

15|二元分类:怎么预测用户是否流失?从逻辑回归到深度学习

定义问题
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

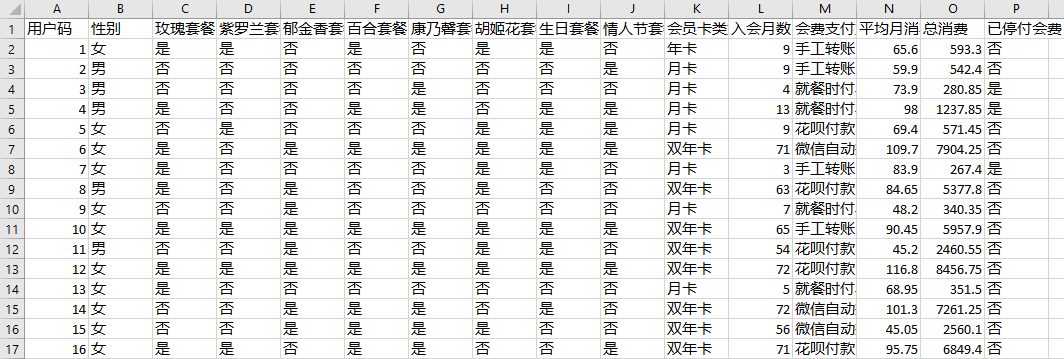
本文介绍了如何利用神经网络模型解决用户流失预测问题。文章首先讨论了需求背景,即运营部门希望建立一个模型,能够预测哪些客户流失风险较高,以便及时触发留客机制。接着,文章介绍了数据预处理的步骤,包括数据读入、清洗、可视化和特征工程等工作。然后,文章讨论了选择神经网络模型的原因,指出神经网络适合解决特征数量多、数据集样本数量庞大的分类问题。文章详细介绍了DNN(密集连接层)神经网络模型的构建过程,包括激活函数的选择、编译神经网络和训练过程。最后,文章提到了神经网络模型的训练结果,并暗示了接下来会介绍神经网络模型的表现。整体来看,本文涵盖了从问题定义到模型建立的全流程,适合读者快速了解如何利用神经网络模型解决用户流失预测问题。文章还提到了模型在测试集上的预测准确率达到了77%,但损失和准确率曲线出现振荡波动,需要进一步探讨原因。文章还提到了归一化后的神经网络模型测试准确率为78%,并留下了思考题,鼓励读者尝试使用其他分类算法解决问题,或调整神经网络结构和参数。整体而言,本文内容丰富,涵盖了数据预处理、模型构建和优化等多个方面,对于想要深入了解神经网络模型解决用户流失预测问题的读者具有一定的参考价值。
《零基础实战机器学习》,新⼈⾸单¥59

全部留言(7)
- 最新
- 精选
 包子在jupyter中运行keras和tensorflow。python意外退出,jupyter显示kernel崩溃。有解法吗?
包子在jupyter中运行keras和tensorflow。python意外退出,jupyter显示kernel崩溃。有解法吗?作者回复: 可能要重装一个环境试试。
2023-11-22归属地:北京- Geek_37299ddnn.add(Dense(units=12, input_dim=17, activation = 'relu')) # 添加输入层 dnn.add(Dense(units=24, activation = 'relu')) # 添加隐层 请问这里的units=12 、input_dim=17、units=24等参数都是依据什么填写的呢
作者回复: 这里是根据经验确定的,属于超参数,可以按照同学的硬件和数据集进行调整。
2023-10-20归属地:上海  Geek_9a0aa0准确率只能到77%这样了么 如何继续提升呢
Geek_9a0aa0准确率只能到77%这样了么 如何继续提升呢作者回复: 这个和数据本身有关。我们的数据集也是我随便制作的,要进一步提升准确率可以考虑在网上找更标准的数据集,比较一下你训练的准确率和这个数据集的SOTA(也就是别人训练出来的最佳水平)。这才科学。
2023-08-15归属地:浙江 蔓延第一段代码里的df_churn是哪儿来的?
蔓延第一段代码里的df_churn是哪儿来的?作者回复: 数据的读入、清洗、可视化和特征工程等工作,我们在上一讲中已经做好了。参考上一讲。
2023-02-05归属地:北京 Null越到后面评论越来越少3
Null越到后面评论越来越少3作者回复: 😆
2022-09-22归属地:北京 她の他老师,有完整的代码吗
她の他老师,有完整的代码吗作者回复: https://github.com/huangjia2019/geektime
2022-08-23归属地:中国香港 Sarai李醍醐灌顶
Sarai李醍醐灌顶作者回复: 谢谢!
2022-04-22