

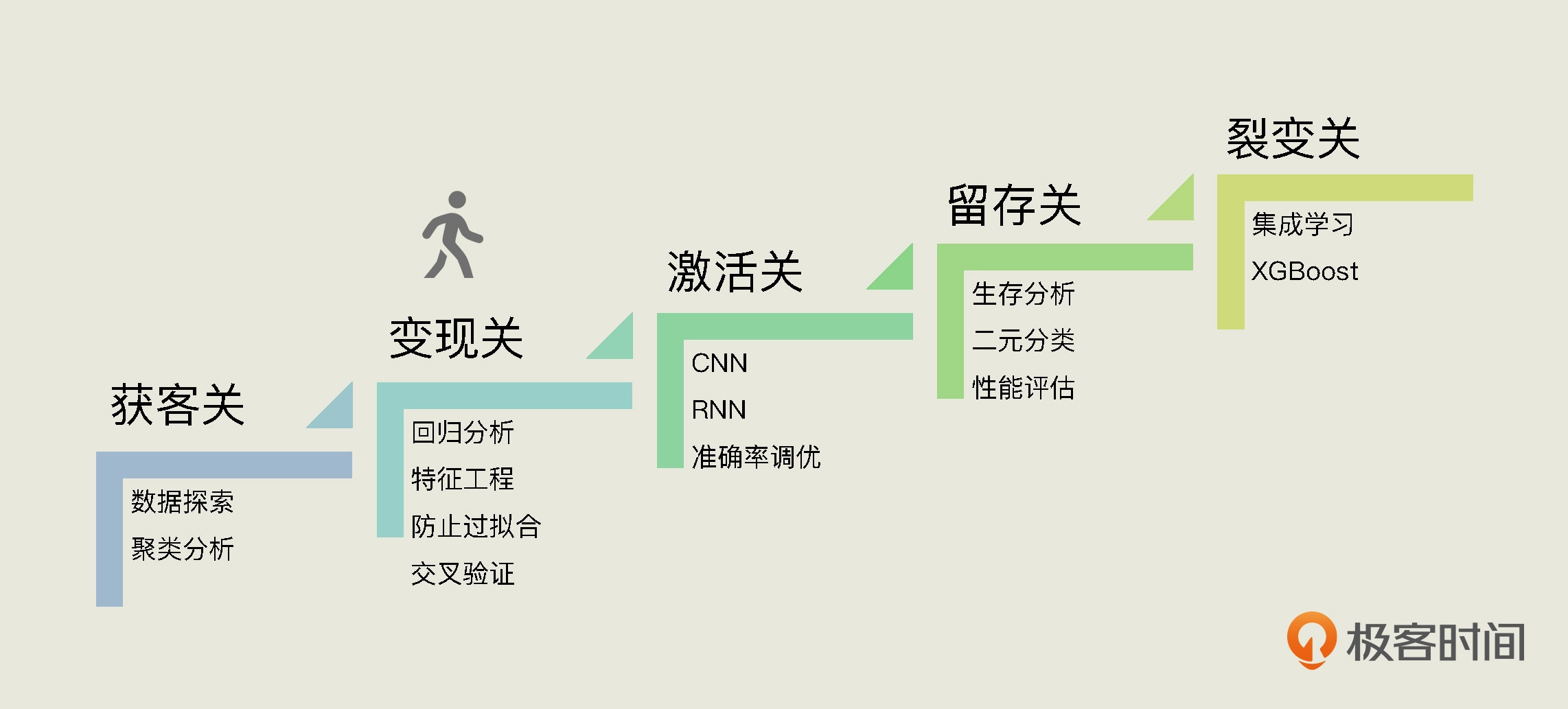
07|回归分析:怎样用模型预测用户的生命周期价值?

定义问题
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

本文介绍了如何利用机器学习中的回归分析来预测用户的生命周期价值(LTV)。作者首先讨论了监督学习和回归问题的实际应用,并提出了一个实际问题:如何利用历史数据来预测新用户未来一两年的消费总额,即用户的生命周期价值。文章重点讨论了数据预处理的重要性,特别是在确定回归模型的输入特征字段时的考虑因素。作者强调了使用头3个月的消费金额和R、F、M值作为特征变量,以及整个12个月的消费金额作为标签字段的重要性。此外,文章还介绍了如何进行数据清洗和构建机器学习数据集的特征和标签字段。通过这些步骤,读者可以了解如何利用机器学习技术来预测用户的生命周期价值,从而指导商业决策和投入。整体而言,本文涉及了监督学习、回归分析以及生命周期价值的概念和应用,为读者提供了一种实际的技术方法来解决商业问题。文章还介绍了拆分训练集和验证集、选择算法创建模型以及训练模型的过程,涵盖了线性回归、决策树和随机森林等算法的比较和应用。通过本文,读者可以快速了解如何利用机器学习技术解决实际的商业问题,以及不同回归算法的应用和比较。
《零基础实战机器学习》,新⼈⾸单¥59

全部留言(23)
- 最新
- 精选
 GAC·DU置顶真值: 14389.900000000007 线性回归预测值: 150.00460000000007 决策树预测值: 106.2 随机森林预测值: 150.00460000000007 验证集上的R平方分数-线性回归: 0.3002 验证集上的R平方分数-决策树: 0.3391 验证集上的R平方分数-随机森林: 0.3353 老师,我复现了一下代码,但是真值和预测值偏差较大,对于这种问题,老师的解决问题思路是什么啊?
GAC·DU置顶真值: 14389.900000000007 线性回归预测值: 150.00460000000007 决策树预测值: 106.2 随机森林预测值: 150.00460000000007 验证集上的R平方分数-线性回归: 0.3002 验证集上的R平方分数-决策树: 0.3391 验证集上的R平方分数-随机森林: 0.3353 老师,我复现了一下代码,但是真值和预测值偏差较大,对于这种问题,老师的解决问题思路是什么啊?作者回复: 关于这个数据点的预测值和真值。这里有几个方面的考量。第一,我们的数据量比较小,只有几百个用户的数据。要得到更健壮的模型,需要很大量的数据。第二,从数据的角度,这个数据点他的前三个月和后12个月消费行为变化比较大。这个用户应该是前面消费很少,后期消费突然增多。那么,从我们这个示例模型的建模方式来说,对这种类型的用户,预测的就会很不准确,可以从特征选择、建模的方法来考虑有没有新的 idea。 其实啊,要预测未来的数值,理论上虽可行,但一定要做好有巨大误差的准备。这和预测股价类似,理论上模型可能预测一个上升趋势,但是实际上可能因为特殊因素突然大幅下跌。
2021-09-134 在路上置顶佳哥好,加上SVM和朴素贝叶斯算法之后R^2值为: ``` 验证集上的R平方分数-线性回归: 0.4333 验证集上的R平方分数-决策树: 0.3286 验证集上的R平方分数-随机森林: 0.5130 验证集上的R平方分数-SVM: -0.1085 验证集上的R平方分数-朴素贝叶斯: 0.4417 ``` 可以看到朴素贝叶斯算法的效果也不错,SVM算法的效果则很差。写Demo的时候发现sklearn库非常强大,测试不同算法的效果非常容易。 回归问题的评估指标有很多种,R^2、均方误差、中值绝对误差有什么区别呢?首先是取标准值,是数据集的中值,还是数据集加总后的平均值。然后是误差的计算,距离标准值越大,结果以什么样的形式放大,是差值的绝对值,还是差值的平方,平方意味结果被显著的放大,差值越大的数据影响越大。最后是消除原始数据离散的影响,这体现在R^2计算公式的分母中,原始数据离散程度越高,很可能会导致预测结果的波动越大。
在路上置顶佳哥好,加上SVM和朴素贝叶斯算法之后R^2值为: ``` 验证集上的R平方分数-线性回归: 0.4333 验证集上的R平方分数-决策树: 0.3286 验证集上的R平方分数-随机森林: 0.5130 验证集上的R平方分数-SVM: -0.1085 验证集上的R平方分数-朴素贝叶斯: 0.4417 ``` 可以看到朴素贝叶斯算法的效果也不错,SVM算法的效果则很差。写Demo的时候发现sklearn库非常强大,测试不同算法的效果非常容易。 回归问题的评估指标有很多种,R^2、均方误差、中值绝对误差有什么区别呢?首先是取标准值,是数据集的中值,还是数据集加总后的平均值。然后是误差的计算,距离标准值越大,结果以什么样的形式放大,是差值的绝对值,还是差值的平方,平方意味结果被显著的放大,差值越大的数据影响越大。最后是消除原始数据离散的影响,这体现在R^2计算公式的分母中,原始数据离散程度越高,很可能会导致预测结果的波动越大。作者回复: "写Demo的时候发现sklearn库非常强大,测试不同算法的效果非常容易。" ---- 太棒了,你发现了这一点,这个课程就没有白学了。用好它!😍
2021-09-131 李冀置顶“通过不同RFM层级就可以确定不同的获客成本”。但花钱引流时不知道RFM值啊,再建立一个渠道、城市到RFM的模型?感觉初期RFM到LTV的关系对促活更有指导意义,而不是拉新
李冀置顶“通过不同RFM层级就可以确定不同的获客成本”。但花钱引流时不知道RFM值啊,再建立一个渠道、城市到RFM的模型?感觉初期RFM到LTV的关系对促活更有指导意义,而不是拉新作者回复: 对的。总结的好。RFM主要用于观察老用户,然后促进在老用户身上的营收增长,精细化运营。 在拉新过程中,也就是起到一些估计指导意义,大概估计一批新用户有可能带来的平均回报吧。
2021-09-132 For Uuuuu置顶有交流群吗?
For Uuuuu置顶有交流群吗?作者回复: 有,欢迎加群,方式见课程介绍链接。 https://time.geekbang.org/column/intro/438
2021-09-1323- Geek_06d12d预测值和老师贴的相差较大,看了下老师在github上的代码,发现再清洗的时候没有把数量小于0的给清洗掉。
作者回复: 谢谢同学的分享和发现!
2022-10-07归属地:浙江3  松饼Muffin老师, 想到一个问题, 客户的第一次购买时间(即获客时间)并不都 是从2020年6月1号开始, 所以要选取特征值(客户前三个月的RFM)是不是以该客户第一次购买后的三个月内的数值更公平些?同理, 标签值(客户12个月的购买金额)是不是也用自从该客户第一次购买以来的12个月内的总购买金额为妥?
松饼Muffin老师, 想到一个问题, 客户的第一次购买时间(即获客时间)并不都 是从2020年6月1号开始, 所以要选取特征值(客户前三个月的RFM)是不是以该客户第一次购买后的三个月内的数值更公平些?同理, 标签值(客户12个月的购买金额)是不是也用自从该客户第一次购买以来的12个月内的总购买金额为妥?作者回复: 同学的这个思路挺好的,值得试试。
2022-03-1633 青松这个课程有jupyter notebook格式的文档吗?想一边教学一边实践
青松这个课程有jupyter notebook格式的文档吗?想一边教学一边实践作者回复: 有啊,所有的jupyter notebook我不是都上载到GitHub里面了么。https://github.com/huangjia2019/geektime
2021-09-162 190coderrfm值高会不会有边际效益递减的问题,应该多花钱给Rfm低的用户,弹性更大
190coderrfm值高会不会有边际效益递减的问题,应该多花钱给Rfm低的用户,弹性更大作者回复: 也是一种思路!
2023-01-11归属地:北京1 谦sklearn很好用,不过在实际项目中我经常需要把训练好的模型移植到其他平台上,例如用c语言重新实现一次预测模型,一般来说svm移植比较简单,找到coef_和intercept_,复制一下就可以。决策树相对麻烦一点,要递归遍历整棵树,输出特征和阈值。随机森林或者使用决策树的adaboost就要遍历很多棵树。想请问佳哥在预测模型的移植和应用上有没有一些经验可以分享一下?谢谢😊
谦sklearn很好用,不过在实际项目中我经常需要把训练好的模型移植到其他平台上,例如用c语言重新实现一次预测模型,一般来说svm移植比较简单,找到coef_和intercept_,复制一下就可以。决策树相对麻烦一点,要递归遍历整棵树,输出特征和阈值。随机森林或者使用决策树的adaboost就要遍历很多棵树。想请问佳哥在预测模型的移植和应用上有没有一些经验可以分享一下?谢谢😊作者回复: 在模型移植这方面,我的经验就相对有限一些。因为大的项目组中,负责建模和负责模型部署,或者模型移植复现的是两组人。让我来查阅一下相关方面的资料,然后在后面做一些分享。😁
2021-09-141 地平线验证集上的均方误差-线性回归: 10657316.3310 验证集上的均方误差-决策树: 11584241.1637 验证集上的均方误差-随机森林: 10526728.9502 验证集上的均方误差-支持向量机: 17952311.0810 验证集上的均方误差-贝叶斯: 10463919.5367 验证集上的中值绝对误差-线性回归: 757.0875 验证集上的中值绝对误差-决策树: 798.1450 验证集上的中值绝对误差-随机森林: 868.3853 验证集上的中值绝对误差-支持向量机: 1002.8237 验证集上的中值绝对误差-贝叶斯: 718.2908
地平线验证集上的均方误差-线性回归: 10657316.3310 验证集上的均方误差-决策树: 11584241.1637 验证集上的均方误差-随机森林: 10526728.9502 验证集上的均方误差-支持向量机: 17952311.0810 验证集上的均方误差-贝叶斯: 10463919.5367 验证集上的中值绝对误差-线性回归: 757.0875 验证集上的中值绝对误差-决策树: 798.1450 验证集上的中值绝对误差-随机森林: 868.3853 验证集上的中值绝对误差-支持向量机: 1002.8237 验证集上的中值绝对误差-贝叶斯: 718.2908作者回复: 好
2023-08-11归属地:上海