

06 | 聚类分析:如何用RFM给电商用户做价值分组画像?

怎么给用户分组比较合适?
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

本文介绍了如何利用RFM模型和K-Means算法对电商用户进行分组画像和聚类分析。通过讨论手肘法确定聚类数量的重要性,并通过损失值曲线找出最佳K值,详细介绍了利用Python代码实现手肘法确定R、F、M值的簇的个数。文章还讲解了如何创建和训练K-Means聚类模型,包括设定簇的个数和使用fit方法进行模型训练。通过实际代码演示,帮助读者理解聚类分析的技术特点,为电商用户分组画像提供了实用的方法。文章还讨论了聚类结果的排序和用户分层的确定,最终为读者提供了完整的用户分层方法。整体内容通俗易懂,适合初学者快速了解聚类分析的基本原理和应用。文章还提出了思考题,引导读者深入思考聚类算法的应用场景和用户分组画像的其他方法。
《零基础实战机器学习》,新⼈⾸单¥59

全部留言(14)
- 最新
- 精选

 Jove1、绘制三维图 df_user['三维价值'] = KMeans(n_clusters=3).fit(df_user[['R值', 'F值', 'M值']]).predict(df_user[['R值', 'F值', 'M值']]) ax = plt.subplot(111, projection='3d') ax.scatter(df_user.query("三维价值 == 0")['F值'], df_user.query("三维价值 == 0")['R值'], df_user.query("三维价值 == 0")['M值'], c='y') ax.scatter(df_user.query("三维价值 == 1")['F值'], df_user.query("三维价值 == 1")['R值'], df_user.query("三维价值 == 1")['M值'], c='r') ax.scatter(df_user.query("三维价值 == 2")['F值'], df_user.query("三维价值 == 2")['R值'], df_user.query("三维价值 == 2")['M值'], c='g') ax.set_zlabel('F') # 坐标轴 ax.set_ylabel('R') ax.set_xlabel('M') plt.show() 2、我从事的行业的是信贷,也可以从用户征信情况、借贷金额、违约次数等来聚合为用户划分评级
Jove1、绘制三维图 df_user['三维价值'] = KMeans(n_clusters=3).fit(df_user[['R值', 'F值', 'M值']]).predict(df_user[['R值', 'F值', 'M值']]) ax = plt.subplot(111, projection='3d') ax.scatter(df_user.query("三维价值 == 0")['F值'], df_user.query("三维价值 == 0")['R值'], df_user.query("三维价值 == 0")['M值'], c='y') ax.scatter(df_user.query("三维价值 == 1")['F值'], df_user.query("三维价值 == 1")['R值'], df_user.query("三维价值 == 1")['M值'], c='r') ax.scatter(df_user.query("三维价值 == 2")['F值'], df_user.query("三维价值 == 2")['R值'], df_user.query("三维价值 == 2")['M值'], c='g') ax.set_zlabel('F') # 坐标轴 ax.set_ylabel('R') ax.set_xlabel('M') plt.show() 2、我从事的行业的是信贷,也可以从用户征信情况、借贷金额、违约次数等来聚合为用户划分评级作者回复: 这......这.....这简直是太棒了。三维RFM图看起来更直观。漂亮。 感谢Jove同学对于信贷场景的分享!
2021-09-14329 吴悦多维数据输入时怎么做 无量纲化好呀
吴悦多维数据输入时怎么做 无量纲化好呀作者回复: 同学们的问题总是会引导我剧透后面的内容。。。 在sklearn中,同学所说的无量纲化英文被称为特征的缩放(Scaler),把大的数值压缩到小的范围,或者改变数值的分布状态等。具体的方法和工具很多,包括标准化,归一化,居中,规范化等等不同的手段(这些手段的名词也容易混淆): 1)StandardScaler工具,标准化缩放,是对数据特征分布的转换,目标是使其符合正态分布(均值为0,方差为1)。对于某些模型,如果数据特征不符合正态分布的话,就影响机器学习效率。 2)MinMaxScaler工具,是把特征的值压缩到给定的最小值和最大值之间,通常在0和1之间,有负值的话就是-1到1,因此也叫归一化。归一化不会改变数据的分布状态。在sklearn中,通过MinMaxScaler进行标准化缩放。某些模型,比如神经网络,就非常喜欢归一化之后的特征数据。 3)RobustScaler工具,基于百分位数的缩放,能消除这个过程消除了数据中的离群值的影响,但转换后的特征值的结果范围比之前的更大,所以RobustScaler之后,通常还结合归一化缩放器一起使用,再把数据压缩一下。 4)Normalizer工具,规范化缩放,则是将样本缩放为具有单位范数的过程,这可能仅适用于某些各个维度都是One-Hot编码的数据集,应用场景较少。 不同数据集适用不同工具。 这些我们以后要讲。
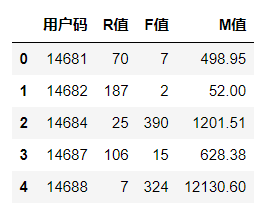
2021-09-1013 在路上佳哥好,今天是教师节,祝你节日快乐。我看了下kmeans的API,fit函数支持多维数组,应该可以把RFM三个维度的值同时传给fit进行拟合,而不是把RFM三个维度的值降维到一个值进行拟合,通过predict函数就可能直接得到聚类后的层级,从predict函数的名称可以得知,它不仅能计算训练集的聚类层级,也能预测新数据的聚类层级。 我从事游戏行业,策划会根据玩家充值金额来定义大中小R,充值区间的定义全凭经验,如果用今天教的k-means方法就非常合适。我最近在学习大数据,想统计HDSF上文件大小的分布情况,也可以用k-means算法。 最后说一下我发现这节课的文本和表格的部分数据有出入。文本:上次购物距今是0天到91天,表格:是94天。文本:0层级的用户平均新近度是295天,表格:是298天。文本:R值最高的用户组(2层级)平均新近度仅有31天,表格:是32天。
在路上佳哥好,今天是教师节,祝你节日快乐。我看了下kmeans的API,fit函数支持多维数组,应该可以把RFM三个维度的值同时传给fit进行拟合,而不是把RFM三个维度的值降维到一个值进行拟合,通过predict函数就可能直接得到聚类后的层级,从predict函数的名称可以得知,它不仅能计算训练集的聚类层级,也能预测新数据的聚类层级。 我从事游戏行业,策划会根据玩家充值金额来定义大中小R,充值区间的定义全凭经验,如果用今天教的k-means方法就非常合适。我最近在学习大数据,想统计HDSF上文件大小的分布情况,也可以用k-means算法。 最后说一下我发现这节课的文本和表格的部分数据有出入。文本:上次购物距今是0天到91天,表格:是94天。文本:0层级的用户平均新近度是295天,表格:是298天。文本:R值最高的用户组(2层级)平均新近度仅有31天,表格:是32天。作者回复: 谢谢精辟的分享,皆是宝贵的经验之谈,对我亦有启发!三人行,必有我师!大家也是我的老师,我这儿也祝愿大家工作生活愉快。 对,文本部分,我这儿需要按照表格中跑出来的值进行调整一下,把二者对应上。谢谢你的细心!!
2021-09-105 吃鱼我把 R、F、M 三个特征同时输入 K-Means 算法,并与文中提到的先分别聚类再求和两种方法进行比较,结果如下: 1) 直接聚类和分别聚类的结果很近似,只有28(共980)个实例分组不同。 2) 直接聚类会面临无法人为定义价值高低的情况,也就是聚类结果无法概念化,这次实验中就存在分组结果的三个指标并非都能按照某种顺序排序的情况。尤其是在特征维度过高时,可能得到无意义的结果。 3)分别聚类再求和的方式有更强的灵活性,更方便人为操作,比如人为赋予权重,人为划定总分的分组区间,从而得到我们想要的结果。 4)第一次实验没有使用归一化,但当我们使用MinMaxScaler规范化之后,结果反而变得很奇怪,三维图像的分簇结果不如不规范化的清晰。猜测可能是因为RFM三个值本身就时不同尺度,强行化为同一尺度并不一定会让结果看起来更合理。另一方面也说明,聚类最好用在相同或相似的尺度特征下,比如图像处理时的RBG颜色分组就很适合使用聚类。
吃鱼我把 R、F、M 三个特征同时输入 K-Means 算法,并与文中提到的先分别聚类再求和两种方法进行比较,结果如下: 1) 直接聚类和分别聚类的结果很近似,只有28(共980)个实例分组不同。 2) 直接聚类会面临无法人为定义价值高低的情况,也就是聚类结果无法概念化,这次实验中就存在分组结果的三个指标并非都能按照某种顺序排序的情况。尤其是在特征维度过高时,可能得到无意义的结果。 3)分别聚类再求和的方式有更强的灵活性,更方便人为操作,比如人为赋予权重,人为划定总分的分组区间,从而得到我们想要的结果。 4)第一次实验没有使用归一化,但当我们使用MinMaxScaler规范化之后,结果反而变得很奇怪,三维图像的分簇结果不如不规范化的清晰。猜测可能是因为RFM三个值本身就时不同尺度,强行化为同一尺度并不一定会让结果看起来更合理。另一方面也说明,聚类最好用在相同或相似的尺度特征下,比如图像处理时的RBG颜色分组就很适合使用聚类。作者回复: 太棒了,感谢同学的实验和详细的过程分享。
2022-12-26归属地:陕西2- Geek_8629f4老师,请问, 当把 R、F、M 三个特征同时输入 K-Means 算法,为用户整体做聚类时, 发现 分为3 组, 但是 每组人数相差很大, A 组 7 人 B 组 60 , C 组913人,如果时这样,这种分组意思不大, 没有好的办法制定marketing 的策略。请问是我们必须要分别分类聚类才能得到更好的效果, 我的聚类方法有什么不对的地方。实际分析中,应该如何操作呢?
作者回复: 当使用K-Means算法进行聚类分析时,如果发现聚类结果中某些组的数量相差很大,可能是由于以下原因: 特征缩放问题:K-Means算法对特征的尺度敏感。如果R、F、M三个特征的取值范围差异很大,那么尺度大的特征会对距离的计算产生更大的影响。解决方法是对特征进行归一化或标准化。 选择K值:可能选择的K值(在这里是3)不是数据的最佳聚类数。可以尝试使用肘部法则(Elbow method)或轮廓系数来确定最佳的K值。 数据的分布:有时,数据的自然分布确实是有很大的类和较小的类。在这种情况下,K-Means可能捕捉到了这种真实的分布。 K-Means的局限性:K-Means聚类假设群集是凸形和同样大小的,这可能不适用于所有数据集。考虑使用其他聚类方法,如DBSCAN或谱聚类。 为了改进聚类结果,可以尝试以下策略: 特征缩放:确保所有输入特征都被正确地归一化或标准化。 尝试不同的K值:不仅仅是3,还可以尝试其他的K值,并使用上述的评估方法(如肘部法则)来确定最佳K值。 考虑其他聚类算法:尝试使用DBSCAN、谱聚类或层次聚类等其他算法。 特征工程:考虑添加或修改特征。例如,你可以尝试R和F的交互项、R、F和M的平均值等。 单独对特征进行聚类:如果觉得有必要,可以单独对R、F、M进行聚类,然后结合结果制定营销策略。但这并不总是最佳策略,因为用户的行为可能是由多个特征共同影响的。 实际分析中,建议先确保数据的预处理(如特征缩放)是正确的,然后尝试不同的K值和聚类算法。并且要不断地验证你的聚类结果,看它们是否在实际的营销活动中是有意义的。
2022-11-17归属地:加拿大1 - Geek_7ba002这节课让我真正理解了什么是聚类
作者回复: 谢谢
2022-03-021 - Geek_7ba002这堂课我真正理解了sklearn
作者回复: 加油
2022-03-021 - Geek_maxwellkmeans = kmeans.fit(df) #拟合模型 这个好像不能重新赋值给kmeans, 不然后面的kmeans.inertia_就没有了
作者回复: 谢谢同学,尽管这样做之后,inertia_应该仍然在那儿。但是更好的代码正如同学指出的,不需要重写赋值。更新如下: for k in K: kmeans = KMeans(n_clusters=k, max_iter=100) # 创建KMeans模型 kmeans.fit(df) # 拟合模型 distance_list.append(kmeans.inertia_) # 获取每个K值的损失
2022-08-28归属地:浙江 - 庞亮“最后,我们还讲到用 K- 均值算法来给 R 值做聚类,这也非常简单,就是创建模型、拟合模型、用模型进行聚类,这些过程加一块也就是几行代码的事儿,你不用有负担。” 这句说了两遍
作者回复: 谢谢同学的细心,我们会修正音频。
2022-06-13  Yaohong请问 order_cluster函数中new_cluster_name = 'new_' + cluster_name #新的聚类名称,这个有什么作用?后面分组中用mean()方法而不用max()方法有什么考量?
Yaohong请问 order_cluster函数中new_cluster_name = 'new_' + cluster_name #新的聚类名称,这个有什么作用?后面分组中用mean()方法而不用max()方法有什么考量?作者回复: 正如同学评论那样,冗余代码可删。通过Mean排序更具区别度。
2022-04-232