哪里要动点哪里!腾讯联合清华、港科大推出全新图生视频大模型
傅宇琪

只需轻轻一点,静态的皮卡丘就会露出灿烂笑容:

咖啡会源源不断地冒出热气:

漂亮姐姐会朝你眨眼:
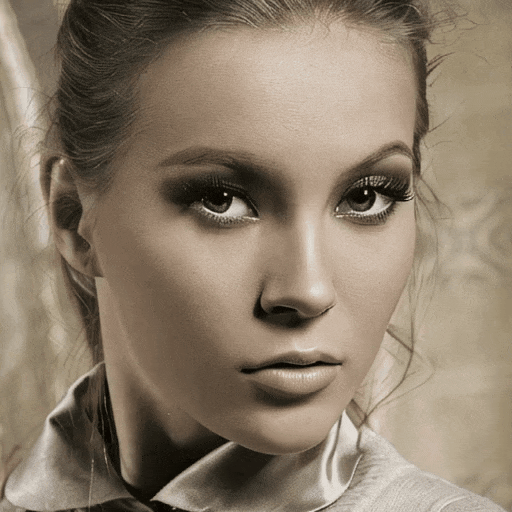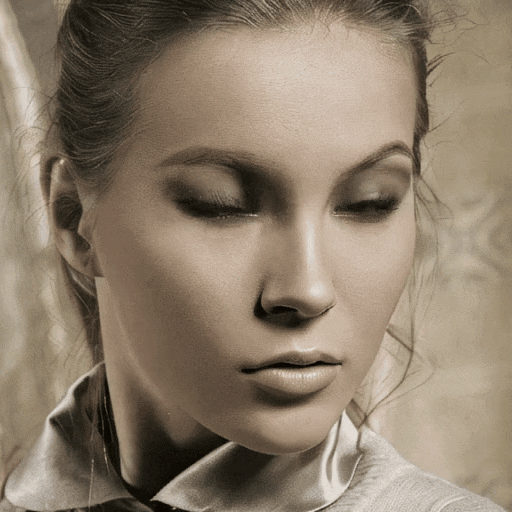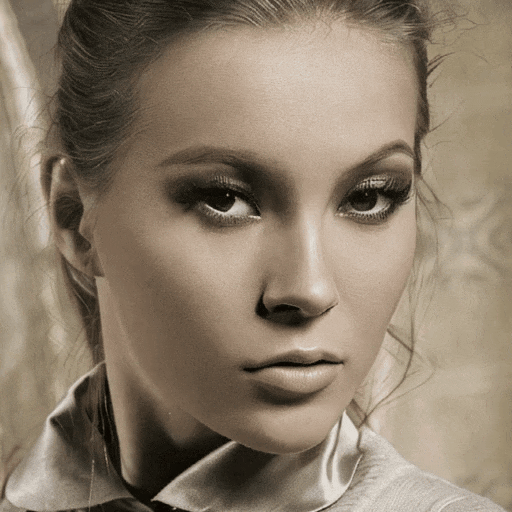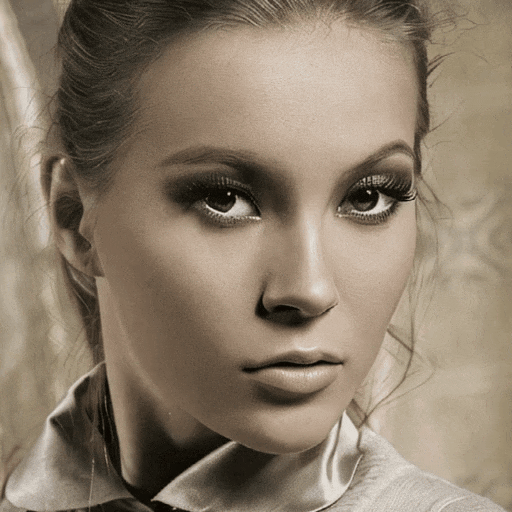
以上这些效果,均来自一个新的图生视频模型 Follow-Your-Click,由腾讯混元、清华大学和香港科技大学联合推出。
这个模型使用起来也非常简单:
把任意一张照片输入模型👉点击想选中的区域👉加上少量简单的提示词(如:动作、神态等)👉图片中原本静态的区域就能动起来。
相关研究论文已经在 arXiv 上公开,GitHub 上也放出代码,目前已经揽星 440+。

哪里要动点哪里
通过进一步测试,可以发现 Follow-Your-Click 能够精准控制画面的动态区域。
点击画面主体,它就能够控制火箭发射和汽车行驶:


也能够生成“大笑”、“生气”、“震惊”的表情:



同样是鸟图,点击小鸟,输入“摇头”、“扇翅膀”、“跳舞”,都能得到相应更精确的动作:



总之,就是想要哪里动,就点哪里。
研究团队还将 Follow-Your-Click 和其他视频生成模型进行了同题对比,以下是实验效果:


公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结

腾讯联合清华大学和香港科技大学推出了一款全新的图生视频大模型 Follow-Your-Click,该模型能够通过简单的点击和提示词,使静态图像中的特定区域产生动态效果。这一模型采用了图像语义分割工具和高效的首帧掩模策略,结合了名为 WebVid-Motion 的数据集和运动增强模块,以及基于光流的运动幅度控制,从而大大提升了可控图生视频的效率和可控性。虽然模型对于生成大型复杂人体动作仍存在局限性,但已经在实际应用中展现了潜力。该模型已经在《人民日报》的原创视频《江山如此多娇》中得到了应用。整体而言,这一模型的推出标志着在多模态领域取得了重要进展,为图像局部动画的实现提供了全新的可能性。
该试读文章来自《AI 前线》,如需阅读全部文章,
请先领取课程
请先领取课程
免费领取
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
精选留言
由作者筛选后的优质留言将会公开显示,欢迎踊跃留言。
收起评论