

11|字符串匹配:如何实现最快的grep工具
黄清昊

该思维导图由 AI 生成,仅供参考
你好,我是微扰君。
grep 命令,相信使用过 Linux 的同学都会非常熟悉,我们常常用它在 Linux 上进行文本搜索操作,具体来说就是从一段文本中查找某个字符串存在的行。下面一个典型的 grep 的使用例子,比如我可以用它来看看自己在 LeetCode 上用 Java 做了多少题:
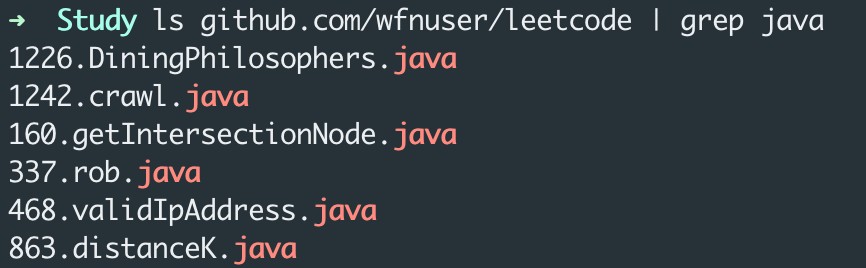
GNU Grep 则是 grep 命令的一个工业级实现,在项目官方 Readme 中作者是这样介绍它的:
This is GNU grep, the “fastest grep in the west” (we hope).
其实就是在说这是世界上最快的 grep 程序。当然,这款从上世纪就诞生的软件,敢这么说自己也是因为它有着十足的底气。
它避免了检查每一个 byte
对于被检查的 byte,只需要执行非常少的指令
第一点的主要优化就在于 GNU Grep 用到了非常知名的字符串匹配算法:Boyer Moore 算法,也就是我们常说的 BM 算法,它是目前已知的在大多数工业级应用场景中最快的字符串匹配算法,因而被广泛应用在各种需要搜索关键词的软件中,许多文档编辑器快捷键 ctrl+f 对应的搜索功能都是基于这个算法实现的。
公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结

Boyer-Moore算法是一种高效的字符串匹配算法,通过预处理模式串,利用“坏字符”和“好后缀”规则来加速匹配过程。该算法避免了不必要的比较,实现了极致的文本搜索功能。文章详细介绍了BM算法的实现原理和匹配过程,以及其在实际应用中的性能优势。此外,还介绍了Brute-Force算法、KMP算法和Rabin-Karp算法等不同的字符串匹配算法,以及它们的优缺点。总的来说,本文对于想要了解字符串匹配技术特点的读者具有很高的参考价值。BM算法的特点在于利用预处理和空间换时间的思想,避免了不必要的比较,实现了高效的字符串匹配。文章还提到了BM算法的时间复杂度和理论性能,以及对读者的课后作业建议。通过学习BM算法,读者可以深入理解算法和计算机底层原理,提高程序性能。
仅可试看部分内容,如需阅读全部内容,请付费购买文章所属专栏
《业务开发算法 50 讲》,新⼈⾸单¥59
《业务开发算法 50 讲》,新⼈⾸单¥59
立即购买
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
全部留言(5)
- 最新
- 精选
- Paul ShanBM算法和KMP算法是类似的,都是采用了预处理来加快查询,区别是KMP扫描和匹配方向是相同的,都是从左到右,BM扫描从左到右,匹配从右到左,在字符串差异比较大的情况,可以跳过更多,这也是坏字符算法的作用,但是仅仅凭着坏字符算法处理两个字符串比较接近的情况,复杂度就会退化为O(m*n),这个时候引入KMP类似的子串跳转算法,避免了最差的情况,可以取得O(m+n)。坏字符类似于粗调,只用到了当前不匹配的字符,好后缀类似于精调,用到了不包括当前字符所有已经匹配的字符串。BM和KMP算法和红黑树算法一样,属于我一看就忘的类型,:)。
作者回复: 哈哈哈 确实是看了就忘 不过也不太有手写的机会,了解原理我觉得也差不多啦
2022-01-047  Jumpstr = AMPLEMABCABCMABC,pattern = ABCABCMABC,示例代码有点问题。
Jumpstr = AMPLEMABCABCMABC,pattern = ABCABCMABC,示例代码有点问题。作者回复: 示例代码确实有问题 可以提个issue给我哈 我上次没来得及修复
2022-04-012 王建新leetcode好像有类似很多的字符串匹配题目 思路就是这样的
王建新leetcode好像有类似很多的字符串匹配题目 思路就是这样的作者回复: 一般面试的时候不会要求KMP这样难度的代码 能写暴力对比的就行~
2022-01-25 Daneil不好意思,刚才看错了
Daneil不好意思,刚才看错了作者回复: 哈哈哈 没事 多多交流噻~
2022-01-06- Daneil好后缀计算的代码中,14-17行后缀的遍历有误。应当让后缀从小到大去进行遍历,而不是让后缀从大到小,一旦有一个大的后缀在gs表中,那么他的所有子后缀都不需要遍历,一定在gs表中。2022-01-06
收起评论

