

03|实战5步(上):怎么定义问题和预处理数据?

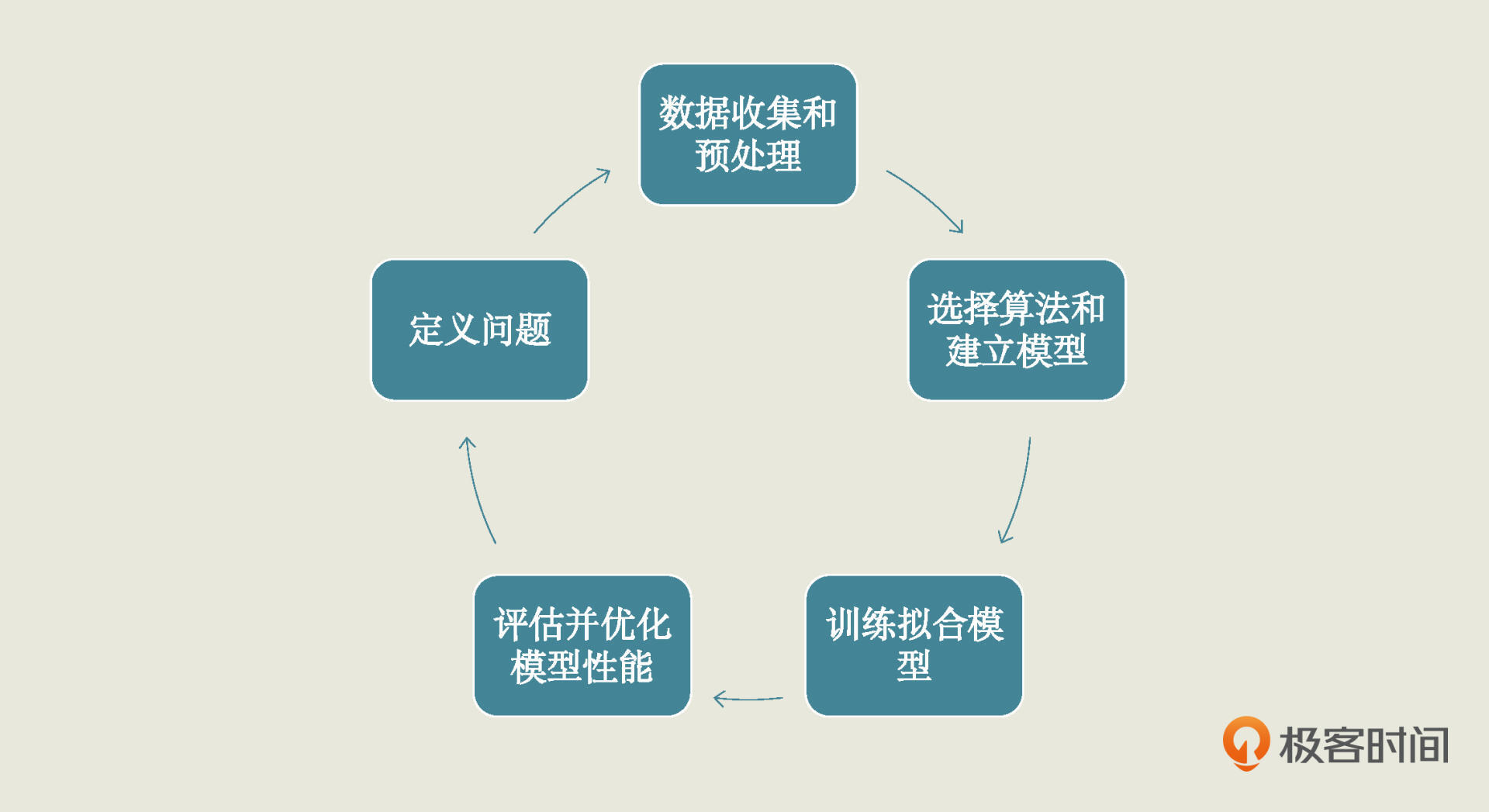
第 1 步 定义问题
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

本文深入介绍了机器学习项目实施的关键步骤,着重强调了定义问题和数据预处理两个阶段的重要性。作者以微信公众号推广文案的运营效率分析为例,详细阐述了业务场景的剖析、目标设定以及机器学习类型的明确。在数据预处理阶段,作者强调了数据集中特征和标签之间的相关性,以及数据清洗的重要性。此外,文章还介绍了数据可视化的重要性,以及如何利用Python的Pandas和Matplotlib等工具进行数据可视化和数据清洗。总的来说,本文为读者提供了清晰的项目实施步骤和实例,帮助读者更好地理解机器学习项目的实际操作流程。文章还涉及特征工程、构建特征集和标签集、以及拆分训练集、验证集和测试集等内容,为读者提供了全面的实践指导。
《零基础实战机器学习》,新⼈⾸单¥59

全部留言(29)
- 最新
- 精选
 在路上置顶黄老师好,面对空缺的数据,可以采用默认值、均值、中位值等方式填充,有条件的话,可以和业务方沟通,要求补全空缺数据。
在路上置顶黄老师好,面对空缺的数据,可以采用默认值、均值、中位值等方式填充,有条件的话,可以和业务方沟通,要求补全空缺数据。作者回复: 谢谢,这是特别好的经验分享。值得置顶!
2021-09-0321 年轻置顶真想一爱看完,太难等了
年轻置顶真想一爱看完,太难等了作者回复: 嗯,谢谢支持。我们这边也多努力一下。
2021-09-033 谦黄老师,请问如果工作人员录入数据的时候空值并没有留空,而是用“\”,“-”,“无”等字符来标注的话,有什么好的处理方法呢?我一般是用excel进行筛选,查看异常值,然后排序之后吧异常值整行删掉,处理干净之后再用pandas导入。想看看有没有一些更智能的方法。谢谢🙏
谦黄老师,请问如果工作人员录入数据的时候空值并没有留空,而是用“\”,“-”,“无”等字符来标注的话,有什么好的处理方法呢?我一般是用excel进行筛选,查看异常值,然后排序之后吧异常值整行删掉,处理干净之后再用pandas导入。想看看有没有一些更智能的方法。谢谢🙏作者回复: 有方法。试试这个: 例子: import pandas as pd data = [[100] ,['/'], ['Zero'], [99]] columns = ['成绩'] df = pd.DataFrame(data=data, columns=columns) df 原始数据输出: 成绩 0 100 1 / 2 Zero 3 99 转换语句 df['新成绩'] = pd.to_numeric(df.成绩.astype(str).str.replace(',',''), errors='coerce').fillna(0).astype(int) df 新字段的输出 成绩 新成绩 0 100 100 1 / 0 2 Zero 0 3 99 99 是不是比Excel快很多呀?
2021-09-03423 shatu在开始前花了一些时间解决中文乱码的问题: 1.编码不为utf-8且文件路径有中文,产生的乱码 用记事本另存为utf-8编码,加入engine='python'参数 例: df_ads = pd.read_csv('易速鲜花微信软文.csv',engine='python',encoding='utf-8') 2.matplotlib作图标签产生乱码的 例: plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签 plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
shatu在开始前花了一些时间解决中文乱码的问题: 1.编码不为utf-8且文件路径有中文,产生的乱码 用记事本另存为utf-8编码,加入engine='python'参数 例: df_ads = pd.read_csv('易速鲜花微信软文.csv',engine='python',encoding='utf-8') 2.matplotlib作图标签产生乱码的 例: plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签 plt.rcParams['axes.unicode_minus']=False #用来正常显示负号作者回复: 谢谢分享!
2021-09-2339 自娱自乐★mac中图表横纵坐标乱码解决方法 plt.rcParams['font.sans-serif'] = ['Arial Unicode MS']
自娱自乐★mac中图表横纵坐标乱码解决方法 plt.rcParams['font.sans-serif'] = ['Arial Unicode MS']作者回复: 💍👑
2022-04-307 茜茜谢谢黄老师的讲解。这是我的回答,我还买了老师的书《零基础学机器学习》,昨天浏览了一遍,希望把这本书和专栏的知识都学会。 #思考题1 import matplotlib.pyplot as plt import seaborn as sns from pylab import mpl plt.rcParams['font.sans-serif'] = ['KaiTi'] plt.figure(figsize = (20,8), dpi = 100) fig, axes = plt.subplots(2, 2, figsize = (20,8), dpi = 100) #散点图 axes[0,0].plot(df_ads['点赞数'],df_ads['浏览量'],'r.', label='点赞数-浏览量') axes[0,1].plot(df_ads['转发数'],df_ads['浏览量'],'b.', label='转发数-浏览量') axes[1,0].plot(df_ads['热度指数'],df_ads['浏览量'],'g.', label='热度指数-浏览量') axes[1,1].plot(df_ads['文章评级'],df_ads['浏览量'],'y.', label='文章评级-浏览量') axes[0,0].set_xlabel('点赞数') axes[0,0].set_ylabel('浏览量') axes[0,1].set_xlabel('转发数') axes[0,1].set_ylabel('浏览量') axes[1,0].set_xlabel('热度指数') axes[1,0].set_ylabel('浏览量') axes[1,1].set_xlabel('文章评级') axes[1,1].set_ylabel('浏览量') plt.legend(loc = 0) axes[0,0].legend(loc = 2) axes[0,1].legend(loc = 2) axes[1,0].legend(loc = 2) axes[1,1].legend(loc = 2) plt.show() #箱线图 plt.figure(figsize = (20,8), dpi = 100) fig, axes = plt.subplots(2, 2, figsize = (20,8), dpi = 100) data1 = df_ads[['浏览量','点赞数']] data2 = df_ads[['浏览量','转发数']] data3 = df_ads[['浏览量','热度指数']] data4 = df_ads[['浏览量','文章评级']] fig1 = sns.boxplot(x = '点赞数', y = '浏览量', data = data1, ax = axes[0,0]) fig1.axis(ymin = 0, ymax = 800000) fig2 = sns.boxplot(x = '转发数', y = '浏览量', data = data2, ax = axes[0,1]) fig2.axis(ymin = 0, ymax = 800000) fig3 = sns.boxplot(x = '热度指数', y = '浏览量', data = data3, ax = axes[1,0]) fig3.axis(ymin = 0, ymax = 800000) fig4 = sns.boxplot(x = '文章评级', y = '浏览量', data = data4, ax = axes[1,1]) fig4.axis(ymin = 0, ymax = 800000) axes[0,0].set_xlabel('点赞数') axes[0,0].set_ylabel('浏览量') axes[0,1].set_xlabel('转发数') axes[0,1].set_ylabel('浏览量') axes[1,0].set_xlabel('热度指数') axes[1,0].set_ylabel('浏览量') axes[1,1].set_xlabel('文章评级') axes[1,1].set_ylabel('浏览量') plt.show() #思考题2 # 用中位数填充 df_ads['转发数'].fillna(df_ads['转发数'].median(), inplace=True) #用众数填充 df_ads['转发数'].fillna(df_ads['转发数'].mode(), inplace=True)
茜茜谢谢黄老师的讲解。这是我的回答,我还买了老师的书《零基础学机器学习》,昨天浏览了一遍,希望把这本书和专栏的知识都学会。 #思考题1 import matplotlib.pyplot as plt import seaborn as sns from pylab import mpl plt.rcParams['font.sans-serif'] = ['KaiTi'] plt.figure(figsize = (20,8), dpi = 100) fig, axes = plt.subplots(2, 2, figsize = (20,8), dpi = 100) #散点图 axes[0,0].plot(df_ads['点赞数'],df_ads['浏览量'],'r.', label='点赞数-浏览量') axes[0,1].plot(df_ads['转发数'],df_ads['浏览量'],'b.', label='转发数-浏览量') axes[1,0].plot(df_ads['热度指数'],df_ads['浏览量'],'g.', label='热度指数-浏览量') axes[1,1].plot(df_ads['文章评级'],df_ads['浏览量'],'y.', label='文章评级-浏览量') axes[0,0].set_xlabel('点赞数') axes[0,0].set_ylabel('浏览量') axes[0,1].set_xlabel('转发数') axes[0,1].set_ylabel('浏览量') axes[1,0].set_xlabel('热度指数') axes[1,0].set_ylabel('浏览量') axes[1,1].set_xlabel('文章评级') axes[1,1].set_ylabel('浏览量') plt.legend(loc = 0) axes[0,0].legend(loc = 2) axes[0,1].legend(loc = 2) axes[1,0].legend(loc = 2) axes[1,1].legend(loc = 2) plt.show() #箱线图 plt.figure(figsize = (20,8), dpi = 100) fig, axes = plt.subplots(2, 2, figsize = (20,8), dpi = 100) data1 = df_ads[['浏览量','点赞数']] data2 = df_ads[['浏览量','转发数']] data3 = df_ads[['浏览量','热度指数']] data4 = df_ads[['浏览量','文章评级']] fig1 = sns.boxplot(x = '点赞数', y = '浏览量', data = data1, ax = axes[0,0]) fig1.axis(ymin = 0, ymax = 800000) fig2 = sns.boxplot(x = '转发数', y = '浏览量', data = data2, ax = axes[0,1]) fig2.axis(ymin = 0, ymax = 800000) fig3 = sns.boxplot(x = '热度指数', y = '浏览量', data = data3, ax = axes[1,0]) fig3.axis(ymin = 0, ymax = 800000) fig4 = sns.boxplot(x = '文章评级', y = '浏览量', data = data4, ax = axes[1,1]) fig4.axis(ymin = 0, ymax = 800000) axes[0,0].set_xlabel('点赞数') axes[0,0].set_ylabel('浏览量') axes[0,1].set_xlabel('转发数') axes[0,1].set_ylabel('浏览量') axes[1,0].set_xlabel('热度指数') axes[1,0].set_ylabel('浏览量') axes[1,1].set_xlabel('文章评级') axes[1,1].set_ylabel('浏览量') plt.show() #思考题2 # 用中位数填充 df_ads['转发数'].fillna(df_ads['转发数'].median(), inplace=True) #用众数填充 df_ads['转发数'].fillna(df_ads['转发数'].mode(), inplace=True)作者回复: 感谢支持,一起加油😁!作业完成的非常认真,我看到你还给出了median()和众数的方法mode()。很好。
2021-09-037 安迪密恩想请教老师一个问题,箱线图为什么会有离群点?最大值和最小值区间不是应该包含所有的点了吗?
安迪密恩想请教老师一个问题,箱线图为什么会有离群点?最大值和最小值区间不是应该包含所有的点了吗?作者回复: 箱线图是一种基于五位数摘要(“最小”,第一四分位数(Q1),中位数,第三四分位数(Q3)和“最大”)显示数据分布的标准化方法。 中位数(Q2 / 50th百分位数):数据集的中间值; 第一个四分位数(Q1 / 25百分位数):最小数(不是“最小值”)和数据集的中位数之间的中间数; 第三四分位数(Q3 / 75th Percentile):数据集的中位数和最大值之间的中间值(不是“最大值”); 四分位间距(IQR):第25至第75个百分点的距离; 晶须(蓝色显示) 离群值(显示为绿色圆圈) “最大”:Q3 + 1.5 * IQR “最低”:Q1 -1.5 * IQR 在箱线图中,最大值和最小值的定义有些特殊。他们并不总是数据中的实际最大值和最小值。箱线图中的最大值是数据中小于或等于Q3+1.5IQR(IQR为四分位距,等于Q3-Q1)的最大值,而最小值是数据中大于或等于Q1-1.5IQR的最小值。所谓的离群点,就是那些超出这个范围的数据点。
2022-07-1823
 dao如果大家遇到这个问题: RuntimeWarning: Glyph missing from current font 尝试了很多方法都无法解决,那请删除 matplotlib cache ,然后重启 jupyter kernel。 --- rm -rf ~/.matplotlib/ jupyter lab --- 确保 matplotlib cache 中有中文字体 --- vi ~/.matplotlib/fontlist-v330.json ---
dao如果大家遇到这个问题: RuntimeWarning: Glyph missing from current font 尝试了很多方法都无法解决,那请删除 matplotlib cache ,然后重启 jupyter kernel。 --- rm -rf ~/.matplotlib/ jupyter lab --- 确保 matplotlib cache 中有中文字体 --- vi ~/.matplotlib/fontlist-v330.json ---作者回复: 谢谢分享!!🎿
2021-10-0843 Allen感觉data = pd.concat([df_ads['浏览量'], df_ads['热度指数']], axis=1),这句可以用df_ads[['浏览量', '热度指数']]替代,看上去更简单一些
Allen感觉data = pd.concat([df_ads['浏览量'], df_ads['热度指数']], axis=1),这句可以用df_ads[['浏览量', '热度指数']]替代,看上去更简单一些作者回复: 对,对。 fig = sns.boxplot(x='热度指数', y="浏览量", data=df_ads[['浏览量', '热度指数']]) 这样就完全可以了。
2021-09-262 GAC·DU想到两个补值方法,我试了感觉都不是很好。第一个是取临近值,这种方法误差很大。第二个是利用对比标签值,反推特征值,这种方法适合小数据量,如果是大数据量很消耗机器性能。还请老师给出个完美的方案。
GAC·DU想到两个补值方法,我试了感觉都不是很好。第一个是取临近值,这种方法误差很大。第二个是利用对比标签值,反推特征值,这种方法适合小数据量,如果是大数据量很消耗机器性能。还请老师给出个完美的方案。作者回复: 嗯,非常好。大家都有自己的思考,我也有一个可能的想法,暂时先不分享给大家,让大家继续自由讨论。我过几天在分享这个想法。 补充一下,我的这个想法是对于转发数的空值,可以把同一行的“点赞数”拷贝到“转发数”中。因为这两个值接近。
2021-09-0322