卷疯了!最强开源大模型Llama 3发布,最大参数4000亿,小扎内心:大模型比元宇宙香多了
冬梅

Meta 首席执行官马克·扎克伯格在声明中表示:“我们相信 Meta AI 现在是您可以自由使用的最智能的人工智能助手。”
北京时间 4 月 19 日,Meta 官宣发布了其最先进开源大型语言模型的下一代产品——Llama 3。
据悉,Llama 3 在 24K GPU 集群上训练,使用了 15T 的数据,提供了 80 亿和 700 亿的预训练和指令微调版本。
Meta 在官方博客中表示,“得益于预训练和后训练的改进,我们的预训练和指令微调模型是目前 80 亿 和 700 亿 参数尺度下最好的模型。”
最大 4000 亿参数,性能直逼 GPT-4
值得注意的是,此次的大模型通过后期训练程序上的改进很大程度上降低了 Llama 3 的错误拒绝率,提高了对齐度,并增加了模型响应的多样性。Meta 研发团队还发现,推理、代码生成和指令跟随等能力也有了很大提高,这使得 Llama 3 的可操控性更强。
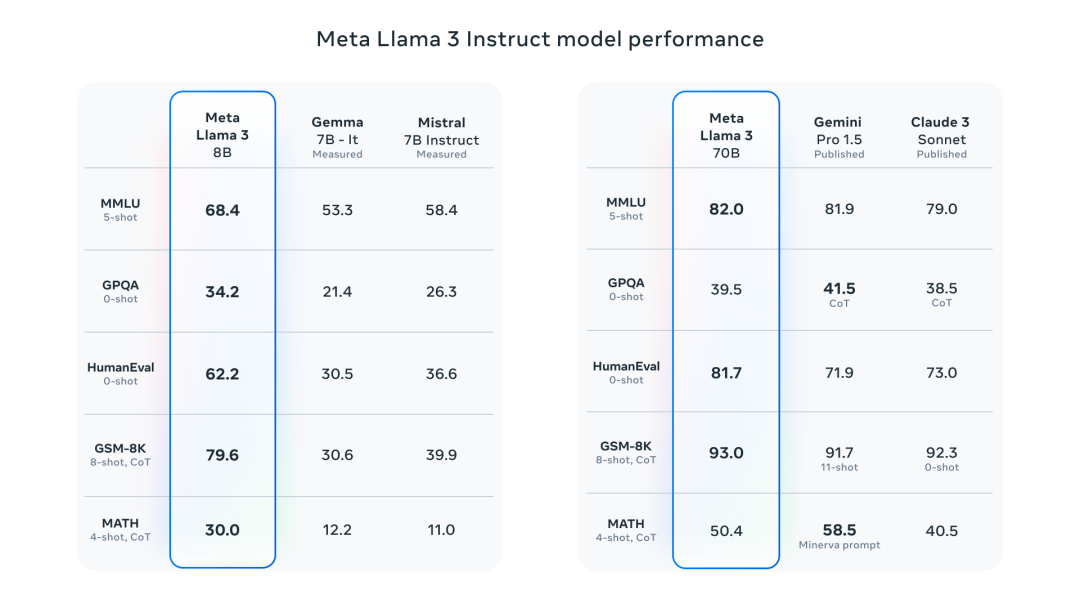
80 亿参数模型与 Gemma 7B 和 Mistral 7B Instruct 等模型相比在 MMLU、GPQA、HumanEval 等多项基准上均有更好表现。而 700 亿参数模型则超越了闭源超级明星大模型 Claude 3 Sonnet,且与谷歌的 Gemini Pro 1.5 在性能上不相上下。
此外,Meta 也测试了 Llama 3 在真实世界场景中的性能。他们专门开发了一个新的高质量人类评估集,该评估集包含 1800 个提示,涵盖 12 种关键用例(征求建议、头脑风暴、分类、封闭式问题解答、编码、创意写作、提取、角色 / 人物角色、开放式问题解答、推理、改写和总结)。
公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结

1. Meta发布了最先进的开源大型语言模型Llama 3,拥有80亿和700亿参数的预训练和指令微调版本,以及正在训练的超过4000亿参数的版本。 2. Llama 3在多项基准测试中表现出色,超越了闭源大模型,展现出强大的性能和多样性。 3. Llama 3的研发得益于四大关键要素:模型架构、预训练数据、扩大预训练规模和指令微调。 4. Llama 3的模型架构采用了纯解码器Transformer架构,使用了128K token的tokenizer和分组查询关注(GQA)来提高模型性能和推理效率。 5. 针对训练数据,Llama 3使用了超过15T的token进行预训练,包含多语言数据,并通过数据过滤管道确保训练数据的高质量。 6. 为了扩大预训练规模,Meta制定了详细的scaling laws,并采用了三种并行化方式来训练最大的Llama 3模型。 7. 指令微调方面,Meta创新地结合了监督微调、拒绝采样、近似策略优化和直接策略优化,以释放预训练模型的潜力。 8. Llama 3的80亿和700亿参数版本已上线Hugging Face可供下载,同时将陆续在多家云服务平台上线,并得到多家硬件平台的支持。 9. Meta希望Llama 3能实现多模式,支持多种语言,并具有更大的上下文窗口和改进的推理和编码能力。 10. Llama 3的研发团队通过改进后期训练程序,降低了错误拒绝率,提高了对齐度,并增加了模型响应的多样性。
该试读文章来自《AI 前线》,如需阅读全部文章,
请先领取课程
请先领取课程
免费领取
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
精选留言
由作者筛选后的优质留言将会公开显示,欢迎踊跃留言。
收起评论