

19 | 查询性能优化:计算与存储分离架构下有哪些优化思路?
王磊

该思维导图由 AI 生成,仅供参考
你好,我是王磊,你也可以叫我 Ivan。
我在第 4 讲介绍架构风格时曾经提到过,分布式数据库的主体架构是朝着计算和存储分离的方向发展的,这一点在 NewSQL 架构中体现得尤其明显。但是计算和存储是一个完整的过程,架构上的分离会带来一个问题:是应该将数据传输到计算节点 (Data Shipping),还是应该将计算逻辑传输到数据节点 (Code Shipping)?
从直觉上说,肯定要选择 Code Shipping,因为 Code 的体量远小于 Data,因此它能传输得更快,让系统的整体性能表现更好。
这个将 code 推送到存储节点的策略被称为“计算下推”,是计算存储分离架构下普遍采用的优化方案。
计算下推
将计算节点的逻辑推送到存储节点执行,避免了大量的数据传输,也达到了计算并行执行的效果。这个思路还是很好理解的,我们用一个例子来具体说明下。
假如有一张数据库表 test,目前有四条记录。
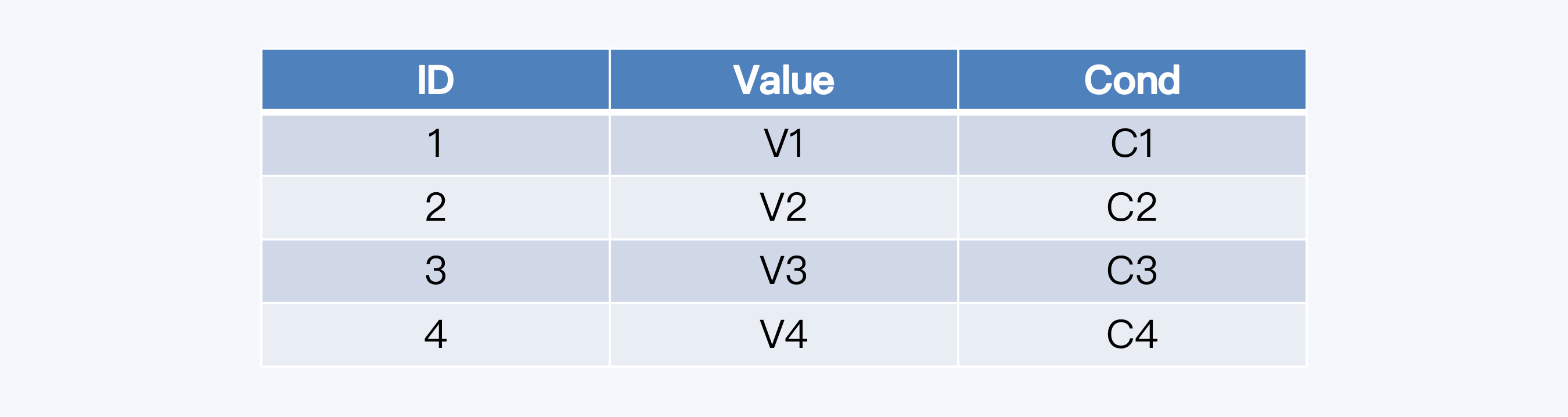
我们在客户端执行下面这条查询 SQL。
计算节点接到这条 SQL 后,会将过滤条件“cond=‘C1’“下推给所有存储节点。

存储节点 S1 有符合条件的记录,则返回计算节点,其他存储节点没有符合的记录,返回空。计算节点直接将 S1 的结果集返回给客户端。
公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结

分布式数据库领域的热门话题之一是计算与存储分离架构下的查询性能优化。本文介绍了在这种架构下的优化思路,包括计算下推、TiDB的挑战、分区键与Join下推以及索引分布。计算下推通过将计算节点的逻辑推送到存储节点执行,避免大量数据传输,实现计算并行执行的效果。TiDB在处理下推时面临挑战,但通过改进缓存数据的组织方式,解决了这一问题。分区键与Join下推对于减少数据移动、降低网络开销起着重要作用,但在多表使用相同分区键时可能面临性能均衡挑战。另外,索引分布也是分布式数据库优化的重要手段,对于读写性能有很大影响。总的来说,本文深入浅出地介绍了分布式数据库查询性能优化的关键思路和挑战,对于从事分布式数据库开发和优化的技术人员具有一定的参考价值。文章还介绍了分区索引和全局索引的优缺点,以及计算下推的概念和挑战。文章提出了思考题,引发读者对计算下推的冗余算法进行讨论。整体而言,本文对分布式数据库的优化策略和技术挑战进行了全面而深入的探讨,为相关领域的技术人员提供了有益的学习资料。
仅可试看部分内容,如需阅读全部内容,请付费购买文章所属专栏
《分布式数据库 30 讲》,新⼈⾸单¥59
《分布式数据库 30 讲》,新⼈⾸单¥59
立即购买
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
全部留言(12)
- 最新
- 精选
- myrfy分区内将数据排序好,返回计算节点,计算节点只需要对排序列表做合并即可。
作者回复: 大致上是这样,做的更好些还要考虑如何控制数据节点的数据读放大。
2020-09-215  haijian.yang期待老师多分享 NewSQL 的知识。 作为创业公司来说,现在用 NewSQL 成本还是挺高的(资源成本、运维成本等),期待未来可以像 MySQL 这样的传统数据库一样具备很好的性价比。
haijian.yang期待老师多分享 NewSQL 的知识。 作为创业公司来说,现在用 NewSQL 成本还是挺高的(资源成本、运维成本等),期待未来可以像 MySQL 这样的传统数据库一样具备很好的性价比。作者回复: :),相信随着分布式数据库更加成熟,成本会降低的。反过来看,早一点了解这些内容,也会让技术先行者享受到更多的技术红利。
2020-09-213 丹尼尔-雪碧请问老师,为什么唯一索引(全局索引)为什么没办法做到数据与索引同分布。
丹尼尔-雪碧请问老师,为什么唯一索引(全局索引)为什么没办法做到数据与索引同分布。作者回复: 基于局部信息是无法判断全局唯一性,那就必须集中存储索引,而为了追求最大的并发I/O,数据必然是分散的,所以索引和数据就无法同分布了
2022-04-172 平风造雨分区索引是指索引是存在于对应的分区节点上,全局索引的话,只能把索引的数据都放到全局的节点上是吗?
平风造雨分区索引是指索引是存在于对应的分区节点上,全局索引的话,只能把索引的数据都放到全局的节点上是吗?作者回复: 全局索引下,索引也是分布式存储的,不是单点,只不过无法保证和数据同分布。
2020-09-241 旅途老师,问一下分区索引使用like查询不是全表扫描了吗,这样比直接查询索引的优点在哪呢
旅途老师,问一下分区索引使用like查询不是全表扫描了吗,这样比直接查询索引的优点在哪呢作者回复: 左前缀like并不会全表扫描
2020-10-05 扩散性百万咸面包截取这一段:写操作的延迟更长,因为任何情况下索引应该与数据保持一致,如果同分布,那么数据变更时可以通过本地事务保证,但在全局索引下就变成了一个分布式事务,代价当然更高了。 想问:是不是所有的写事务都要立刻维护索引表呢?感觉这样的代价太大了,优化成异步后台线程来处理可能好一些。
扩散性百万咸面包截取这一段:写操作的延迟更长,因为任何情况下索引应该与数据保持一致,如果同分布,那么数据变更时可以通过本地事务保证,但在全局索引下就变成了一个分布式事务,代价当然更高了。 想问:是不是所有的写事务都要立刻维护索引表呢?感觉这样的代价太大了,优化成异步后台线程来处理可能好一些。作者回复: 这个肯定不行,刚刚写入的数据可能会查不出来。前面为了数据一致性做了那么多努力不就白费了吗
2020-09-21
 槑·先生
槑·先生 Bucket保持同分布那块不是太理解2021-04-121
Bucket保持同分布那块不是太理解2021-04-121- Geek_e4b244老师,这里的“架构上的分离会带来一个问题:是应该将数据传输到计算节点 (Data Shipping),还是应该将计算逻辑传输到数据节点 (Code Shipping)?”两个节点英文命名,是不是搞反了? 是不是,计算节点 (Code Shipping),数据节点 (Data Shipping), 这个思路,是不是就是,移动计算比移动数据个更划算的思路。2022-11-10归属地:河南1
 鱼分区索引分裂时,同分布的索引和数据装入一个更小的组织单元 (Bucket),而不是以整个数据节点为单位。这个思路和一致性Hash引入虚拟节点有异曲同工之妙。2022-07-03
鱼分区索引分裂时,同分布的索引和数据装入一个更小的组织单元 (Bucket),而不是以整个数据节点为单位。这个思路和一致性Hash引入虚拟节点有异曲同工之妙。2022-07-03- 鱼全局唯一写入较慢且非常复杂,所以数据库通常只能使用异步更新二级索引,进而导致全局索引表现为最终一致性。2022-07-03
收起评论

