

18 | HTAP是不是赢者通吃的游戏?
王磊

该思维导图由 AI 生成,仅供参考
你好,我是王磊,你也可以叫我 Ivan。
这一讲的关键词是 HTAP,在解释这个概念前,我们先要搞清楚它到底能解决什么问题。
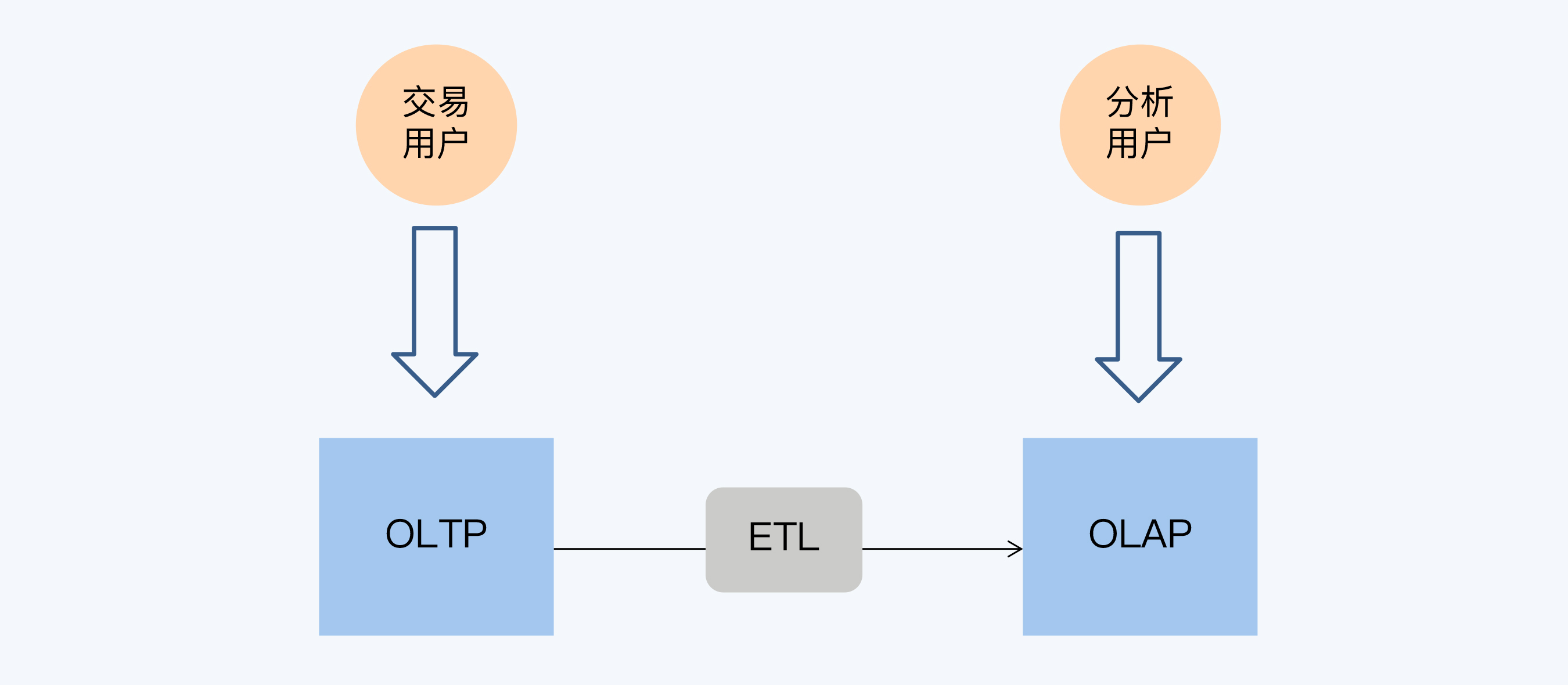
OLAP 和 OLTP 通过 ETL 进行衔接。为了提升 OLAP 的性能,需要在 ETL 过程中进行大量的预计算,包括数据结构的调整和业务逻辑处理。这样的好处是可以控制 OLAP 的访问延迟,提升用户体验。但是,因为要避免抽取数据对 OLTP 系统造成影响,所以必须在日终的交易低谷期才能启动 ETL 过程。这样一来, OLAP 与 OLTP 的数据延迟通常就在一天左右,习惯上大家把这种时效性表述为 T+1。其中,T 日就是指 OLTP 系统产生数据的日期,T+1 日是 OLAP 中数据可用的日期,两者间隔为 1 天。
你可能已经发现了,这个体系的主要问题就是 OLAP 系统的数据时效性,T+1 太慢了。是的,进入大数据时代后,商业决策更加注重数据的支撑,而且数据分析也不断向一线操作渗透,这都要求 OLAP 系统更快速地反映业务的变化。
两种解决思路
说到这,你应该猜到了,HTAP 要解决的就是 OLAP 的时效性问题,不过它也不是唯一的选择,这个问题有两种解决思路:
公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结

HTAP系统是OLTP和OLAP整合的一种解决方案,本文探讨了HTAP系统的设计思路和存储引擎的不同方案。文章首先介绍了PAX和TiFlash两种存储设计,分析了它们在解决OLAP时效性问题上的优劣势。PAX采用了一种兼容性更好的存储方式,而TiFlash则通过创新性的同步机制保证了OLTP和OLAP的数据一致性。此外,文章还详细介绍了TiFlash的存储引擎Delta Tree的设计,以及如何平衡读写性能。在讨论HTAP系统的发展前景时,文章指出了HTAP系统在商业场景中未必有足够多的刚性需求,因此更看好以流计算为基础的新OLAP体系。然而,HTAP系统也具有相对优势,通过全家桶方案避免了用户集成多个技术产品,降低了整体技术复杂度。最后,文章提出了一个思考题,探讨了TiFlash保持数据一致性的方法是否还能够优化,以及在什么情况下不需要与Leader通讯。
仅可试看部分内容,如需阅读全部内容,请付费购买文章所属专栏
《分布式数据库 30 讲》,新⼈⾸单¥59
《分布式数据库 30 讲》,新⼈⾸单¥59
立即购买
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
全部留言(10)
- 最新
- 精选
 游弋云端可以后台启动一个轮询日志增量的线程,当差异大于一定量的时候触发实际的数据同步。或者在心跳包中增加一个版本用于比对,当差异大的时候,触发主动同步。这样不用等到请求到达时触发,省掉这个等待时延。但是由于是Raft的非成员节点,怎么做都会有一定的数据差异,单对于大多OLAP分析场景应该是足够使用了。2020-09-184
游弋云端可以后台启动一个轮询日志增量的线程,当差异大于一定量的时候触发实际的数据同步。或者在心跳包中增加一个版本用于比对,当差异大的时候,触发主动同步。这样不用等到请求到达时触发,省掉这个等待时延。但是由于是Raft的非成员节点,怎么做都会有一定的数据差异,单对于大多OLAP分析场景应该是足够使用了。2020-09-184 iswade可以通过读一致的旧版本来实现吧,对于OLAP也完全满足要求了。2021-06-0811
iswade可以通过读一致的旧版本来实现吧,对于OLAP也完全满足要求了。2021-06-0811 tt没有接触过OLAP。 是不是可以不用每次都去请求“最新”的日志增量,而是按需请求数据:本地保存一个数据新旧的时间戳,如果早于读请求的时间戳,就不用去请求了; 或者设置一个质量因子,可以做到分配请求数据,采用类似滑动平均的算法,动态计算目标指标,达到质量要求后就停止请求数据。2020-09-181
tt没有接触过OLAP。 是不是可以不用每次都去请求“最新”的日志增量,而是按需请求数据:本地保存一个数据新旧的时间戳,如果早于读请求的时间戳,就不用去请求了; 或者设置一个质量因子,可以做到分配请求数据,采用类似滑动平均的算法,动态计算目标指标,达到质量要求后就停止请求数据。2020-09-181- Geek_761876有人说两份数据的做法是"缝合怪",老师怎么看这个问题?2022-07-26

 易轻尘最近Snowflake也公布了进军HTAP2022-07-15
易轻尘最近Snowflake也公布了进军HTAP2022-07-15 不负青春不负己🤘我看好多其他开源写的db 项目,delta Tree2022-04-29
不负青春不负己🤘我看好多其他开源写的db 项目,delta Tree2022-04-29 杜思奇我认为OLAP相当于一艘大轮船(技术上追求高吞吐 QPS)而OLTP相当于一辆小轿车(技术追求高并发 、低延迟)2021-12-28
杜思奇我认为OLAP相当于一艘大轮船(技术上追求高吞吐 QPS)而OLTP相当于一辆小轿车(技术追求高并发 、低延迟)2021-12-28 幼儿编程教学pax格式其实没太看懂。特别是和dsm的区别。老师能否再详细介绍下?谢谢!2020-11-22
幼儿编程教学pax格式其实没太看懂。特别是和dsm的区别。老师能否再详细介绍下?谢谢!2020-11-22- myrfy当客户请求的时间戳可以确信小于服务端的时间戳时。难点应该就是如何保证客户端和服务端在时间上的同步。2020-09-18
 Fan()受益匪浅2020-09-18
Fan()受益匪浅2020-09-18
收起评论

