

16 | 为什么不建议你使用存储过程?

该思维导图由 AI 生成,仅供参考
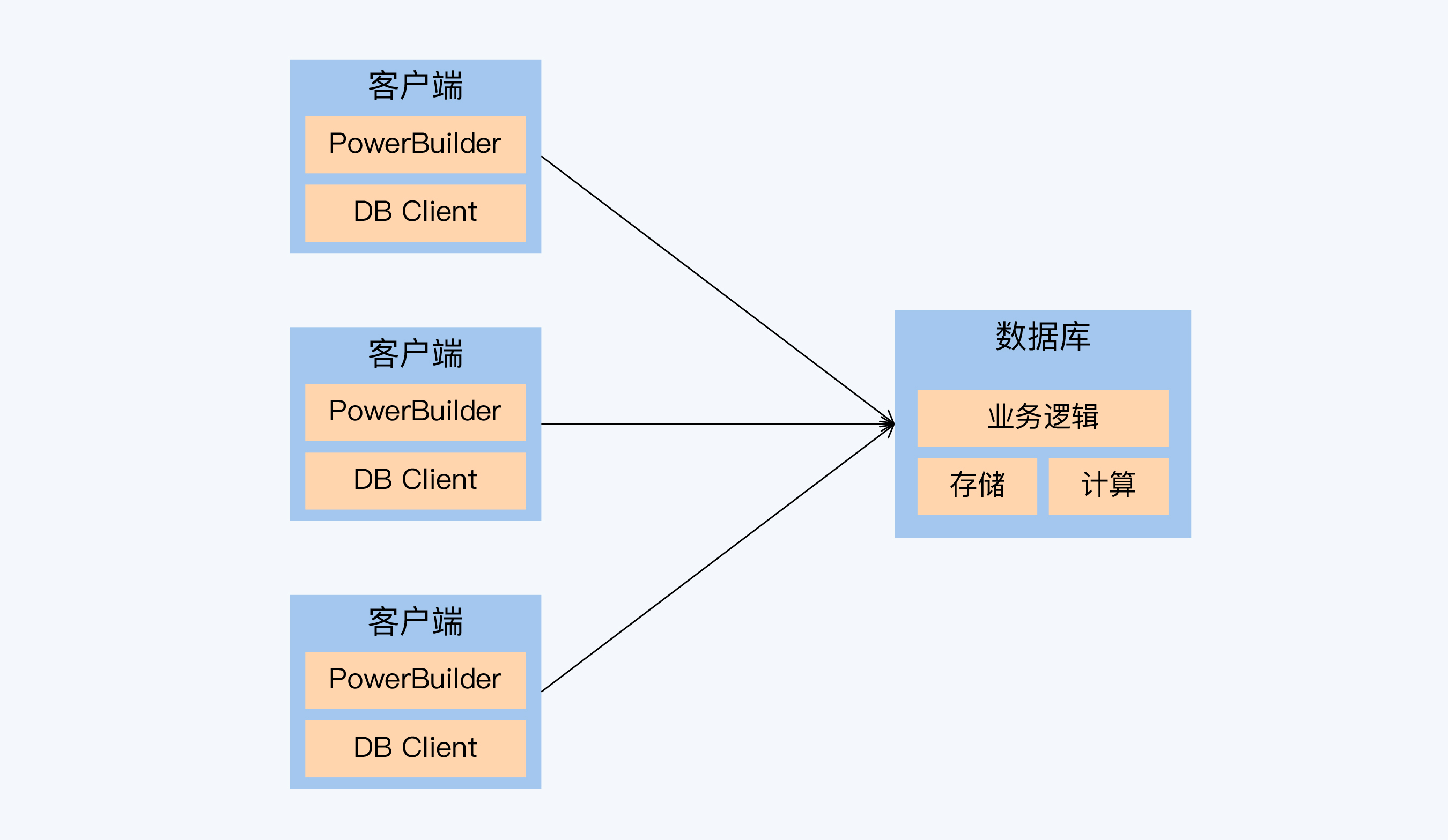
我从 C/S 时代走来
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

存储过程在数据库开发中曾扮演重要角色,但随着技术发展和工程化水平提升,其使用受到质疑。本文从作者亲身经历出发,探讨了存储过程的优点和问题。文章首先回顾了存储过程在C/S时代的盛行,指出其在数据密集型操作中的性能优势。然而,也提到了存储过程的移植性差、难以调试和扩展的问题,以及对特定数据库环境的依赖性。对比了存储过程与触发器的命运,指出它们面临的核心问题是需要与整个技术生态相融合。文章还介绍了分布式数据库对存储过程的支持情况,以及一些新的存储过程实现方案,如独立UDF Server和VoltDB的存储过程支持。最后,强调了工程化要求对技术选择的重要性。文章深入浅出地阐述了存储过程的优缺点,引发了对数据库开发技术选择的思考。
《分布式数据库 30 讲》,新⼈⾸单¥59

全部留言(15)
- 最新
- 精选
 Jxin
Jxin 对本章的理解: 1.业务代码跟技术代码应该要分离,我们需要保证业务逻辑到业务代码的翻译简单而纯粹。这既是在实现阶段,降低对具体技术的耦合,也是在保证业务代码的可测试性以及业务代码的简单和内聚。 2.具体技术的特性(比如存储过程)往往能起到杰出的性能。但这也增加了实现阶段的复杂性,而复杂意味着难维护,意味着成本和风险。虽然实现了软件行为价值,但架构质量上的健康却受到了伤害。所以在性能要求严格的场景,使用具体技术的一些特性无可厚非,但要保持警惕,认清这是把双刃剑。不可仗着自己"功力深厚"而肆意妄为。 3.没经历过c/s的时代。但从数据模型驱动设计的相关书籍中,可以看到存储过程在当初是如何的大行其道。可是放在现在,当存储过程等一系列手段成过去式后,数据模型驱动设计就开始变得很"贫血"。基本只剩实体关系模型和数据项这点单薄的信息承载能力,已经不适合再驱动复杂的业务软件的设计。 4.放上自己对数据模型驱动的实现,以做交流: https://github.com/Jxin-Cai/mdd/tree/master/data-model/mini-faas 课后题: VoltDB的这个分片复制和rocketMq的nameserver有异曲同工之妙。通过并行对所有副本执行操作,规避副本间达成共识的复杂性。
对本章的理解: 1.业务代码跟技术代码应该要分离,我们需要保证业务逻辑到业务代码的翻译简单而纯粹。这既是在实现阶段,降低对具体技术的耦合,也是在保证业务代码的可测试性以及业务代码的简单和内聚。 2.具体技术的特性(比如存储过程)往往能起到杰出的性能。但这也增加了实现阶段的复杂性,而复杂意味着难维护,意味着成本和风险。虽然实现了软件行为价值,但架构质量上的健康却受到了伤害。所以在性能要求严格的场景,使用具体技术的一些特性无可厚非,但要保持警惕,认清这是把双刃剑。不可仗着自己"功力深厚"而肆意妄为。 3.没经历过c/s的时代。但从数据模型驱动设计的相关书籍中,可以看到存储过程在当初是如何的大行其道。可是放在现在,当存储过程等一系列手段成过去式后,数据模型驱动设计就开始变得很"贫血"。基本只剩实体关系模型和数据项这点单薄的信息承载能力,已经不适合再驱动复杂的业务软件的设计。 4.放上自己对数据模型驱动的实现,以做交流: https://github.com/Jxin-Cai/mdd/tree/master/data-model/mini-faas 课后题: VoltDB的这个分片复制和rocketMq的nameserver有异曲同工之妙。通过并行对所有副本执行操作,规避副本间达成共识的复杂性。作者回复: 咋看字数很多,但每一条分析很清晰,总结的非常好,点赞。
2020-09-16417- vkingnew1.“《阿里巴巴 Java 开发手册》中也赫然写着“禁止使用存储过程,存储过程难以调试和扩展,更没有移植性。” 这个有误导的嫌疑,这里的存储过程针对的是MySQL,确实难以调试难以复制。在同等时代的产品产品中以oracle的PL/SQL,SQL server 的T-SQL编写的存储过程还是很有优势的,DB2和Oracle都支持PL/SQL的,这里PL/SQL是具有移植性的,并且这个存储过程在SQL标准中叫做(SQL/PSM (SQL/Persistent Stored Modules) https://en.wikipedia.org/wiki/SQL/PSM)。 2.纵贯SQL标准的发展以及oracle的发展,存储过程的支持也是有发展历程的,存储过程在性能和开发效率上还是蛮高的。在大数据时代人们讲存储分离,存储归存储,计算归计算,在硬件和成本平衡的基础上,通过水平扩展来增加算力,把存储过程功能暂时不开发或者说难以开发,但是Apache hive是支持的存储过程的叫做hpsql。 3.在分布式数据库中的典型的代表 TiDB和CockroachDB 二者在语法兼容以及对存储过程的支持上有些不同,CockroachDB是支持pg语法的存储过程的(pg类似于PL/SQL)。
作者回复: 我个人认为,阿里开发手册的这条建议不是特指MySQL,放在MySQL这一章可能因为MySQL在阿里使用比较多,是有代表性的数据库。难道他们一边宣传禁用MySQL存储过程,一边暗地里快乐的用着Oracle的存储过程?似乎不大可能。 另外,SQL标准对所有数据库都只是参照,不同的数据库,数据类型、全局变量、函数、甚至存储过程名的长度都有差异。没有完全相同的数据库,除非是专门适配。这也是为什说系统切换数据库是个大事。 了解这些差异后,有的同学可能依然觉得这不是事,so easy。对个体来说,难还是易是个很主观的判断,关键在于你的团队是否能长期、低成本的使用这项技术,如果可以那也未尝不可。
2020-09-204  Andy Huang互联网的sql不用存储过程 也不用显式事务,都是单独SQL语句的隐式事务么?那应该是互联网的业务比较简单 如果复杂业务的Erp可不流行这样,否则业务代码非常复杂,这样无法真正利用数据库的事务功能,不可惜么。?
Andy Huang互联网的sql不用存储过程 也不用显式事务,都是单独SQL语句的隐式事务么?那应该是互联网的业务比较简单 如果复杂业务的Erp可不流行这样,否则业务代码非常复杂,这样无法真正利用数据库的事务功能,不可惜么。?作者回复: 不用存储过程,不是说只能用单独的SQL语句。
2022-07-10归属地:北京- ifxdba存储过程就是一个死穴,一旦上路,便没有看了回头路
作者回复: 也没有这么夸张啦:),对一些特定需求还是有独特价值的。
2020-09-23  佳佳的爸存储过程是单机数据库时代的不可替代的产物,当年我当程序员的时候,存储过程是最好的解决前后端代码分离的利器。一个10万条订单批量审核的操作,调用存储过程几分钟搞定,前端vb代码执行,一个小时都出不了结果
佳佳的爸存储过程是单机数据库时代的不可替代的产物,当年我当程序员的时候,存储过程是最好的解决前后端代码分离的利器。一个10万条订单批量审核的操作,调用存储过程几分钟搞定,前端vb代码执行,一个小时都出不了结果作者回复: 是的,存储过程对于数据密集型计算,绝对是一大利器。
2020-09-143- 佳佳的爸OceanBase支持Oracle的存储过程是迫不得已的事情,因为这决定着 它是否能 "侵入" Oracle的传统客户阵营-大企业和金融领域,是一种纯粹的商业行为。举个例子来说,Oracle 的ERP产品中大量采用了存储过程来实现业务逻辑,最复杂的业务逻辑的源码打印出来几十页,这么复杂的存储过程 我相信 OceanBase的工具是无法完美处理(移植到OB)的,但是为了竞标之类的商业行为,你如果不支持Oracle的很多特性 你就根本没有参与的机会。 这就是中国的现实情况。2020-09-1419
- 佳佳的爸VoltDB用K-safety机制解决数据复制的问题,其实就是N+1的副本机制,VoltDB在写数据操作的时候,会在每个副本中执行该语句,这样就可以保证数据被正确插入每个副本。这N+1的副本都可以同时提供访问,同时允许最多N个副本丢失(分区故障), 当N+1个副本都不可用的时候,VoltDB就会停止服务进行修复。2020-09-142

 一想再想NMySQL不允许开发使用存储过程,但是dba自己可以用。2022-10-31归属地:北京
一想再想NMySQL不允许开发使用存储过程,但是dba自己可以用。2022-10-31归属地:北京- Andy Huang如果应用使用存储过程 当前主流的中间件 是否支持读写分离?2022-07-10
- Sai王老师,请问你的那个存储过程移植问题最后怎么解决的,最后是不用存储过程了吗?2022-06-041

