关于 RAG、AI Agent、多模态,我们的理解与探索
李忠良

嘉宾 | 王元
编辑 | 李忠良
引言:在这个快速发展的数字时代,生成式 AI 不仅仅是一个概念,而是正在被塑造成为未来技术生态系统的核心。随着 LLM 的崛起,我们正处于一场技术革命的前沿。在 QCon 上海站上,王元讲师从构建企业级智能问答机器人方面的实战经验入手,深入分享了私有数据的接入、代理框架的运用,到多模态实践、语义缓存技术等 LLM 的新技术与新实践。本文为演讲整理文~
这次交流的主题是“Agent”,但我认为 Agent 并非独立存在,而是依赖于其他技术的融合。首先是私域数据,它对 Agent 来说,保证了输入源的处理。如果输入源处理不佳,就会导致 Agent 的性能下降;其次,Agent 技术基于大模型,大模型能力的提升会直接影响 Agent 的性能。但 Agent 也有缺点,比如增加系统的延时,这可以通过语义缓存技术来处理;另外,无论是基于 Agent 还是基于 AI 的新技术,都为测试带来了新的挑战。
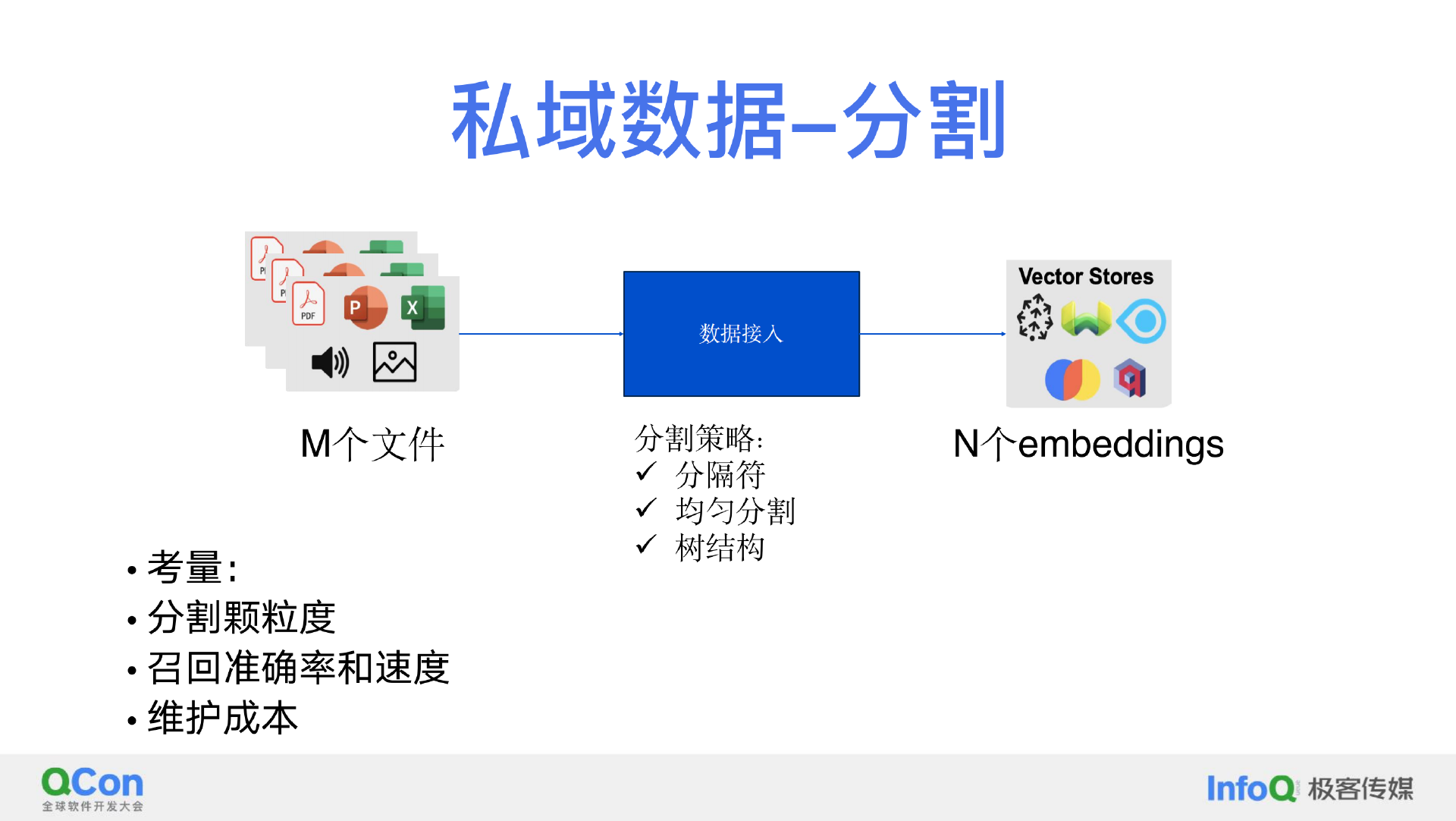
私域数据的分割、召回与评估
私域数据主要解决两个问题。首先是如何有效地将企业数据输入大语言模型。大语言模型的上下文处理能力是有限的,需要智能地选择数据以适应这一限制;其次,即使可以将全部数据放入模型的上下文,也不一定是最佳选择。最新的研究显示,大模型在处理上下文数据时效率呈 U 型曲线,意味着全量数据输入并非最优方案。
公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结

1. RAG 模型中的私域数据处理和召回环节至关重要,需要智能地选择数据以适应大语言模型的限制,并确保在召回过程中保留原始上下文信息的完整性。 2. RAG 模型的召回方法、数据分割大小和 Top-k 选择是影响性能的关键超参数,需要通过实验调优来确定最佳设置,有时需要结合 BM25 算法来提升搜索准确性。 3. AI Agent 模拟了人类处理问题的策略性思维结构,通过角色设定、规划、内存和动作模块实现了在大型语言模型环境中的群体智能模拟与构建。 4. AI Agent 的闭环系统特点在于规划的每个步骤都受到之前步骤的影响,这意味着 Agent 会多次调用大型语言模型,并对内存的管理更为复杂。 5. RAG 模型的排序结果与后续调用的大型语言模型紧密相关,不同的大型语言模型对排序敏感度有显著差异,因此需要考虑排序阶段的多维度因素进行优化。 6. 在评估 Agent 时,存在三种核心评估策略,包括冷启动阶段的评估、根据应用场景的具体需求进行评估以及评估 Agent 的泛化能力。 7. 多模态模型在文档智能领域的应用,尤其是针对文字密集型文档,探索了多模态融合技术,以解决 OCR 步骤繁琐的问题。 8. 在多模态研究中,引入了一种名为“语义缓存”的策略,该技术显著降低了调用延迟,实现了一个数量级以上的优化。 9. 在采用语义缓存时,必须重视缓存一致性问题,特别是在企业环境下,确保并行化处理的安全性至关重要。 10. Marvin 库在整合人类定义函数与大型语言模型(LLM)函数的应用中展现了独特价值,通过提供简洁清晰的接口设计,有效降低了 LLM 函数编程的复杂度。
该试读文章来自《AI 前线》,如需阅读全部文章,
请先领取课程
请先领取课程
免费领取
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
精选留言
由作者筛选后的优质留言将会公开显示,欢迎踊跃留言。
收起评论