

15 | 规则引擎:如何快速响应突发的爬虫需求?
DS Hunter

你好,我是 DS Hunter,反爬虫专家,又见面了。
我们前面很多地方都提到了规则引擎。这里再重申一下规则的定义:
规则(rule):使用任何技术手段,对线上请求特征按照指定的条件(condition)或方法(callback)进行检测验证,并执行指定操作的过程。在部分系统里,这个也被称为过滤器(filter)。
如果说低耦合是为了保护你不死,那么规则引擎就是你的战斗利器,相当于将军的兵器,来鉴别爬虫。严格来说,整个反爬系统所有的操作,最终都是各种形态的规则引擎。
这里我们把规则引擎分为后端和前端两部分来讨论。为了使论述更佳清晰易懂,这里我们将 BFF 的规则引擎认为是前端的部分。
此外,做好规则引擎之后,还是需要用上一章的低耦合的办法去接入的,你也可以根据上一讲的内容自行组合。
那么,我们就直接进入规则引擎的讲解,关注它本身的架构。
规则引擎:架构分析
从结构上来说,前后端是各有一套规则引擎的。其中,前端的和 BFF 紧密结合,我们可以放一起讨论。
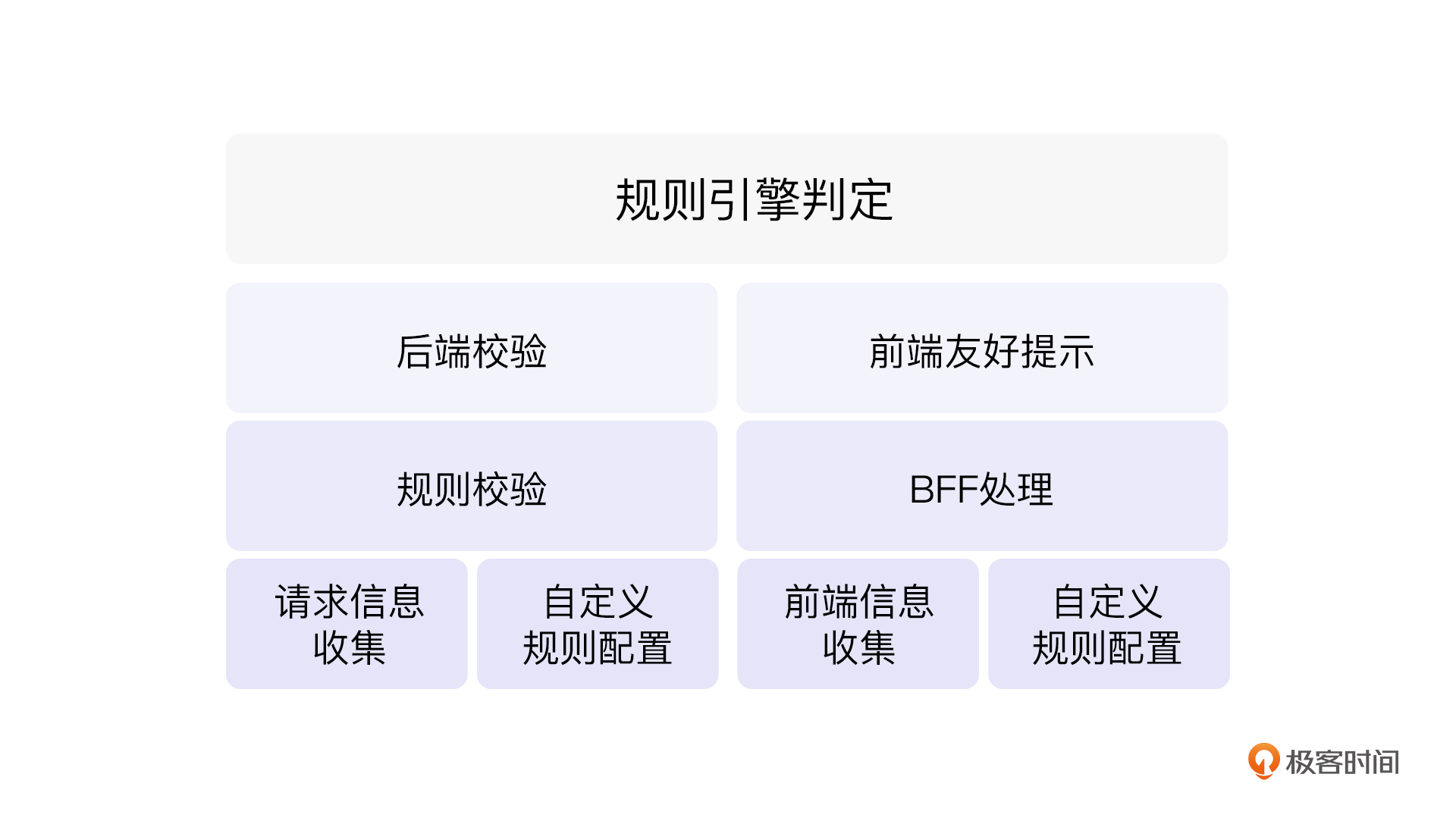
你可以从图里看到,无论是前端还是后端,大致流程都是收集信息,配置规则,对应的模块进行处理,然后根据规则进行指定的操作。这个过程我们可以认为是数据驱动,也可以认为是规则驱动。当然,正是因为规则驱动,所以才有了规则引擎这样的名字。
公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结

本文深入探讨了规则引擎在反爬虫系统中的重要性和实际应用。文章从架构分析和后端、前端两部分来讨论规则引擎的设计与应用。在架构分析部分,文章指出前后端各自拥有一套规则引擎,但也探讨了是否可以抽象出一个配置模块来同时对前后端进行配置。在后端规则引擎部分,文章详细讨论了信息收集模块和规则校验模块的设计原则和实现方式,强调了规则引擎的独立性和日志记录的重要性。在前端规则引擎部分,文章强调了前端规则引擎的辅助作用,以及在处理结果输出时需要保持低调。此外,文章还提到了BFF的预处理和前端处理的相关内容。总的来说,本文通过对规则引擎的架构分析和具体模块设计,为读者提供了深入了解规则引擎在反爬虫系统中的重要性和实际应用的知识。
仅可试看部分内容,如需阅读全部内容,请付费购买文章所属专栏
《反爬虫兵法演绎 20 讲》,新⼈⾸单¥59
《反爬虫兵法演绎 20 讲》,新⼈⾸单¥59
立即购买
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
全部留言(5)
- 最新
- 精选
 neohope前端信息收集不能直接下发 xPath,避免被爬虫抓。那么你有什么办法来处理这个问题呢? 1、各种骚操作,绕晕对方,但一旦被分析出来,就没啥用了 2、类似于中药抓方子,有用没用的都抓一把,你猜我抓了啥
neohope前端信息收集不能直接下发 xPath,避免被爬虫抓。那么你有什么办法来处理这个问题呢? 1、各种骚操作,绕晕对方,但一旦被分析出来,就没啥用了 2、类似于中药抓方子,有用没用的都抓一把,你猜我抓了啥作者回复: 行家呀。这个很像雷达的电子干扰,不能精准隐身,就干脆让目标多到数不清。
2022-03-17 peter请教老师一个问题: Q1:“32层二叉树”,搜不到啊,这不是一个通用的数据类型吧。 是不是指“需要搜索32次的二叉树”?
peter请教老师一个问题: Q1:“32层二叉树”,搜不到啊,这不是一个通用的数据类型吧。 是不是指“需要搜索32次的二叉树”?作者回复: 是这样的,ip地址是一个32位的整数,所以可以逐位判定1和0。也是前缀树,就是32层。只是字符串形式判4次,他判32次,但是树会小不少,因为很多不规则的掩码在二进制下是规则的。详情可以参考子网掩码相关知识。
2022-03-05 leslie“32 层二叉树虽然在广度上变小了,但是层数变多了。它的效率真的会更高吗?”只能说不一定,这个如同数据库索引,到底哪种更好,其实是视场景而定。
leslie“32 层二叉树虽然在广度上变小了,但是层数变多了。它的效率真的会更高吗?”只能说不一定,这个如同数据库索引,到底哪种更好,其实是视场景而定。作者回复: 是的,尤其是有些语言位运算一般,会更慢。
2022-03-04 椿3. 组合模式,且或规则组合2022-11-30归属地:上海
椿3. 组合模式,且或规则组合2022-11-30归属地:上海 阿白在拥有用户、设备、IP等特征维度画像数据之后,如果不自己构建规则引擎,维护一个通用的召回规则库,有什么比较好的实践经验吗?我目前能想到的是通过hive sql召回然后存到hive或者mysql,但是这样维护起来比较麻烦。2022-08-09归属地:广东
阿白在拥有用户、设备、IP等特征维度画像数据之后,如果不自己构建规则引擎,维护一个通用的召回规则库,有什么比较好的实践经验吗?我目前能想到的是通过hive sql召回然后存到hive或者mysql,但是这样维护起来比较麻烦。2022-08-09归属地:广东
收起评论

