

20 | 模型部署:怎么发布训练好的机器学习模型?

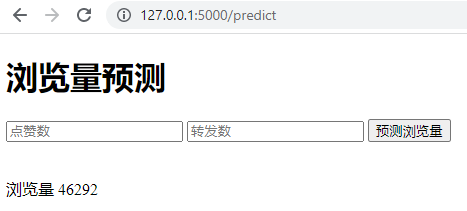
整个项目需要构建哪些模块?
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

本文详细介绍了如何将训练好的机器学习模型部署到生产系统中发挥作用。作者首先介绍了机器学习模型的部署需求和可能的重写模型的方式,然后详细讲解了通过Tensorflow、PyTorch、Sklearn等机器学习框架提供的工具,将数据科学家调试成功的机器学习模型直接发布为Web服务或部署到移动设备的方法。接着,作者通过一个简单的示例,展示了如何将机器学习模型部署为基于Web的应用程序。在示例中,作者介绍了需要构建的模块,包括机器学习模型、用Flask开发的Web应用和HTML页面模板,并解释了它们之间的协作流程。此外,作者还提供了项目的目录结构和HTML页面模板的创建过程。整体而言,本文通过实例详细介绍了机器学习模型部署的流程和相关技术细节,对读者了解模型部署提供了有益的指导和参考。文章内容涵盖了机器学习模型的创建、序列化和反序列化,以及Web应用的开发和模型调用过程,为读者提供了全面的技术指导。
《零基础实战机器学习》,新⼈⾸单¥59

全部留言(2)
- 最新
- 精选
 明远佳哥你好,请问模型部署后,需要如何持续迭代?模型本身能够持续自学习更新吗?还是要每天定时用全量或者增量数据重新训练? 另外,考虑到像搜索引擎这样的,如果基于存量数据训练出了一个分词器,随着新的网络用语出现,分词器就需要再度训练更新。那么庞大的历史数据都需要重新训练一次吗?
明远佳哥你好,请问模型部署后,需要如何持续迭代?模型本身能够持续自学习更新吗?还是要每天定时用全量或者增量数据重新训练? 另外,考虑到像搜索引擎这样的,如果基于存量数据训练出了一个分词器,随着新的网络用语出现,分词器就需要再度训练更新。那么庞大的历史数据都需要重新训练一次吗?作者回复: 是的,模型的持续迭代和更新是机器学习工程中的一个重要主题。正如其它同学提到的,可以进行持续学习与在线学习: 在线学习:模型可以在新数据上进行增量训练,而不是重新使用全量数据。这种方法适用于数据流模型或数据持续增长的情境。 批量更新:定期(例如每天、每周或每月)用最近的数据(或增量数据)重新训练模型。 模型验证与监控: 部署后,持续监控模型的性能指标。如果性能下降到某个阈值以下,则触发模型的重新训练或调整。 使用A/B测试策略在实际环境中对比新模型和旧模型的性能。 数据的滑动窗口策略:对于一些模型,你不需要使用全部的历史数据,而是只用最近的数据。例如,你可以使用过去三个月的数据而不是使用过去三年的数据。 转移学习与增量学习: 转移学习:使用预训练模型作为起点,并在特定任务的新数据上进行微调。 增量学习:只使用新数据对模型进行更新。 考虑存储与计算成本:全量数据的重新训练可能需要大量的存储和计算资源。在实际部署中,可能需要权衡重新训练的好处和成本。 对于你提到的搜索引擎分词器的情况:当新的网络用语出现时,确实需要更新分词器以提高其性能。但这并不意味着每次都需要使用全部的历史数据来重新训练。可以采用增量训练、在线学习或者使用近期的数据进行滑动窗口训练。 值得注意的是,一些老的数据可能在某些情境下变得不太相关。例如,十年前的网络用语可能与现在的环境有很大的不同。 总体而言,持续的模型迭代和更新策略取决于具体的应用场景、数据属性以及业务需求。适当的策略可以确保模型在面对新的数据时仍然保持良好的性能,同时又能控制计算和存储的成本。
2022-03-0423 高绥凯自己运行app.py函数的时候,经常会出现报错,不知道是哪里错误了? runfile('D:/PycharmProjects/FirstWeb/app.py', wdir='D:/PycharmProjects/FirstWeb') Traceback (most recent call last): File "<ipython-input-33-aedc2d900ec7>", line 1, in <module> runfile('D:/PycharmProjects/FirstWeb/app.py', wdir='D:/PycharmProjects/FirstWeb') File "D:\Anaconda\lib\site-packages\spyder\utils\site\sitecustomize.py", line 705, in runfile execfile(filename, namespace) File "D:\Anaconda\lib\site-packages\spyder\utils\site\sitecustomize.py", line 102, in execfile exec(compile(f.read(), filename, 'exec'), namespace) File "D:/PycharmProjects/FirstWeb/app.py", line 34, in <module> app.run(debug=True) File "D:\Anaconda\lib\site-packages\flask\app.py", line 938, in run cli.show_server_banner(self.env, self.debug, self.name, False) File "D:\Anaconda\lib\site-packages\flask\cli.py", line 629, in show_server_banner click.echo(message) File "D:\Anaconda\lib\site-packages\click\utils.py", line 259, in echo file.write(message) UnsupportedOperation: not writable
高绥凯自己运行app.py函数的时候,经常会出现报错,不知道是哪里错误了? runfile('D:/PycharmProjects/FirstWeb/app.py', wdir='D:/PycharmProjects/FirstWeb') Traceback (most recent call last): File "<ipython-input-33-aedc2d900ec7>", line 1, in <module> runfile('D:/PycharmProjects/FirstWeb/app.py', wdir='D:/PycharmProjects/FirstWeb') File "D:\Anaconda\lib\site-packages\spyder\utils\site\sitecustomize.py", line 705, in runfile execfile(filename, namespace) File "D:\Anaconda\lib\site-packages\spyder\utils\site\sitecustomize.py", line 102, in execfile exec(compile(f.read(), filename, 'exec'), namespace) File "D:/PycharmProjects/FirstWeb/app.py", line 34, in <module> app.run(debug=True) File "D:\Anaconda\lib\site-packages\flask\app.py", line 938, in run cli.show_server_banner(self.env, self.debug, self.name, False) File "D:\Anaconda\lib\site-packages\flask\cli.py", line 629, in show_server_banner click.echo(message) File "D:\Anaconda\lib\site-packages\click\utils.py", line 259, in echo file.write(message) UnsupportedOperation: not writable作者回复: UnsupportedOperation: not writable,通常是在写入只读文件的时候报错。看一看是否对所有文件有写权限,是不是有一些文件是只读文件。这只是猜测,我没有遇到过同样错误。 我们看看其它同学是否遇到了类似的问题呢?
2021-10-131