

09|二分:如何高效查询Kafka中的消息?

该思维导图由 AI 生成,仅供参考
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

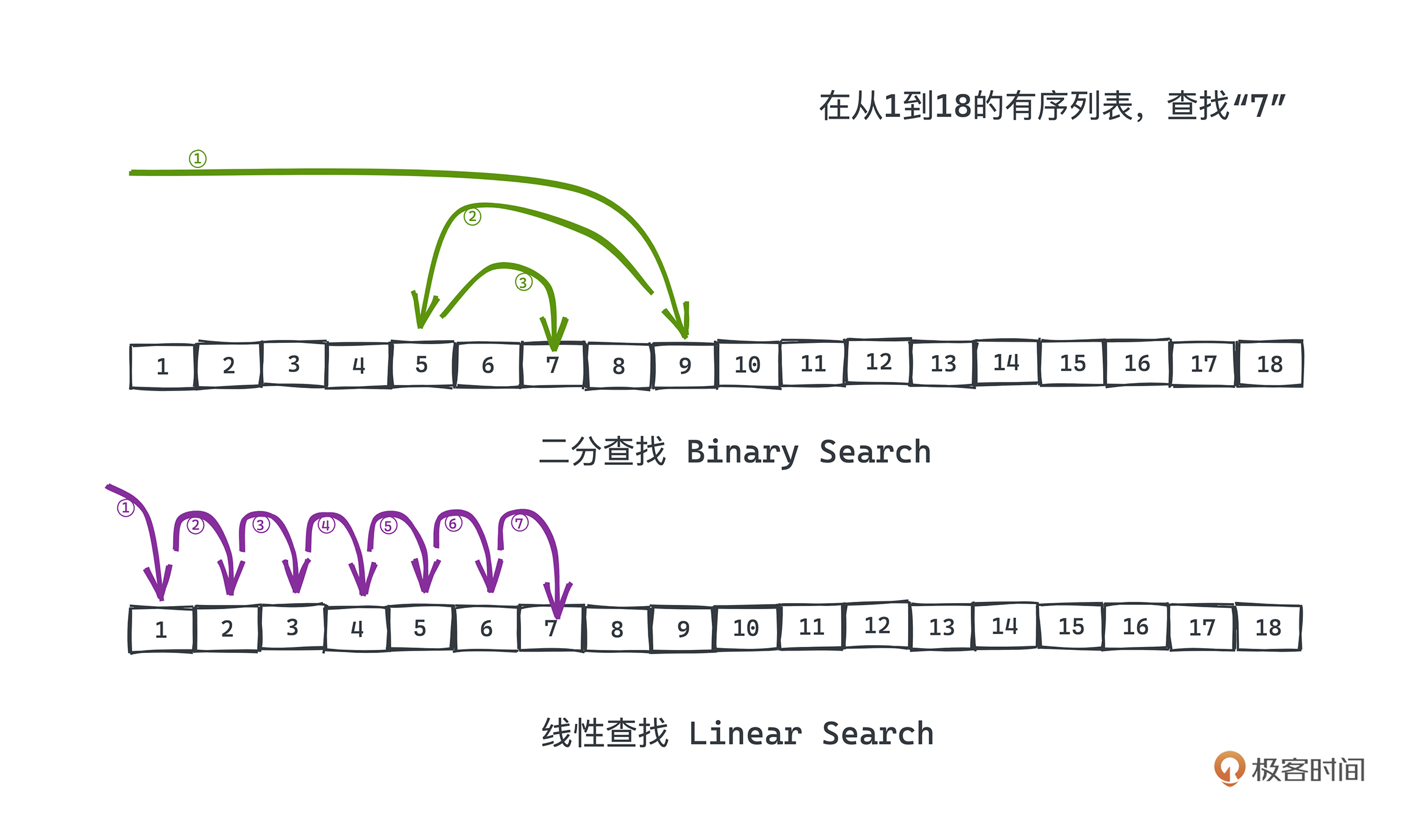
Kafka中的二分查找算法应用 Kafka作为一款性能强大且常用的分布式消息队列,其存储消息的日志文件采用了分片和索引的方式。本文通过生动的例子和代码实现,深入浅出地介绍了Kafka中二分查找算法的原理和应用。通过对索引文件的分析,展示了二分查找在快速定位消息在日志文件中位置的重要性。文章还详细解释了Kafka中二分查找算法的优化策略,包括冷热分区的二分查询算法,以及基于mmap技术将磁盘文件映射到虚拟内存空间的实现方式。这些优化策略有效地提高了算法的性能和效率。此外,文章指出了在工程中应用算法需要充分了解计算机基础知识和操作系统的运行原理,才能真正写出高性能的代码。通过Kafka中的实际应用案例,生动地展示了二分查找算法在工程中的重要性和实际价值。 文章还提出了一个问题:为什么在许多情况下,我们还需要使用诸如红黑树、B+树这样的复杂索引结构呢?比如InnoDB的索引文件就采用了B+Tree,它和Kafka所选择的顺序稀疏索引文件各有什么优劣呢?这个问题引发了对不同索引结构的讨论,为读者提供了更多思考和探索的空间。 通过本文的总结,读者可以快速了解Kafka中二分查找算法的应用,以及在工程中的重要性和实际价值。同时,读者也被引导思考不同索引结构的优劣,为进一步学习和探索提供了思路。
《业务开发算法 50 讲》,新⼈⾸单¥59

全部留言(9)
- 最新
- 精选
 西门吹牛B+ 树就是为了磁盘存储而生,可以减少磁盘的访问次数,同时也可提供顺序访问,Kafka 采用顺序稀疏索引文件,同一分区的 log 都是顺序写的,采用稀疏索引,一方面节省空间,只要找个开始的位置,顺序遍历即可,这也和场景有关,消息是按分区顺序写入,消费端是按分区顺序成批拉取,二分找到起始位置,顺序读取即可,读写磁盘都是分区内顺序读写
西门吹牛B+ 树就是为了磁盘存储而生,可以减少磁盘的访问次数,同时也可提供顺序访问,Kafka 采用顺序稀疏索引文件,同一分区的 log 都是顺序写的,采用稀疏索引,一方面节省空间,只要找个开始的位置,顺序遍历即可,这也和场景有关,消息是按分区顺序写入,消费端是按分区顺序成批拉取,二分找到起始位置,顺序读取即可,读写磁盘都是分区内顺序读写作者回复: 写得很好~
2022-01-224 第一装甲集群司令克莱斯特应该整理一下常用中间件的索引类型 MySQL innodb: B+ Tree Oracle/Mongodb:B Tree ES:倒排索引 Kafka:稀疏索引 这节还学到了热区,冷区,还有缺页中断。
第一装甲集群司令克莱斯特应该整理一下常用中间件的索引类型 MySQL innodb: B+ Tree Oracle/Mongodb:B Tree ES:倒排索引 Kafka:稀疏索引 这节还学到了热区,冷区,还有缺页中断。作者回复: 整理的不错 还有一种叫 log merge structure tree 的存储类型 我们之后也会讲解~
2022-01-032- Paul Shan索引文件和红黑树查询量级是一样的,都是log n,索引文件实现简单,红黑树实现复杂,红黑树可以插入删除,合并起来可以对一个节点Key做任意变化,索引文件对于频繁的插入删除,效率会退化,最后往往需要O(n)的复杂度去重建索引,代价比较大。
作者回复: 说得没错;所以在日志文件这种只追加不修改的场景下就很合适。
2021-12-301  宋照磊我的理解稀疏索引对应的场景是因为经常要顺序批量查询,而MySQL常用于随机查询,所以用树结构
宋照磊我的理解稀疏索引对应的场景是因为经常要顺序批量查询,而MySQL常用于随机查询,所以用树结构作者回复: 相比于树更重要的原因在于树支持删改,而线性索引删改成本很高。 至于顺序查询,B+ Tree 叶子结点间有链接,也可以顺序批量查询。我们之后会讲解。 可以加微信 constant_variation 一起学习~
2022-01-04 对方正在输入。。。老师我是这样理解的:稀疏索引的方式和b➕树比起来最大的不同是稀疏索引把所有索引都放到一层,b➕树有m层,所以这样看起来洗漱索引优点是实现简单,但是不利于大数据量的存储,如果量很大,导致这一层的索引文件太多,会严重影响这一层的二分查找的效率。消息队列的消息存活一般都有一定时间限制的,kafka就是默认7天有效,单个partition的数据量一般都不会太大,就算如果量太大也可以采用横向扩展分片树的方式来控制每个partition的数据量上限。消息队列的这一特性保证了单个partition的数据量上限,所以选择了实现简单的稀疏索引
对方正在输入。。。老师我是这样理解的:稀疏索引的方式和b➕树比起来最大的不同是稀疏索引把所有索引都放到一层,b➕树有m层,所以这样看起来洗漱索引优点是实现简单,但是不利于大数据量的存储,如果量很大,导致这一层的索引文件太多,会严重影响这一层的二分查找的效率。消息队列的消息存活一般都有一定时间限制的,kafka就是默认7天有效,单个partition的数据量一般都不会太大,就算如果量太大也可以采用横向扩展分片树的方式来控制每个partition的数据量上限。消息队列的这一特性保证了单个partition的数据量上限,所以选择了实现简单的稀疏索引作者回复: 其实和b+树相比更重要的区别不在于是否稀疏;而在于b+树索引可以支持数据的改动,但线性的索引表在修改的时候会带来很大的成本;但是在日志存储这种只追加不删除的场景里,就很合适。
2022-01-022 丶get: 冷热分区 + 二分查找。 感觉自己还得再补补计算机基础了。
丶get: 冷热分区 + 二分查找。 感觉自己还得再补补计算机基础了。作者回复: 哈哈哈 这个冷热分区确实比较难想到;kafka官方也没有什么动作直到社区有人提出才意识到;并且从讨论中可以看出,PMC对底层系统的认识也是有盲区的;所以不用担心哦 一直学习就可以了~
2021-12-30 SevenHe二分查找其实除了用于算法和工程实战以外,解决实际问题的时候也可以考虑采用二分查找的思想,比如快速定位Bug的位置2022-03-243
SevenHe二分查找其实除了用于算法和工程实战以外,解决实际问题的时候也可以考虑采用二分查找的思想,比如快速定位Bug的位置2022-03-243 拓山1、B+树支持范围查、顺序查等能力,且由于索引层级少,很适合磁盘文件读的场景,但数据库的写能力没有kafka要求那么高。 2、kafka的特性是快!因此它不能严格按照B+那种严格的存储顺序去写入。它采用的稀疏hash、追加文件方式都是突出写入快读取快的性能,但它就不能做范围查询、索引查询了。2023-08-09归属地:浙江1
拓山1、B+树支持范围查、顺序查等能力,且由于索引层级少,很适合磁盘文件读的场景,但数据库的写能力没有kafka要求那么高。 2、kafka的特性是快!因此它不能严格按照B+那种严格的存储顺序去写入。它采用的稀疏hash、追加文件方式都是突出写入快读取快的性能,但它就不能做范围查询、索引查询了。2023-08-09归属地:浙江1
 雨落~紫竹第一 修改 第二 只有叶子结点存储数据2022-07-11
雨落~紫竹第一 修改 第二 只有叶子结点存储数据2022-07-11

