

11|深度学习(上):用CNN带你认识深度学习

问题定义
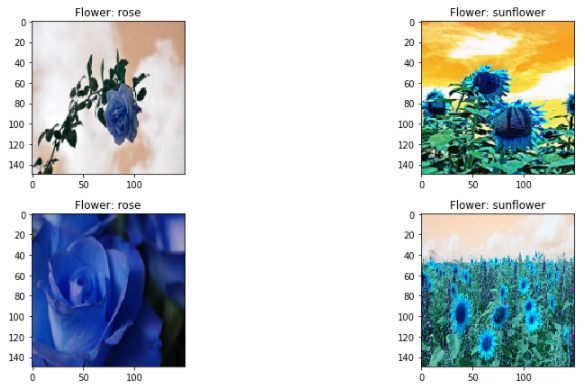
数据收集和预处理
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

本文详细介绍了使用卷积神经网络(CNN)进行深度学习的过程,并以易速鲜花App的历史记录为例进行讲解。作者从数据收集和预处理入手,包括获取花朵图片数据集和使用OpenCV工具箱处理图片数据。通过代码示例演示了构建特征集X和标签集y的过程,并解释了张量数组的格式和特征的维度。文章强调了深度学习在处理非结构化数据方面的优势,以及选择深度学习框架Keras来搭建神经网络的原因。此外,文章还介绍了卷积神经网络的结构和原理,以及使用Keras API搭建卷积神经网络模型的方法。在模型的训练和拟合部分,文章详细讲解了训练过程中的损失和准确率的输出,以及模型性能的评估和分类结果的展示。最后,文章总结了搭建强大的深度学习神经网络并不是难事,强调了卷积神经网络的结构和搭建方法,并留下了一个思考题,鼓励读者尝试改变网络结构并比较性能。整体而言,本文生动地介绍了深度学习的原理和搭建深层神经网络CNN的方法,适合读者快速了解深度学习的基本原理和实际应用,对深度学习神经网络有了更深入的理解。
《零基础实战机器学习》,新⼈⾸单¥59

全部留言(14)
- 最新
- 精选

 qinsiopencv默认像素通道顺序是BGR,而matplotlib默认是RGB,直接画出来颜色就不对
qinsiopencv默认像素通道顺序是BGR,而matplotlib默认是RGB,直接画出来颜色就不对作者回复: 哇,就四这个原因我显示出来的图片里红花都泛着一种神秘蓝光!!(x_x) 谢谢分享~
2021-10-0323 遂行kaggle导入keras的时候报错了,看了下环境预装的是TensorFlow 需要改成:from tensorflow.keras.utils import to_categorical
遂行kaggle导入keras的时候报错了,看了下环境预装的是TensorFlow 需要改成:from tensorflow.keras.utils import to_categorical作者回复: 好的,非常感谢!我这儿马上调整一下!
2021-09-2643 千里马请问老师,神经网络里的参数,比如案例里的输出滤波器的数量64,2D卷积窗口的高度和宽度(2,2),这些参数的选择有什么依据吗?虽说是参数,可以变更,但总不能乱试吧
千里马请问老师,神经网络里的参数,比如案例里的输出滤波器的数量64,2D卷积窗口的高度和宽度(2,2),这些参数的选择有什么依据吗?虽说是参数,可以变更,但总不能乱试吧作者回复: 个主要的考虑因素: 问题的性质:对于不同类型的问题,可能需要使用不同的超参数。例如,对于图像分类问题,经常使用的卷积窗口大小是(3,3)或(5,5),这是因为较小的卷积窗口可以捕捉到图像的局部特征。对于文本分类问题,我们可能需要使用更大的窗口大小,因为在文本中,有意义的特征可能需要考虑更多的上下文信息。 经验:很多超参数的选择都是基于经验的。例如,在很多成功的神经网络结构中,例如ResNet,VGG等,我们可以看到一些常见的超参数选择,如卷积窗口大小为(3,3),池化窗口大小为(2,2),这些都是被验证过的有效的超参数选择,因此在许多新的网络结构中,我们也会采用这些超参数。 计算资源:计算资源也是选择超参数的一个重要因素。一般来说,更大的网络(有更多的层,更多的神经元,更大的滤波器等)可能会有更好的性能,但也需要更多的计算资源(时间和内存)。因此,我们需要在性能和计算资源之间找到一个平衡。 调优:除了上述的因素外,调优也是一个重要的环节。一般来说,我们会设定一组超参数的候选值,然后通过交叉验证等方法,来找到最优的超参数组合。这个过程可能会比较耗时,但通常可以得到更好的结果。
2022-03-112 静静呀已解决GPU找不到的问题
静静呀已解决GPU找不到的问题作者回复: 好嘞,找到GPU就好。
2023-11-13归属地:中国香港- 静静呀老师,现在kaggle打开界面和您的不一样,没有直接勾选GPU的地方,可以帮忙看一下吗
作者回复: 界面有些变化,找到就好
2023-11-13归属地:中国香港  浩仔是程序员老师。你好,深度学习的模型让我有点困惑,不像传统机器学习是一个线性回归等比较具体的算法。而深度学习像是搭了一个网络,而一个网络怎么处理输入,更新内部的参数像是一个黑盒。另外,文中举例的是图片识别的,如果是文本分类的问题也是用同样的模型吗?
浩仔是程序员老师。你好,深度学习的模型让我有点困惑,不像传统机器学习是一个线性回归等比较具体的算法。而深度学习像是搭了一个网络,而一个网络怎么处理输入,更新内部的参数像是一个黑盒。另外,文中举例的是图片识别的,如果是文本分类的问题也是用同样的模型吗?作者回复: 神经网络就是很多很多的线性层,加上很多很多的非线性激活,形成非常非常复杂的函数,里面有很多很多的参数。反正训练之后能用就行了。Open AI的科学家也不知ChatGPT里面参数到底长啥样。 文本分类BERT了解一下。
2023-03-23归属地:广东 jinsiang_sh感觉还是比较懵诶?可能需要重复多理解一下
jinsiang_sh感觉还是比较懵诶?可能需要重复多理解一下作者回复: 也许吧,神经网络看多了就那么回事。看来看去很简单,可能现在还没看熟。
2023-03-23归属地:上海- zoey有讨论群吗
作者回复: 有,加我微信jackyhuang79,我拉你入群学习
2022-11-22归属地:北京2  黄小胖佳哥, label转化成one hot编码后,怎样反正返回原来的label,例如:结果显示第一个图片被 CNN 网络模型分类为第 4 种花(索引从 0 开始,所以类别 3 就是第 4 种花),也就是 Tulip(郁金香)。 这个是怎么知道第4种花就是Tulip(郁金香)。什么函数可以返回0是???,1是???,2是???,3是Tulip。
黄小胖佳哥, label转化成one hot编码后,怎样反正返回原来的label,例如:结果显示第一个图片被 CNN 网络模型分类为第 4 种花(索引从 0 开始,所以类别 3 就是第 4 种花),也就是 Tulip(郁金香)。 这个是怎么知道第4种花就是Tulip(郁金香)。什么函数可以返回0是???,1是???,2是???,3是Tulip。作者回复: Onehot编码生成时,字段名会带有类型的名称作为后缀。 对于图片模型,一般标签会以字典的形式出现,例如: labels_map = { 0: "T-Shirt", 1: "Trouser", 2: "Pullover", 3: "Dress", 4: "Coat", 5: "Sandal", 6: "Shirt", 7: "Sneaker", 8: "Bag", 9: "Ankle Boot", } 或者在数据集的文件夹中说明。 这是构建图片数据集的人需要做的工作,而我们也需要把这个信息读入程序,形成字典,以对应编码和类别。
2021-10-17 宏伟kaggle注册时无法输入验证码,Hoxx也登不上。
宏伟kaggle注册时无法输入验证码,Hoxx也登不上。作者回复: 应该是可以注册呀,可以在群里讨论一下,看看其它同学有无同样问题。
2021-09-273