

12 | 隔离性:看不见的读写冲突,要怎么处理?

该思维导图由 AI 生成,仅供参考
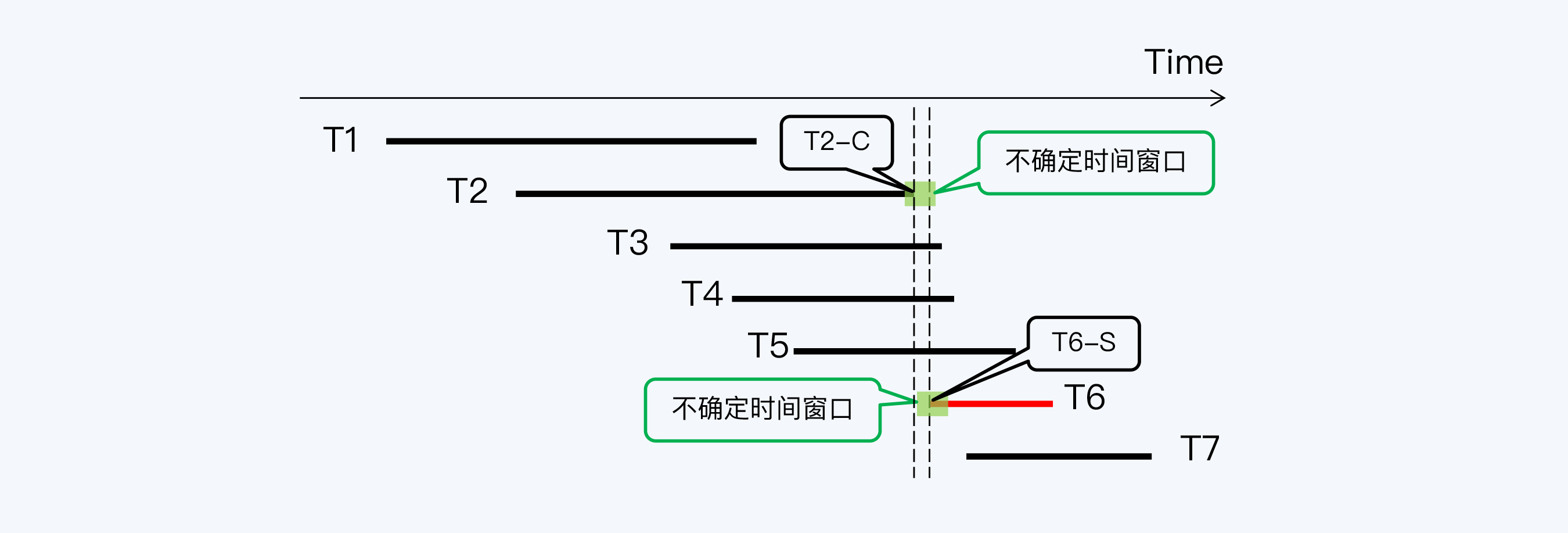
不确定时间窗口
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

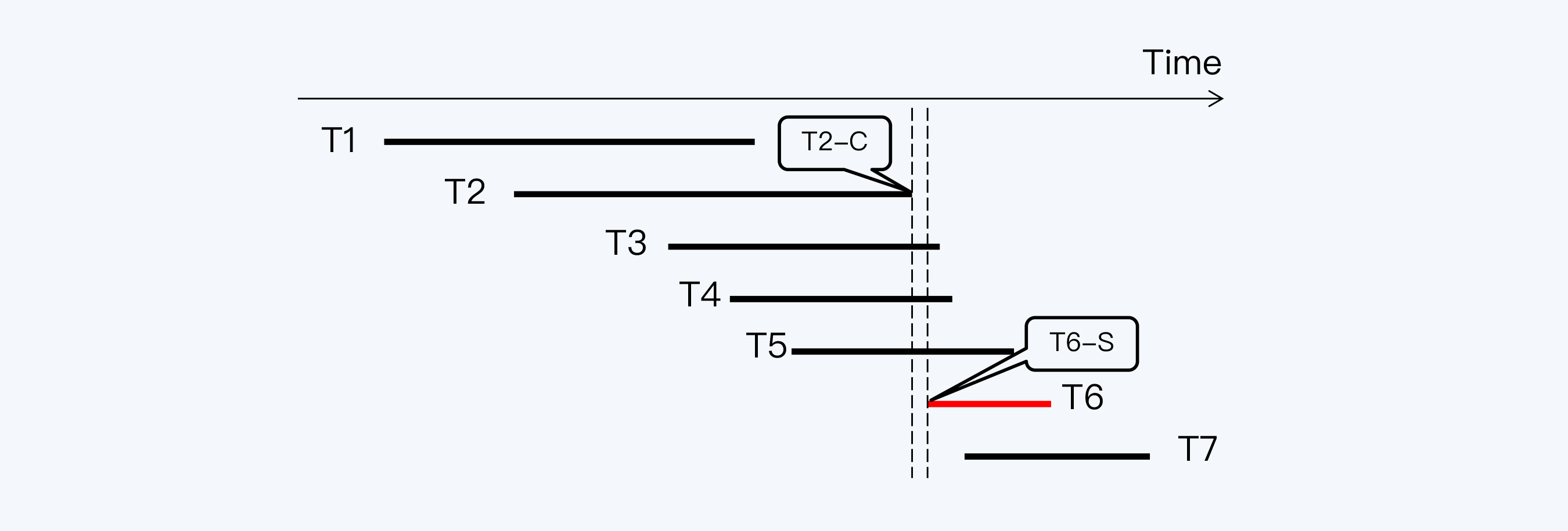
分布式系统中的时间误差会导致隐蔽的读写冲突问题,需要采取相应的处理方式。本文介绍了两种处理方式:写等待和读等待。写等待通过提交等待来消除不确定性,例如Spanner使用时间区间对象和辅助函数来控制时间误差,实现了线性一致性。而读等待则由CockroachDB代表,通过重启读操作的事务来获取更晚的时间戳,以跳过不确定时间窗口,解决了读操作与已提交事务间隔小于设置的时间误差的问题。两种方式各有特点,写等待能够保证线性一致性,而读等待则更加灵活,但可能需要经过多次重启。这些处理方式在不同分布式数据库中的应用,为读者提供了对分布式系统中隐蔽读写冲突处理的深入了解。文章还提出了思考题,探讨在什么情况下不用“等待”也能达到线性一致性或因果一致性。
《分布式数据库 30 讲》,新⼈⾸单¥59

全部留言(14)
- 最新
- 精选
- OliviaHu关于思考题,我想老师的问题已经透露出了答案。时间误差是由多个独立时间源造成的。那么,在“单时间源”的情况下,就能够保证线性或因果一致性。但是,受限于单点,可用性和集群部署范围大大受限。关于可用性,TiDB是通过落盘全局时钟+多个PD构成Raft组来解决。集群部署范围,对于绝大多数公司的应用场景来说,都用不到全球化部署。 PS: 老师,TrueTime拼错了。
作者回复: 回答的很好,说明那个知识掌握的很扎实,点赞。关于这道思考题,我在15讲还留了一个彩蛋,可以关注下^Q^。 拼写确实错了,谢谢指出,已经请编辑同学帮忙调整了。
2020-09-0638  _______Harvey凝枫😗有个点看了几遍还是没能理解清楚:这个写等待与读等待 与 具体的事务类型(读写)有关系么: Spanner的写等待只是针对写事务么,那读事务时怎么办? CockroachDB的读等待只是在遇到读事务的时候才进行,那写事务的时候不管吗?
_______Harvey凝枫😗有个点看了几遍还是没能理解清楚:这个写等待与读等待 与 具体的事务类型(读写)有关系么: Spanner的写等待只是针对写事务么,那读事务时怎么办? CockroachDB的读等待只是在遇到读事务的时候才进行,那写事务的时候不管吗?作者回复: 这个问题本质上是读写操作落入了一个时间置信区间,无法判断是否该读取已写入的数据。写等待是在写入时处理掉这个误差,读取时不再处理;而读等待则相反。
2020-09-0756 wy老师,请教一个问题,如果是判断读写冲突的话,根据文中举的例子,直接标记写事务是否完成不就好了吗?为什么要通过时间戳去判断呢?
wy老师,请教一个问题,如果是判断读写冲突的话,根据文中举的例子,直接标记写事务是否完成不就好了吗?为什么要通过时间戳去判断呢?作者回复: 一个最直接的理由就是数据库要支持时点快照查询。比如,在可重复读隔离级别下,在事务执行过程中任何两个时点,对目标表执行同样的SQL应该得到同样的结果,当然前提是事务本身没有修改目标表。
2021-01-141 幼儿编程教学请教老师。这个等待,是因为像上一篇文章中说的,因为操作了相同的数据,所以等待了呢?还是所有事务,不管是否操作相同数据,都要等待?如果不管内容,都要等待,那tps就有极限值了。 你在文章中说的,spanner,8ms,tps是125,就是同一块数据吧。所以,提交的时候,db还会校验,是否已有未提交的事务操作了相同的数据,是吧?
幼儿编程教学请教老师。这个等待,是因为像上一篇文章中说的,因为操作了相同的数据,所以等待了呢?还是所有事务,不管是否操作相同数据,都要等待?如果不管内容,都要等待,那tps就有极限值了。 你在文章中说的,spanner,8ms,tps是125,就是同一块数据吧。所以,提交的时候,db还会校验,是否已有未提交的事务操作了相同的数据,是吧?作者回复: 只有读写操作的间隔在全局时钟的误差范围内,才会引发等待。如果采用写等待方式,数据库就不会对读操作再做检验,反之亦然。
2020-11-131 贺读等待我很好理解,就是通过延迟以便能确定读到更新后的值。 但是写等待和我理解的不一样,我理解的是让写延迟提交,以便读取的事务确定能读到提交前的值,而不是提交后的值。 不知道我理解的哪里有问题?
贺读等待我很好理解,就是通过延迟以便能确定读到更新后的值。 但是写等待和我理解的不一样,我理解的是让写延迟提交,以便读取的事务确定能读到提交前的值,而不是提交后的值。 不知道我理解的哪里有问题?作者回复: 写等待是要确保一个写事务中所有持久化的数据在一条正确的时间线上,也就是保证它们的先后次序是无误的。在任何一点的读操作都不会影响这个处理过程
2020-11-033 扩散性百万咸面包理解了为什么普通读等待等一个误差就行,不理解Spanner要等2个。感觉老师这里还可以说的更详细点。 我的理解是,等的第一个误差是等所有预备时间戳都已经真正提交,第二个误差就是和之前介绍的一样。
扩散性百万咸面包理解了为什么普通读等待等一个误差就行,不理解Spanner要等2个。感觉老师这里还可以说的更详细点。 我的理解是,等的第一个误差是等所有预备时间戳都已经真正提交,第二个误差就是和之前介绍的一样。作者回复: 你的理解大体上是对的,第一个等待是因为所有参与者各自取写入时间戳,注意不是提交;而提交时间戳要确保大于任何一个写入时间戳。
2020-09-21- J老师写等待有个问题不能理解,文中写等待后TB是在S+E启动的,如果TB还是在S+X启动,且X<E,当么当时TA还没落盘,就读不到数据。和之前没有写等待的情况是一样的
作者回复: 没有写等待时,Ta写盘先于Tb发生,所以Tb有可能读到Ta写的数据,这点你可以再思考一下。这个有可能就是时钟误差的不确定性,它影响了数据一致性。而写等待带来了一个确定性的结果,保证了数据一致性。
2020-09-162 - myrfyspanner的e为什么是4ms呢?如果误差区间在±7ms,可靠的时间窗口就应该是14ms了 所以怎么理解这个误差呢?
作者回复: 4ms是Google官方给出的TrueTime的误差均值。后面的计算也都是基于均值的。
2020-09-082  武功不高跟谈恋爱一样,距离不一定产生美,但肯定容易引起误会……所以确定关系的两人尽量住的近点,同居最好,最大限度消除误会的可能😄2020-09-0834
武功不高跟谈恋爱一样,距离不一定产生美,但肯定容易引起误会……所以确定关系的两人尽量住的近点,同居最好,最大限度消除误会的可能😄2020-09-0834 叶东富commit-wait原理是事务T在S时刻提交写盘,但是暂时不汇报提交成功。等待e之后,再汇报提交成功,即S+e之后,T才结束。这种情况下,T之后的读,即S+e之后的读,能够确保读出S写入的结果,保证了线性一致性。 不是等待e之后再提交写盘,而是提交写盘后等待e再汇报事务T完成。2021-09-262
叶东富commit-wait原理是事务T在S时刻提交写盘,但是暂时不汇报提交成功。等待e之后,再汇报提交成功,即S+e之后,T才结束。这种情况下,T之后的读,即S+e之后的读,能够确保读出S写入的结果,保证了线性一致性。 不是等待e之后再提交写盘,而是提交写盘后等待e再汇报事务T完成。2021-09-262

