

05 | 数据探索:怎样从数据中找到用户的RFM值?

定义问题
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

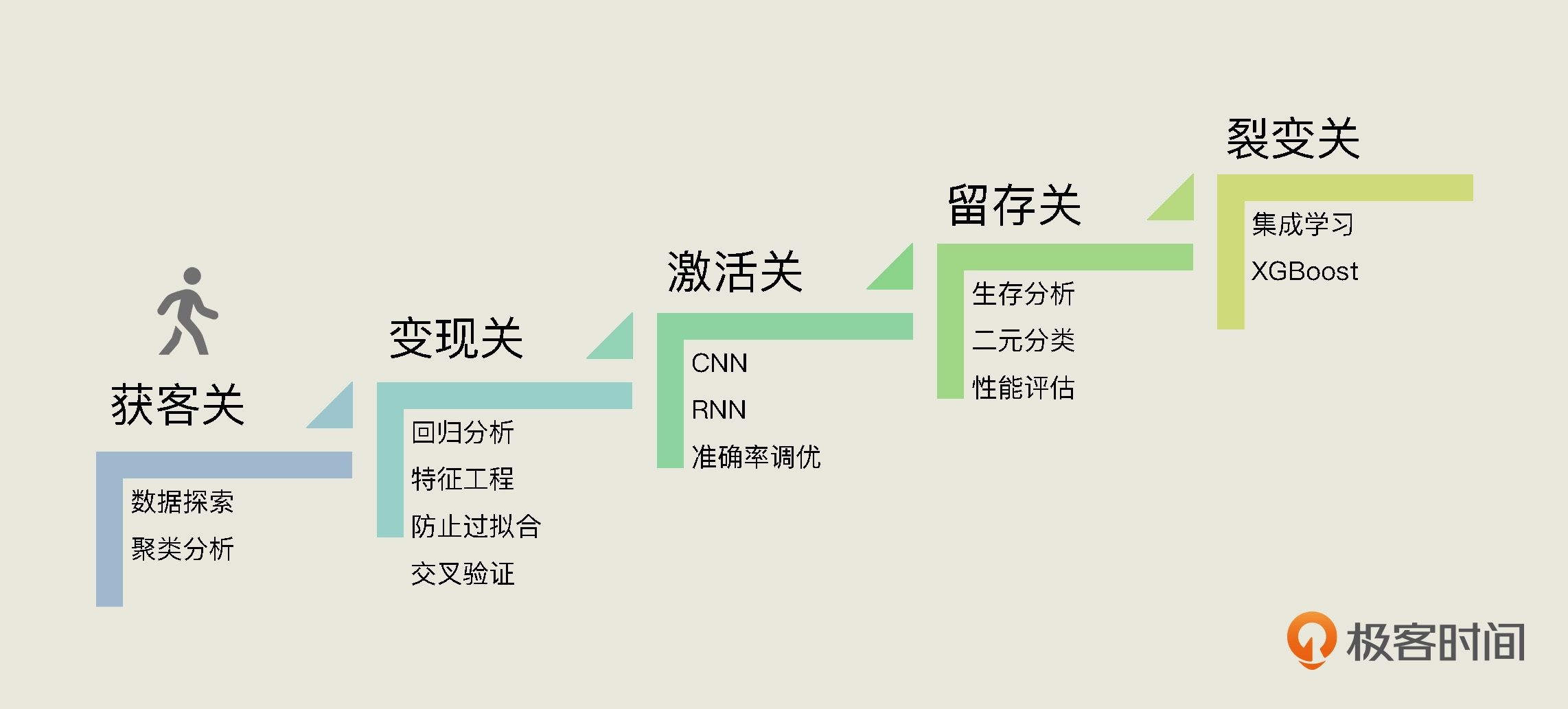
本文介绍了如何从数据中找到用户的RFM值。作者首先介绍了在电商场景下的获客关,即为用户分组画像的重要性。然后详细解释了RFM(Recency、Frequency、Monetary)值的含义和计算方法。接着,作者通过Python的Pandas包对数据进行了预处理和可视化,包括数据读取、数据可视化和数据清洗。最后,作者提出了下一步的目标是解决第一阶段的问题,即求出RFM值。整篇文章结构清晰,内容详实,适合数据分析和机器学习领域的读者阅读。 文章通过介绍RFM模型的重要性和计算方法,以及使用Python的Pandas包对数据进行处理和可视化,为读者提供了在数据分析和机器学习领域的实际操作指南。读者可以从中学习如何从消费历史数据中求出每位用户的R、F、M的值,为用户分组画像提供了实际操作的参考。同时,文章还强调了对RFM分析的理解和应用,以及这些指标可以应用于哪些业务场景,为读者提供了更深入的思考和应用方向。
《零基础实战机器学习》,新⼈⾸单¥59

全部留言(20)
- 最新
- 精选
 GAC·DU上班偷偷摸鱼,把老师分享的课程由粗到细品味了三遍,老师不仅技术高超,运营也这么牛,真是望尘莫及,在没订阅课程之前,我一点运营的知识都没有,看完今天的课程感觉自己又可以了。聊下老师的思考题,我想起当年的瑞幸和滴滴就这么搞的,通过下载APP注册,发送大量的消费券,获取很多的用户。然后经过时间的沉淀,利用RFM技术对用户进行分组,对于用户粘性较高的,进行精细化推荐。对于用户粘性较低的,发送消费券,进行召回用户。对于用户关系管理,可以把R理解为最近一次见面的时间,F理解为多长时间见一次面,M理解为见面聊天的深度,如果只是say hi, 那M的值很低,如果是畅谈人生,M值就会很高。 群里老师说把解决google colab中文乱码的方法分享出来,我说一下大概的思路,然后我会在最后根据本次课程的代码分享测试地址(需要科学上网访问)。 首先是下载你喜欢的中文字体,然后通过FontProperties来指定你下载的字体和展示大小,最后在需要展示中文的地方进行调用。 https://colab.research.google.com/drive/1EuXud71LiM6QsNIA9hsCeOlMiyrB6zLV?usp=sharing
GAC·DU上班偷偷摸鱼,把老师分享的课程由粗到细品味了三遍,老师不仅技术高超,运营也这么牛,真是望尘莫及,在没订阅课程之前,我一点运营的知识都没有,看完今天的课程感觉自己又可以了。聊下老师的思考题,我想起当年的瑞幸和滴滴就这么搞的,通过下载APP注册,发送大量的消费券,获取很多的用户。然后经过时间的沉淀,利用RFM技术对用户进行分组,对于用户粘性较高的,进行精细化推荐。对于用户粘性较低的,发送消费券,进行召回用户。对于用户关系管理,可以把R理解为最近一次见面的时间,F理解为多长时间见一次面,M理解为见面聊天的深度,如果只是say hi, 那M的值很低,如果是畅谈人生,M值就会很高。 群里老师说把解决google colab中文乱码的方法分享出来,我说一下大概的思路,然后我会在最后根据本次课程的代码分享测试地址(需要科学上网访问)。 首先是下载你喜欢的中文字体,然后通过FontProperties来指定你下载的字体和展示大小,最后在需要展示中文的地方进行调用。 https://colab.research.google.com/drive/1EuXud71LiM6QsNIA9hsCeOlMiyrB6zLV?usp=sharing作者回复: 十分感谢你的分享和肯定。也非常非常欣慰你能够在学习中得到收获,感受到进步,同时得到乐趣。我觉得这就是学习的上佳状态。学而时思之,不亦乐乎。 也谢谢你分享展示中文字体的经验!有需要的同学可以参考一下 😄
2021-09-08214 茜茜我觉得RFM适用于高频交易的场景,如零售,不适用于低频交易场景,如赛事演出票务。通过RFM将可以用户分为高中低等价值用户,在需要对某些产品进行营销推广时,可以将高价值用户定为主要营销群体,从而获得更高的订单转化率。但在计算RFM时,可能会面临以下问题:1.用户id与用户并不是一一对应或用户id不统一:如用户有多个账号,或者是多人使用该用户的id发生购买行为,或者部分消费记录未记入该用户,通过的RFM值无法真实反应用户的消费情况。2.关于F值:对于耐用性高的商品,可能一年就买一次,这时可以去掉F值里的时间限制,用该用户累计购买值代替。最后我的感悟是:模型只是基础,不能直接套用,需要结合相应业务场景对模型进行不同程度的修正,来满足业务运营的目标。
茜茜我觉得RFM适用于高频交易的场景,如零售,不适用于低频交易场景,如赛事演出票务。通过RFM将可以用户分为高中低等价值用户,在需要对某些产品进行营销推广时,可以将高价值用户定为主要营销群体,从而获得更高的订单转化率。但在计算RFM时,可能会面临以下问题:1.用户id与用户并不是一一对应或用户id不统一:如用户有多个账号,或者是多人使用该用户的id发生购买行为,或者部分消费记录未记入该用户,通过的RFM值无法真实反应用户的消费情况。2.关于F值:对于耐用性高的商品,可能一年就买一次,这时可以去掉F值里的时间限制,用该用户累计购买值代替。最后我的感悟是:模型只是基础,不能直接套用,需要结合相应业务场景对模型进行不同程度的修正,来满足业务运营的目标。作者回复: 对的,具体问题具体分析,活用数据。
2021-09-08211 海林Lin课程很有收获,有个问题请教老师,为什么说RFM分析能够应用在获客环节呢,个人理解这个时候往往没有用户的行为数据
海林Lin课程很有收获,有个问题请教老师,为什么说RFM分析能够应用在获客环节呢,个人理解这个时候往往没有用户的行为数据作者回复: 嗯,挺好的问题。其实,从AARRR海盗模型的角度来说,获客、激活、留存、变现、增长循环,这5个环节是一个有机的整体,其实并没有一个明显的分割线。很多工具都可以重复使用在各个环节中。现在有一种说法,就是从AARRR到RARRA的模型变化,本质是从野蛮获取用户到精细化运营用户的视野转变。那么,因为现在大多数App获客阶段已经结束了,已经拥有了海量用户。那么,为这些用户画像,精细化运营就更重要。 回到你的问题:为什么RFM分析能够应用在获客环节?从机器学习的角度来讲,如果我能够利用一批老客户的特征(不一定是消费行为特征,也许是人口统计学特征),确定各个客户的价值。那么,我就可以用这个模型做指导,判断出新的具有类似特点的新客户价值有多大。对吧。所以这个工具可以应用在获客环节。
2021-09-0927- Geek_80f43d近度不应该是datetime.now()和最近一次的消费时间差值吗
作者回复: 同学说的对,在实操中应该用datetime.now()。不过我这个是历史数据集,如果采用datetime.now()的话,新进度就越来越遥远了。因此只能选择数据集形成时最新的那一天做示例。
2021-11-166 - yk佳哥好,有个问题,现在例子的数据集都比较小,如果是上亿的数据,也是这么处理吗?全加载到内存会不会很大。
作者回复: 正如其它同学指出的,大数据有大数据的跑法。如Hadoop和Spark允许你在多台机器上分布式地处理大数据。例如,使用Hadoop的MapReduce可以将大数据处理任务分割成多个小任务,并在集群的各个节点上并行处理。
2022-02-1424  !null对于实战课,手不能懒,得敲一下熟练熟练。
!null对于实战课,手不能懒,得敲一下熟练熟练。作者回复: 对,从我自己学习的过程中我也有这个体会。只有动手,才能够发现更多的奥秘。
2021-09-082
 小杰比如客服,针对不同的用户,推送不同的内容,针对R最新消费的时间越短的用户,可以推送更多的新品;针对F消费频率高的用户:可以推送更多的优惠;针对M消费金额高的用户:可以推送更高质量的商品。最后推荐搭大家走一遍代码流程,具体细节可以不用关注,老师说了,代码是很简单的,要知道如何分析,处理,提取数据,这个才是重点
小杰比如客服,针对不同的用户,推送不同的内容,针对R最新消费的时间越短的用户,可以推送更多的新品;针对F消费频率高的用户:可以推送更多的优惠;针对M消费金额高的用户:可以推送更高质量的商品。最后推荐搭大家走一遍代码流程,具体细节可以不用关注,老师说了,代码是很简单的,要知道如何分析,处理,提取数据,这个才是重点作者回复: 对的
2023-02-12归属地:浙江1 在路上佳哥好,看到github上更新了这节课的最新代码,非常开心,这对于我这种初次接触Jupyter和Python的学员来说太重要了,调试非常方便。 RFM 模型是我今天学到的新知识,F代表行为的频率,M代表行为的程度,如果行为是消费,M就是消费金额,如果行为是充值,M就是充值金额,F和M是行为的两个特征,就像我们用振频和振幅来描述振动的特征。R代表行为最近发生的时间,RFM从不同维度描述了一个行为,当然具体的行为可能还能找到特殊的特征。 把行为量化成数值,就可以根据数据聚类,大部分行为都会呈现28分布,就像80%的性能问题是20%的代码引起的,而真正的原因往往出乎你的预料,所以通过聚类可以让我们认识到事先想不到的问题。
在路上佳哥好,看到github上更新了这节课的最新代码,非常开心,这对于我这种初次接触Jupyter和Python的学员来说太重要了,调试非常方便。 RFM 模型是我今天学到的新知识,F代表行为的频率,M代表行为的程度,如果行为是消费,M就是消费金额,如果行为是充值,M就是充值金额,F和M是行为的两个特征,就像我们用振频和振幅来描述振动的特征。R代表行为最近发生的时间,RFM从不同维度描述了一个行为,当然具体的行为可能还能找到特殊的特征。 把行为量化成数值,就可以根据数据聚类,大部分行为都会呈现28分布,就像80%的性能问题是20%的代码引起的,而真正的原因往往出乎你的预料,所以通过聚类可以让我们认识到事先想不到的问题。作者回复: 深为你认真学习的精神而感动!而且,你在学习实战的同时都有很多思考,难能可贵。 我们的数据集,和RFM这些维度,只是用抽象的、大家可以理解的数据启发一个思考,当你吧数据分析、可视化、机器学习的思路应用到公司的具体业务数据中,你能够发现数据能带来很多原来看不到的新启发和新灵感。这些东西只有我们在工作、学习的个人实践中去发现。 也欢迎大家多多分享自己的实践心得。
2021-09-0821 honmio哪位可以共享一下测试数据呢? github上的文件已经无法下载了,先行谢过
honmio哪位可以共享一下测试数据呢? github上的文件已经无法下载了,先行谢过作者回复: 同学你加群后问题解决了对吧。是网络连接问题对吧。
2024-01-12归属地:北京 静静呀一千多行负数,有没有可能是退货呢?属于正常数据
静静呀一千多行负数,有没有可能是退货呢?属于正常数据作者回复: 这样理解也行啊。反正就是清洗数据,知道自己在做什么就行。
2023-11-01归属地:上海