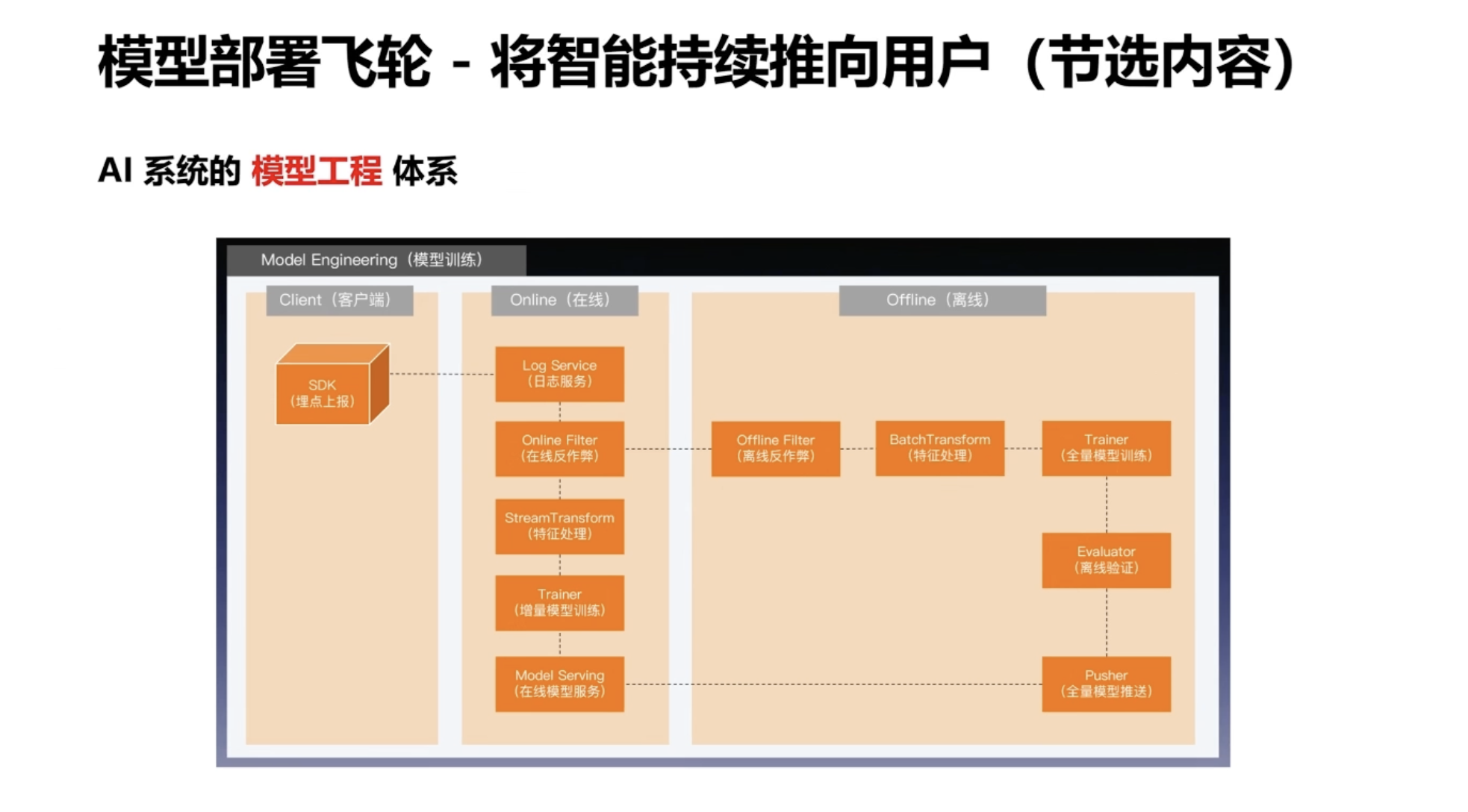
例如,数据团队不仅需要挖掘数据,使用复杂方法如知识图谱(左侧图),还需要搭建整个数据管道,为模型提供优质的在线特征库和离线数据仓库,以支持模型训练。模型工程体系由模型团队和架构团队合作构建,涵盖模型训练、数据回收、数据清洗到在线模型推送的全流程开发。这与传统的 CI/CD 不同,因为模型迭代频率极高,例如在线模型可能每 5 分钟更新一次,使用过去 5 分钟的在线用户数据。
但这些用户数据中可能存在污染,如作弊数据或噪声数据。如果不处理,在线模型受污染后性能会不稳定。因此,需要采用离线模型准入要求、在线指标监控和数据清洗策略等全套方案来保证稳定性。
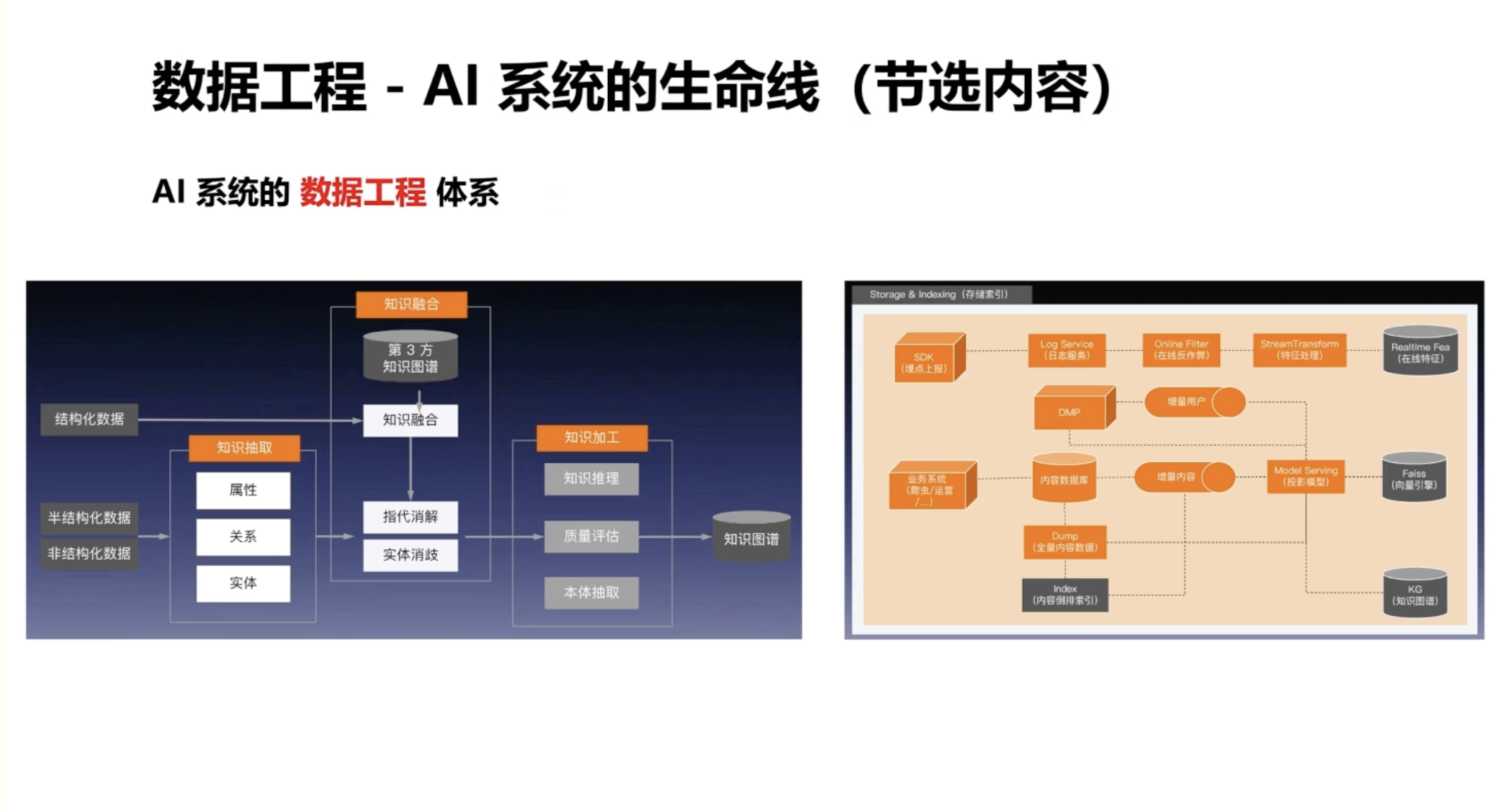
此外,如何将策略团队构建的数学模型进行在线架构拆分,使架构更好地匹配数学模型,并在保证几百毫秒延迟的前提下输出稳定的机器学习能力,涉及在线(online)、近线(nearline)和离线(offline)的设计。通过实时数据、近实时数据和历史数据的组合,实现性能与成本的权衡。
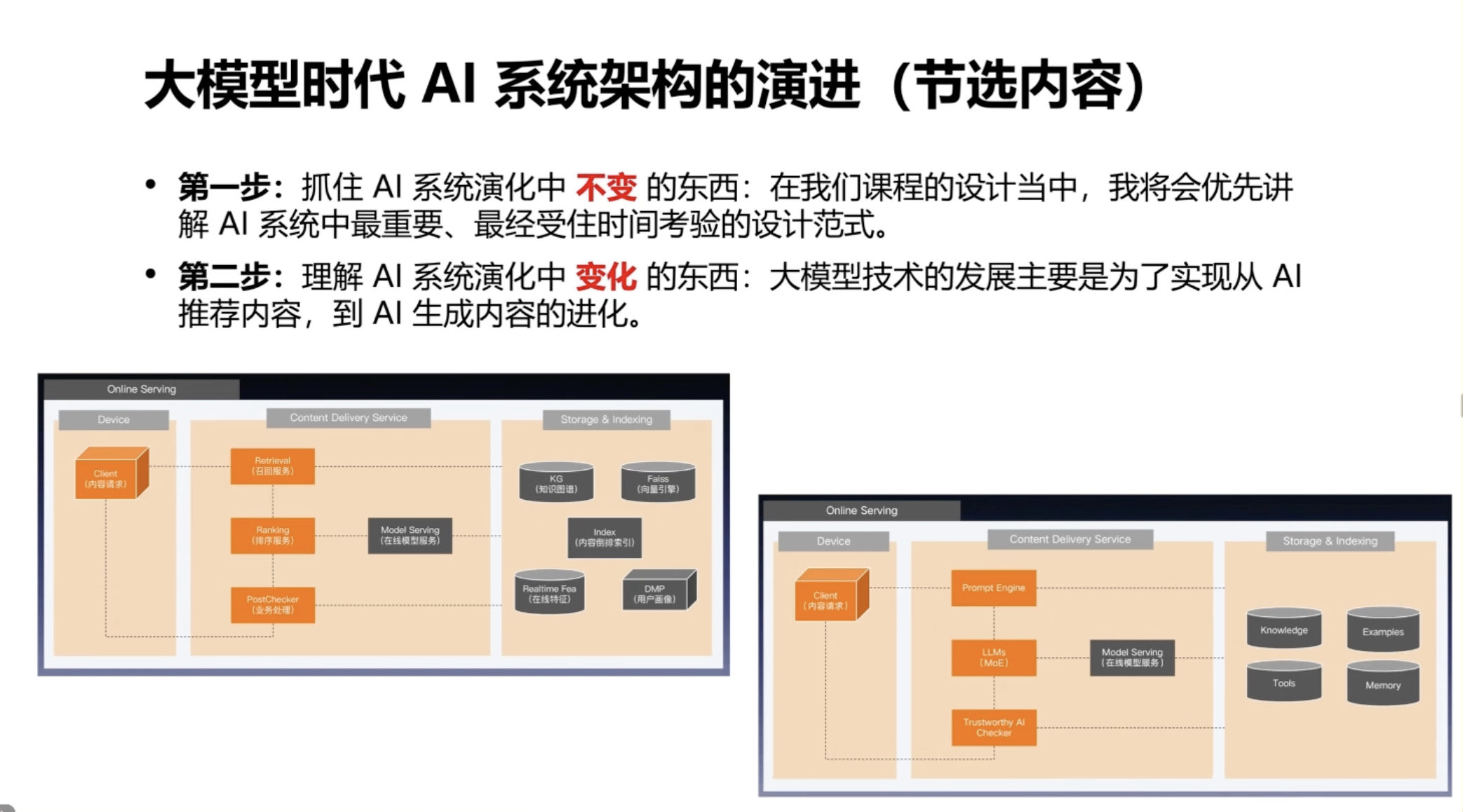
在整体知识体系创建中,我强调两个点:首先,关注不变的东西。例如,下面两张图(推荐系统图和大模型系统图)非常相似,表明一些架构模式经得起时间考验。做大模型系统的人大多来自上一代 AI 系统,架构范式和组件会复用。其次,关注变化的东西,因为它们推动行业变革,例如 tools、memory、examples、knowledge 对应现在热门的 MCP 技术、RAG 技术和 A2A 技术。
最后,我分享一段自己之前的思考:这一轮技术革命不同以往,将影响产业链各环节,创造大量人才需求。建议大家将工作向 AI 迁移,确保职业安全。当时是完美的切入时机,但现在仍属早期,具身智能和软件工程自动化等关键技术尚未突破,提前学习 AI 知识依然非常有益。
公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结

1. AI系统需要策略、模型、数据、架构四个团队的协作,后端工程师在多智能体系统中发挥关键作用,推动数字员工革命。 2. AI人才严重不足,市场上AI岗位需求快速增长,但科班出身的算法背景同学无法满足市场需求,AI人才结构出现了断层。 3. AI人才需求逐年上涨,各公司都在尽力囤积AI人才,AI人才已成为行业瓶颈。 4. AI系统的碎片化表现在不同落地场景和技术上,例如生成式AI、自动驾驶和推荐系统,这些看起来似乎不是同一种AI。 5. 学习工业级的AI系统的重要性在于AI系统的落地场景和技术碎片化,以及在开发市面上的产品项目时的困难。 6. AI市场上对人才需求最大的两个岗位是传统的搜索推荐系统和新兴的AI大模型系统,它们背后的技术形态大不相同。 7. 课程设计旨在帮助学习者理解AI系统的共性和差异,以逐步构建完整的知识结构。
2025-12-12给文章提建议
仅可试看部分内容,如需阅读全部内容,请付费购买文章所属专栏
《极客时间 VIP · 干货直播稿精选》
《极客时间 VIP · 干货直播稿精选》
立即购买
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
精选留言
由作者筛选后的优质留言将会公开显示,欢迎踊跃留言。
收起评论