

11|隔离性:读写冲突时,快照是最好的办法吗?

该思维导图由 AI 生成,仅供参考
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

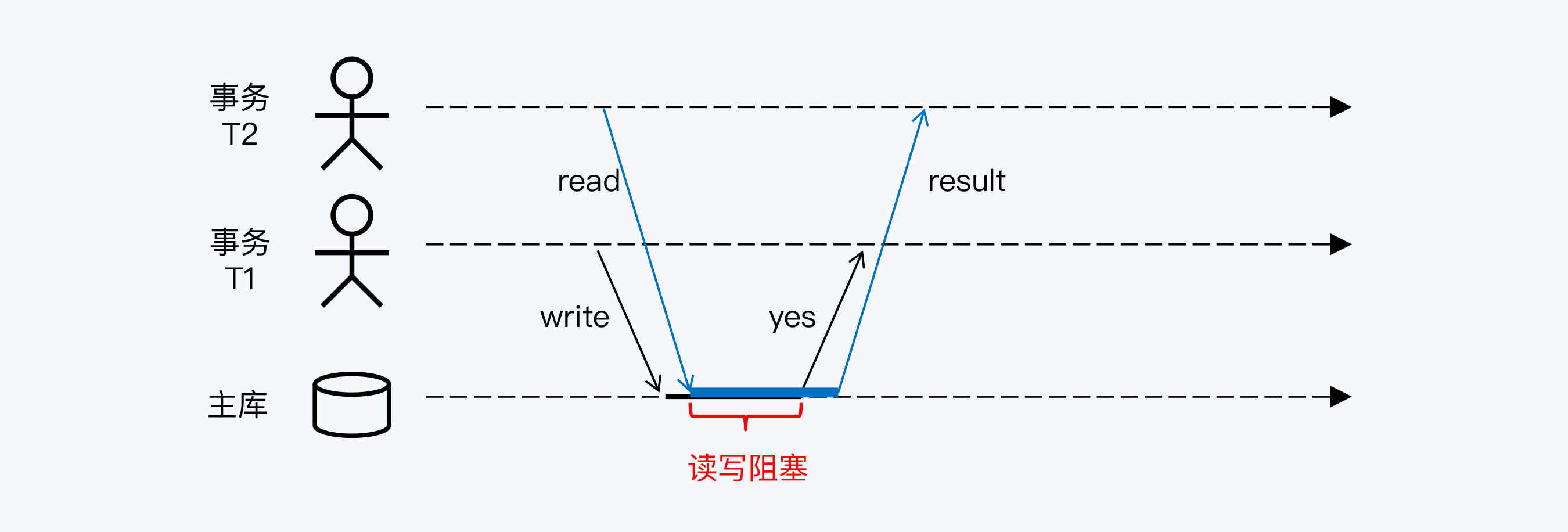
MVCC技术通过记录数据项历史版本的方式,提升系统应对多事务访问的并发处理能力。传统的锁机制在处理读写冲突时会导致事务阻塞,而MVCC技术则能避免这一问题。文章介绍了MVCC的存储方式,包括Append-Only、Delta和Time-Travel,并分析了它们的优缺点。此外,还阐述了MVCC在Read Committed隔离级别下的工作过程,以及在不同架构风格下的实现方式。通过MVCC技术,读者可以更好地理解并发控制问题,并了解不同存储方式的特点,以及MVCC在不同隔离级别下的工作原理。MVCC技术的应用可以提高系统的并发处理能力,避免事务阻塞,从而提升数据库性能和用户体验。在文章中还介绍了PGXC风格和NewSQL风格的分布式数据库如何处理读写冲突问题,以及时间误差对读写冲突处理的影响。整体而言,本文深入探讨了MVCC技术及其在不同数据库架构中的应用,为读者提供了全面的技术视角和思考。
《分布式数据库 30 讲》,新⼈⾸单¥59

全部留言(19)
- 最新
- 精选
 真名不叫黄金我认为 Spanner 的时钟误差会影响到事务吞吐量: 由于 Spanner 是 External Consistency 的,也就是可线性化(linearizable)的,那么只要两个事务需要读写的数据中有相交的数据,那么它俩的提交时间平均间隔至少是7ms,因为置信区间平均是7ms,那么在这个置信区间内是不能 commint 2 个读写了某个相同数据的事务的,否则就会打破可线性化,因为两个事务不一定分得出先后。因此 Spanner 在单位时间内的事务吞吐量是被时钟误差限制的,时钟误差越小,吞吐量越高,误差越大,吞吐量越低。 并且我也猜测,以下两种情况是的事务吞吐量是不被时钟误差影响的: 1. 如果两个事务操作的是完全不相交的数据,那么它们的 commit time 是可以重合的,因此时钟误差限制的仅仅是操作相交数据的事务的吞吐量。 2. 如果某个事务是只读事务,那么也不受限制,因为只读是基于快照的,其 commit timestamp 并没有意义,因此不需要与读写事务抢时钟。 受限于既有知识,猜测可能有误,仅仅是交流~
真名不叫黄金我认为 Spanner 的时钟误差会影响到事务吞吐量: 由于 Spanner 是 External Consistency 的,也就是可线性化(linearizable)的,那么只要两个事务需要读写的数据中有相交的数据,那么它俩的提交时间平均间隔至少是7ms,因为置信区间平均是7ms,那么在这个置信区间内是不能 commint 2 个读写了某个相同数据的事务的,否则就会打破可线性化,因为两个事务不一定分得出先后。因此 Spanner 在单位时间内的事务吞吐量是被时钟误差限制的,时钟误差越小,吞吐量越高,误差越大,吞吐量越低。 并且我也猜测,以下两种情况是的事务吞吐量是不被时钟误差影响的: 1. 如果两个事务操作的是完全不相交的数据,那么它们的 commit time 是可以重合的,因此时钟误差限制的仅仅是操作相交数据的事务的吞吐量。 2. 如果某个事务是只读事务,那么也不受限制,因为只读是基于快照的,其 commit timestamp 并没有意义,因此不需要与读写事务抢时钟。 受限于既有知识,猜测可能有误,仅仅是交流~作者回复: 说得很好,基本都正确,点赞。我在第12讲介绍了Spanner的完整处理过程,可以参考。
2020-09-02221 Clementtidb不是用raft实现了全局时钟么,为什么不可以用来作全局事务管理?
Clementtidb不是用raft实现了全局时钟么,为什么不可以用来作全局事务管理?作者回复: Raft通常用来做数据一致性,也就是多副本的一致性,而事务一致性,包括分布式事务,还是用2PC的各种优化。
2021-04-134 幼儿编程教学所以,tidb宣称的高并发,是基于不同的数据?修改同一块数据的话,其实是降的?因为有锁。。。
幼儿编程教学所以,tidb宣称的高并发,是基于不同的数据?修改同一块数据的话,其实是降的?因为有锁。。。作者回复: 多个会话要同时修改一个数据项,就必须有一套规则来协同,这就是并发控制机制。锁只是其中一种技术,基于锁也有多种处理方式,我们的专栏中展开介绍了这个问题。最后,这是所有数据库都要处理的问题,并不限于TiDB。
2020-11-083
 哎嗨,灰灰MVCC 有三类存储方式,一类是将历史版本直接存在数据表中的,称为 Append-Only,典型代表是 PostgreSQL。 ------ 请教老师一下,这个词append-only是专业术语吗?因为我觉得postgresql的mvcc不能说成append-only,这有可能是我对这个名词的理解有问题
哎嗨,灰灰MVCC 有三类存储方式,一类是将历史版本直接存在数据表中的,称为 Append-Only,典型代表是 PostgreSQL。 ------ 请教老师一下,这个词append-only是专业术语吗?因为我觉得postgresql的mvcc不能说成append-only,这有可能是我对这个名词的理解有问题作者回复: 这个词也不是很严格,算习惯用法吧,理解意思就好,就是表示不修改原有数据而做追加。比如,hbase中的数据修改也是这样。
2021-01-122 wy我理解pgxc没有在每个数据节点去维护一个活跃事务表,是因为会出现当某个全局事务在commit阶段时候,某个节点已经完成commit,但是整体还没完成的情况下,如果下个事务进来,会读取到已经commit完成节点的数据,但是读不到未完成commit节点的数据。这个时候就有问题了。
wy我理解pgxc没有在每个数据节点去维护一个活跃事务表,是因为会出现当某个全局事务在commit阶段时候,某个节点已经完成commit,但是整体还没完成的情况下,如果下个事务进来,会读取到已经commit完成节点的数据,但是读不到未完成commit节点的数据。这个时候就有问题了。作者回复: 是的,这就破坏了全局事务的隔离性。
2021-01-1321 扩散性百万咸面包感觉这一章有点故意混淆写操作和2PC。TiDB的事务应该只有提交的时候才涉及Prewrite/Commit,而不是每次写操作发生的时候
扩散性百万咸面包感觉这一章有点故意混淆写操作和2PC。TiDB的事务应该只有提交的时候才涉及Prewrite/Commit,而不是每次写操作发生的时候作者回复: 这里的写操作往往是指一个完整的写操作事务,不是事务中某个单独的update或insert语句。事实上,要满足事务ACID也不可能让每个写操作都执行独立的commit,我将这一点作为大家默认的前提了,看来还是要再说明一下。TiDB的2PC处理过程确实是在整个事务执行到commit语句时才会做实质操作,这点没问题。
2021-01-06 尘封tidb实现了mvcc,但是使用过程中确实存在读写冲突,一直没想明白,看完这一章内容,理解了。 老师,想问下,tidb既然存在读写冲突,那么select count一张大表时,这张表应该会阻塞写,但是感觉好像没阻塞,这是为什么? 我想表达的意思是:本文描述的读写冲突原因确实有道理,但是使用时又感觉没那么严重2021-02-223
尘封tidb实现了mvcc,但是使用过程中确实存在读写冲突,一直没想明白,看完这一章内容,理解了。 老师,想问下,tidb既然存在读写冲突,那么select count一张大表时,这张表应该会阻塞写,但是感觉好像没阻塞,这是为什么? 我想表达的意思是:本文描述的读写冲突原因确实有道理,但是使用时又感觉没那么严重2021-02-223- 陈阳按照 RC 隔离级别的要求,事务只能看到的两类数据: 1.当前事务的更新所产生的数据。 2.当前事务启动前,已经提交事务更新的数据。 这段描述好像不对吧, 在rc级别下, 当前事务启动后还未提交的过程中, 这时候有个事务开启,然后提交,对当前事务也是可见的2022-02-1712
 贺我看到tidb官方文档有说到它实现了可重复读隔离级别 https://www.bookstack.cn/read/pingcap-docs-cn/sql-transaction-isolation.md 如果TiDB 没有设计全局事务列表,它是不是用了别的方式来实现了可重复读的隔离级别;比如通过时间戳的比较来判断两个事务的先后关系。2020-11-1021
贺我看到tidb官方文档有说到它实现了可重复读隔离级别 https://www.bookstack.cn/read/pingcap-docs-cn/sql-transaction-isolation.md 如果TiDB 没有设计全局事务列表,它是不是用了别的方式来实现了可重复读的隔离级别;比如通过时间戳的比较来判断两个事务的先后关系。2020-11-1021- 扩散性百万咸面包老师是不是可以这么总结: 1. Append-Only的话,会把同一行的历史数据保存到一张表中,比如User里有个叫张三的,修改了它的值之后就会产生另一行张三,还是在同一个表中。 2. Delta的话,保存增量操作,这些操作存储到一个独立的磁盘空间中,而不是当前的数据表、 3. Time-Travel有点像redo/undo log,记录内存页在物理磁盘上修改前和后的变化2020-09-0721

