

09|模型优化(中):防止过拟合,模型也不能太精细
黄佳

你好,我是黄佳。欢迎来到零基础实战机器学习。
前几天,有个同学学完了第 7 讲关于怎样用回归模型预测用户的 LTV 后,就问我说,佳哥啊,我跟着你的思路绘制出了各种回归模型在训练集和验证集上的评分,并进行了比较,有个发现吓了我一跳,你看这个决策树模型,为什么在训练集上得了满分 1.0,而在验证集上的得分却如此低呢?
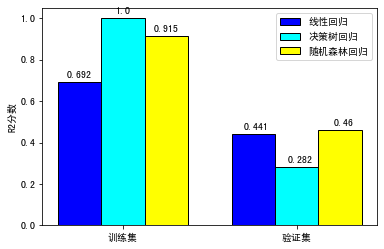
我一看,果然如此。
我告诉他,这就是机器学习中十分著名的“过拟合”现象。可以说,我们用机器学习建模的过程,就是和过拟合现象持续作斗争的过程。那么,什么是过拟合?我们怎么防止模型出现过拟合的问题呢?当你学完了这一讲,自然就有了答案。
什么是过拟合
在我们解释概念前,请你先看一下某相亲平台给出的相亲结果的数据集示意图。
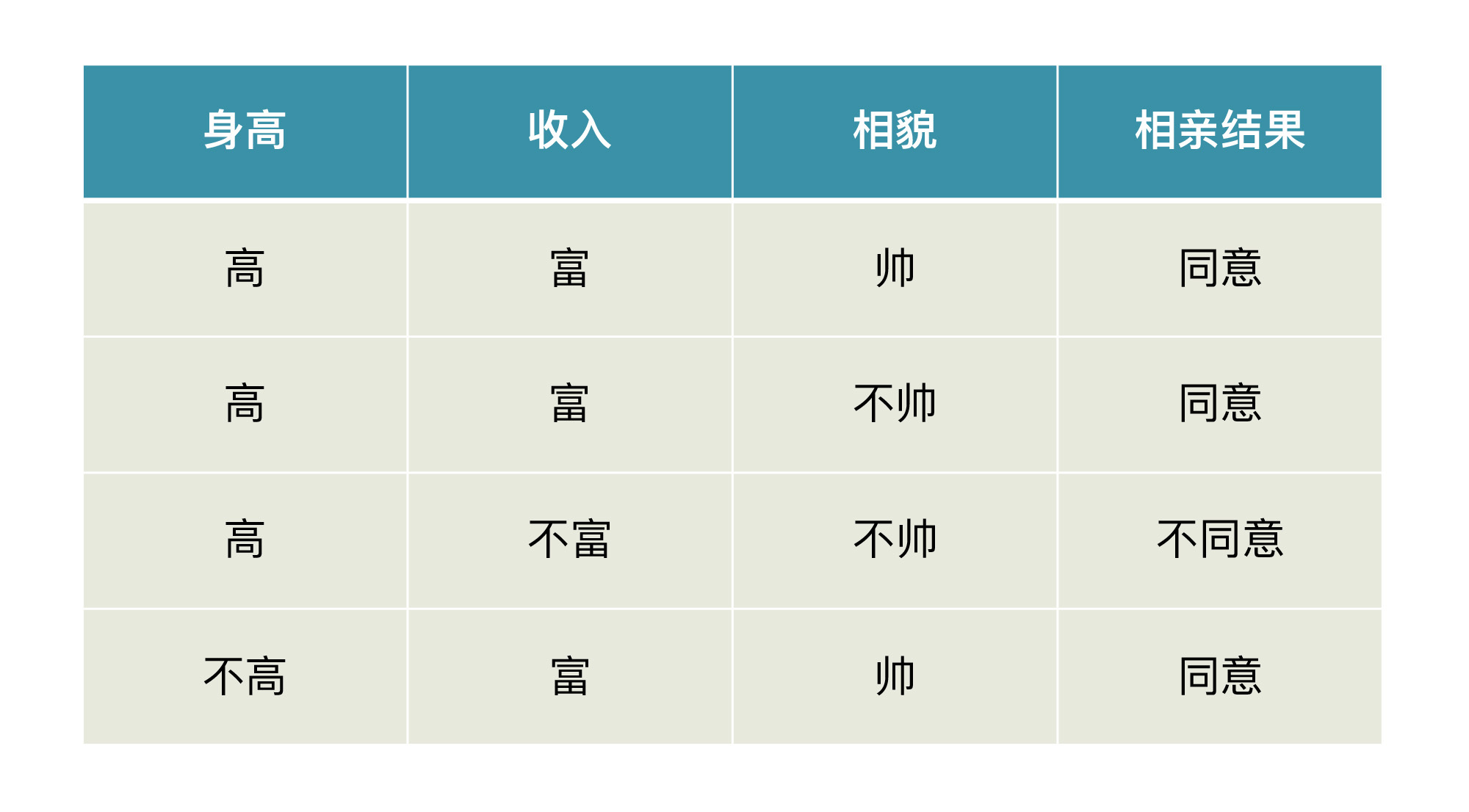
现在,我们假设你的机器学习模型根据这个数据集,给了你一个非常漂亮的函数。这个函数是:如果你不富也不帅,那么你在这个平台相亲就会失败;如果是其它任何一种情况,那你一定会成功。
你有没有感觉到哪里不对?其实,这个模型有一个很严重的问题,就是它过于准确了,犯了在训练集上过拟合的问题。
下面这张图片是嘲讽过拟合现象的,很有意思。 最左边是一堆数据点,中间的模型试图在这些杂乱无章的数据点中挖掘出一些规律,而最右边的模型精准地穿越了每个数据点,最后画出了一只猫。
公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结

本文深入探讨了机器学习模型中常见的过拟合问题,并以相亲平台数据集为例进行了生动解释。作者指出过拟合现象的表现及解决方法,包括增加数据集数量、进行优质的特征工程以及在模型的简单和复杂之间寻找平衡点。此外,还介绍了针对决策树和线性回归模型的简化方法,以帮助读者更好地理解如何防止过拟合。文章通俗易懂,适合初学者快速了解模型优化中的过拟合问题及解决方法。文章内容详实,对于读者快速了解过拟合问题及解决方法具有很高的参考价值。 文章还介绍了线性回归模型的正则化方法,通过引入L1和L2正则项的Lasso回归和Ridge回归,作者比较了这两种正则化方法对模型性能的影响。通过实际代码和结果展示,读者可以清晰地了解正则化在模型优化中的作用和效果。 最后,文章提出了两个思考题,引发读者对于决策树剪枝过程中超参数的影响以及个人工作经验的思考和讨论。 总的来说,本文通过生动的案例和清晰的实例代码,帮助读者深入理解机器学习模型中的过拟合问题及解决方法,同时展示了正则化在模型优化中的重要性。文章内容丰富,适合技术人员和初学者阅读,具有很高的参考价值。
仅可试看部分内容,如需阅读全部内容,请付费购买文章所属专栏
《零基础实战机器学习》,新⼈⾸单¥59
《零基础实战机器学习》,新⼈⾸单¥59
立即购买
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
全部留言(5)
- 最新
- 精选
 谦我觉得比较好的避免过拟合是增加样本数量,使得样本尽可能覆盖主要的应用场景,虽然付出的成本比较高,但是能够得到一个有比较高实用价值的预测模型,曾经试过用14万条数据做回归,线性回归的效果不理想,然后就用了决策树回归,因为数据样本足够多,所以在增加决策树深度的时候,训练得分和测试得分都在增加,这应该算是一个特例。除了增加样本量,一般会先来一次预训练,把所有特征都进行训练,然后通过sklearn里面的feature importance筛选贡献度高的特征重新进行训练,避免特征过多造成的过拟合。
谦我觉得比较好的避免过拟合是增加样本数量,使得样本尽可能覆盖主要的应用场景,虽然付出的成本比较高,但是能够得到一个有比较高实用价值的预测模型,曾经试过用14万条数据做回归,线性回归的效果不理想,然后就用了决策树回归,因为数据样本足够多,所以在增加决策树深度的时候,训练得分和测试得分都在增加,这应该算是一个特例。除了增加样本量,一般会先来一次预训练,把所有特征都进行训练,然后通过sklearn里面的feature importance筛选贡献度高的特征重新进行训练,避免特征过多造成的过拟合。作者回复: 嗯 对的,数据量越大,过拟合的可能越小。排除掉无用的特征也十分必要。谢谢分享!
2021-09-177- 罗辑引用一段解释: 首先我们要区分叶子节点(也称为外部节点 )和内部节点 。内部节点将具有进一步的分割(也称为子节点),而叶子根据定义是没有任何子节点的节点(不能任何进一步的分割)。 min_samples_split指定分割 内部节点 所需的最小样本数,而min_samples_leaf指定在 叶 节点处所需的最小样本数。 例如,如果min_samples_split = 5,并且内部节点有7个样本,则允许拆分。但是,我们说分裂产生了两片叶子,一个带有1个样本,另一个带有6个样本。如果为min_samples_leaf = 2,则将不允许分割(即使内部节点有7个样本),因为生成的叶子之一将少于叶子节点处所需的最小样本数。 min_samples_leaf,无论的值如何,都应保证每个叶子中的样本数量最少min_samples_split。否则,子节点将不进行分裂,直接变成叶子节点。
作者回复: 👍
2021-09-213  在路上佳哥好,min_samples_split和min_samples_leaf的测试结果如下: ``` 训练集上的R平方分数-决策树(min_samples_split=6, min_samples_leaf=3): 0.8116 训练集上的R平方分数-决策树(min_samples_split=4, min_samples_leaf=2): 0.8871 测试集上的R平方分数-决策树(min_samples_split=6, min_samples_leaf=3): 0.4457 测试集上的R平方分数-决策树(min_samples_split=4, min_samples_leaf=2): 0.2393 ``` 由此可见min_samples_split和min_samples_leaf值越小,对训练集拟合越好,对测试集评估越不准确。min_samples_split和min_samples_leaf决定了决策树的深度,值越小,树越深。 今天老师在选择哪个特征作为决策树节点的时候提到了熵的概念,我的理解是哪个特征能够最均匀的把数据一分为二,就选择哪个特征。熵值越小,确定性越高,确定性指的就是数据集的大小越来越小。 最后说一下我发现的几个勘误。分类问题过拟合图示好像错了,和回归问题过拟合图示相同。决策树深度不限和深度为3的代码提示和直方图有误,代码中print信息写成了“深度为2”,直方图是线性回归正则化的图。我觉得给每个图弄一个编号,是不是更容易避免错误。
在路上佳哥好,min_samples_split和min_samples_leaf的测试结果如下: ``` 训练集上的R平方分数-决策树(min_samples_split=6, min_samples_leaf=3): 0.8116 训练集上的R平方分数-决策树(min_samples_split=4, min_samples_leaf=2): 0.8871 测试集上的R平方分数-决策树(min_samples_split=6, min_samples_leaf=3): 0.4457 测试集上的R平方分数-决策树(min_samples_split=4, min_samples_leaf=2): 0.2393 ``` 由此可见min_samples_split和min_samples_leaf值越小,对训练集拟合越好,对测试集评估越不准确。min_samples_split和min_samples_leaf决定了决策树的深度,值越小,树越深。 今天老师在选择哪个特征作为决策树节点的时候提到了熵的概念,我的理解是哪个特征能够最均匀的把数据一分为二,就选择哪个特征。熵值越小,确定性越高,确定性指的就是数据集的大小越来越小。 最后说一下我发现的几个勘误。分类问题过拟合图示好像错了,和回归问题过拟合图示相同。决策树深度不限和深度为3的代码提示和直方图有误,代码中print信息写成了“深度为2”,直方图是线性回归正则化的图。我觉得给每个图弄一个编号,是不是更容易避免错误。作者回复: 好的兄弟,勘误收到!我们马上处理修改!思考题目的分析也正确到位。认真优秀!
2021-09-173- Geek_c665591、当 min_samples_leaf 和 min_samples_split 的值设置的太小,可能会发生over-fitting;如果值设的太大,又可能会发生under-fitting 2、当neural network遇上over-fitting,常用的解决策略包括Dropout,Regularization ,Bagging
作者回复: 对哒
2022-03-082  humor那为什么模型会出现过拟合的状态呢?其实,这是因为机器和我们程序员一样,都有强迫症。 老师,这里说的程序员的强迫症怎么理解啊🤣2024-01-15归属地:浙江1
humor那为什么模型会出现过拟合的状态呢?其实,这是因为机器和我们程序员一样,都有强迫症。 老师,这里说的程序员的强迫症怎么理解啊🤣2024-01-15归属地:浙江1
收起评论