

08|外部排序:如何为TB级数据排序?

该思维导图由 AI 生成,仅供参考
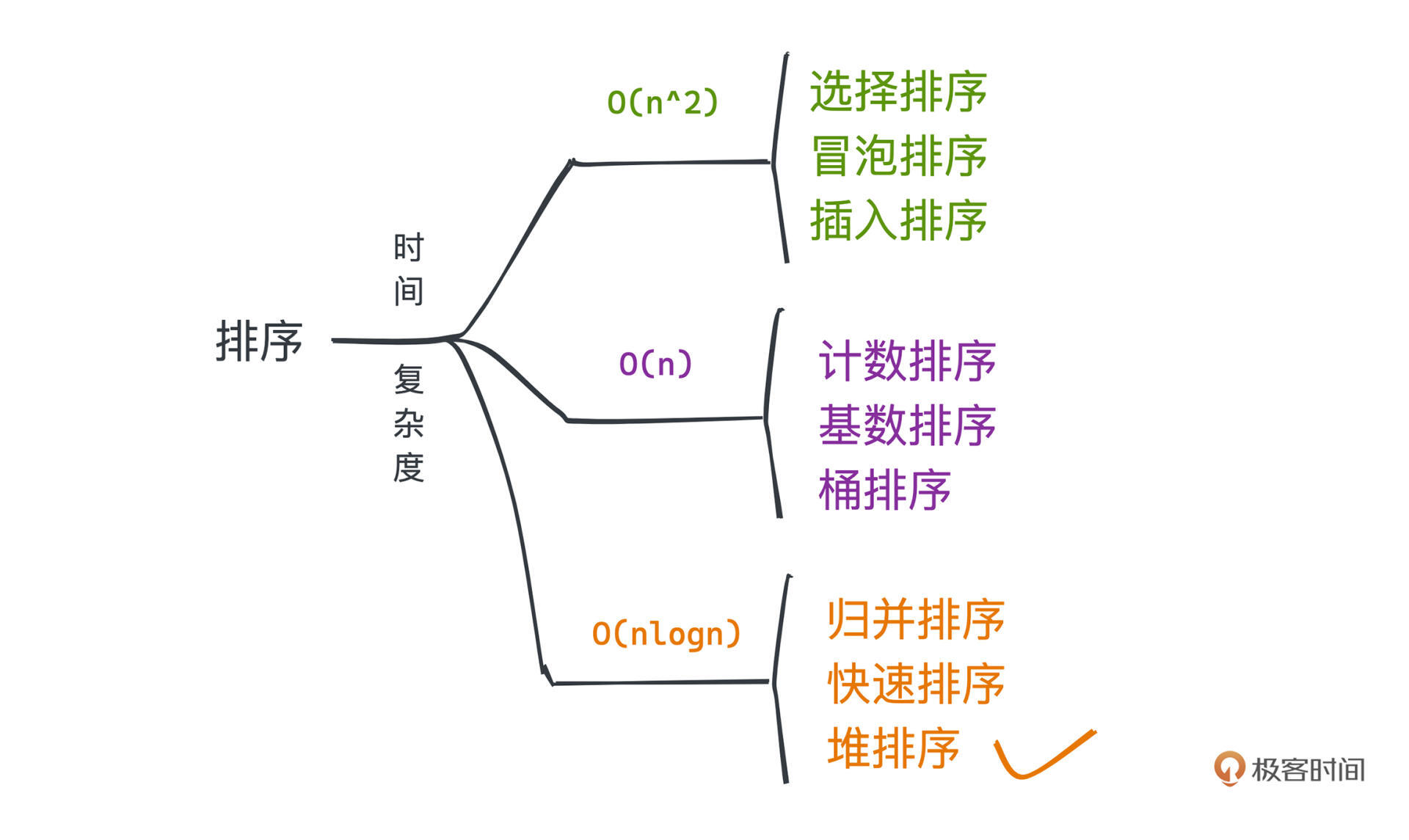
排序
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

外部排序算法是一种处理TB级数据排序的重要算法。当数据量过大无法一次性放入内存时,外部排序算法通过借助外部存储进行排序。文章首先介绍了排序算法的基本概念和常见的时间复杂度分类,然后引出了TB级数据排序这一实际问题。作者提到了在实际工程中,经常会遇到内存中放不下所有数据的排序场景,这时就需要使用外部排序算法。文章详细介绍了外部排序的基本思想和实现过程,包括部分排序阶段和归并阶段。通过举例和描述,让读者了解了外部排序的具体操作流程和原理。最后,文章强调了外部排序在处理大量数据时的重要性,并指出外部排序常常采用归并排序的思想进行实现。此外,文章还介绍了如何降低归并层数以及败者树算法的思想和实现过程。整体来说,本文通过介绍外部排序算法,帮助读者了解了如何处理TB级数据排序的问题,为读者提供了一种解决大规模数据排序的思路和方法。
《业务开发算法 50 讲》,新⼈⾸单¥59

全部留言(10)
- 最新
- 精选
- Paul Shan败者树和堆实现是相似的,量级上的复杂度也相同,具体有两点不同,第一,队列长度固定,第二,插入位置在叶节点。败者树是为多路归并量身定做的,效率应该更高,堆原来为了维护满二叉树的工作在多路归并中是不需要的。败者树和胜者树相比,树的中间节点记录的内容要更全,胜者树,胜出的元素会多次重复,这样中间节点的信息丢失,下一次比赛无法充分利用以前的比赛结果。败者树每个中间节点都记录了需要通关的门槛,而且不重复,一路比较即可。 基于线性排列的对任意文本可能会有点问题,如果都是字母单词应该可以,可以把单词按照首字母先分好文件,再按照第二个,递归排序。 1TB,假设内存是1G,分成1000个顺位文件,请问老师这里的归并路数可不可以直接选用1000,一次归并即可,因为归并的时候理论上内存只用存储树的节点数目(大约2000个)。
作者回复: 关于败者树的总结的不错~ 欢迎+v: constant_variation 一起讨论。 不过败者树、胜者树的主要区别在于内存的访问次数;胜者树是和兄弟节点做比较,所以取出父节点还要再取一次子节点;访存次数更多。败者树则解决了这个问题。 而堆则必然每次都需要比较两次。 关于归并路数,原则上不能选择很大的归并路数;内存读取是按照页为单位读取的哈;不是说内存用了2000个树节点的空间。
2021-12-2825 
 qinsi外部排序算法历史悠久,像基数排序甚至在电子计算机出现之前就被用来排序打孔卡。
qinsi外部排序算法历史悠久,像基数排序甚至在电子计算机出现之前就被用来排序打孔卡。作者回复: 哈哈哈 涨知识了
2021-12-303 一单成名有个问题没有理解,外部数据越归并越多了,每一次归并需要读入内存就越来越多,那还是会产生内存不足的问题?
一单成名有个问题没有理解,外部数据越归并越多了,每一次归并需要读入内存就越来越多,那还是会产生内存不足的问题?作者回复: 归并是可以逐段进行的哦 只要一段段读入两个文件的一部分内容并比较合并,直至读完整个文件即可利用有限的内存对理论上无限的外存进行排序
2022-01-101- ppd0705算法题使用败者树实现-golang版本,参考C++版本写了半天感觉还是对败者树有点陌生~ ```go package main type ListNode struct { Val int Next *ListNode } type loserTree struct { tree []int leaves []*ListNode } var dummyVal = 100000 var dummyListNode = ListNode{Val: dummyVal} func New(leaves []*ListNode) *loserTree { k := len(leaves) if k & 1 == 1 { leaves = append(leaves, &dummyListNode) k++ } lt := &loserTree{ tree: make([]int, k), leaves: leaves, } if k > 0 { lt.init() } return lt } func (lt *loserTree) init() { lt.tree[0] = lt.getWinner(0) } func (lt *loserTree) getWinner(idx int) int { if idx == 0 { return lt.getWinner(1) } if idx >= len(lt.tree) { return idx - len(lt.tree) } left := lt.getWinner(idx*2) right := lt.getWinner(idx*2+1) if lt.leaves[left] == nil { lt.leaves[left] = &dummyListNode } if lt.leaves[right] == nil { lt.leaves[right] = &dummyListNode } if lt.leaves[left].Val < lt.leaves[right].Val { left, right = right, left } lt.tree[idx] = left return right } func (lt *loserTree) Pop() *ListNode { if len(lt.tree) == 0 { return &dummyListNode } treeWinner := lt.tree[0] winner := lt.leaves[treeWinner] lt.leaves[treeWinner] = winner.Next if lt.leaves[treeWinner] == nil { lt.leaves[treeWinner] = &dummyListNode } treeIdx := (treeWinner + len(lt.tree)) / 2 for treeIdx != 0 { treeLoser := lt.tree[treeIdx] if lt.leaves[treeLoser].Val < lt.leaves[treeWinner].Val { treeLoser, treeWinner = treeWinner, treeLoser } lt.tree[treeIdx] = treeLoser treeIdx /= 2 } lt.tree[0] = treeWinner return winner } func mergeKLists(lists []*ListNode) *ListNode { dummy := new(ListNode) pre := dummy lt := New(lists) for { node := lt.Pop() if node == &dummyListNode { break } pre.Next = node pre = node } return dummy.Next } ```
作者回复: 厉害呀! 可以给我的仓库 github.com/wfnuser/Algorithms 提个 pr 吗~ 可以加我V: constant_variation 交个朋友哦
2022-04-23  大土豆如果内存32G,其实 1TB的数据,是可以全部加载到内存的。malloc并没有实际分配内存,分配的都是虚拟内存,64位的虚拟内存远大于 1T,内存还可以和磁盘swap。
大土豆如果内存32G,其实 1TB的数据,是可以全部加载到内存的。malloc并没有实际分配内存,分配的都是虚拟内存,64位的虚拟内存远大于 1T,内存还可以和磁盘swap。作者回复: 哈哈哈 说的好像很有道理~ 不过那样直接排估计缺页中断次数会很多吧
2022-01-29 Try harder听这个课要具备怎样的基础啊,越来越听不懂了。感觉自己不适合做这一行。哭了哭了。
Try harder听这个课要具备怎样的基础啊,越来越听不懂了。感觉自己不适合做这一行。哭了哭了。作者回复: 不用担心哦 这个课程需要一定的计算机基础和算法基础,在学习具体章节的时候可以搜索相关资料进行补充学习。 也可以+v: constant_variation 进专栏群里讨论~
2022-01-01 友get了新知识
友get了新知识作者回复: 加油加油;这个面试常考题,学过之后一定要拿下~
2021-12-28 拓山1、归并排序里,应该说明是在每个小文件做归并比较时,不是全部加入内存比较,而是文件首数据比较,然后生成到新文件里。 2、那个败者树和胜者树看起来不就是小顶堆、大顶堆的排序过程吗?但是这个败者排序中的图例写的并不对,你加入的节点8到底是winer还是loser啊。8是怎么和7比较变为loser8的啊。写的莫名其妙2023-08-09归属地:浙江
拓山1、归并排序里,应该说明是在每个小文件做归并比较时,不是全部加入内存比较,而是文件首数据比较,然后生成到新文件里。 2、那个败者树和胜者树看起来不就是小顶堆、大顶堆的排序过程吗?但是这个败者排序中的图例写的并不对,你加入的节点8到底是winer还是loser啊。8是怎么和7比较变为loser8的啊。写的莫名其妙2023-08-09归属地:浙江 功夫熊猫其实要看吧,64位操作系统的虚拟内存是128TB,完全是可以直接读进来的。当然可能需要触发很多次的请求调页和页面置换。32位机的虚拟内存是3GB。好像没法直接读的2022-08-03归属地:江苏
功夫熊猫其实要看吧,64位操作系统的虚拟内存是128TB,完全是可以直接读进来的。当然可能需要触发很多次的请求调页和页面置换。32位机的虚拟内存是3GB。好像没法直接读的2022-08-03归属地:江苏 al-byteget了2021-12-29
al-byteget了2021-12-29

