

开篇词|为什么要学习分布式数据库?

该思维导图由 AI 生成,仅供参考
分布式数据库可以解决什么问题?
抓住主线,高效学习分布式数据库
我是怎么设计这门课的?
关于我
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

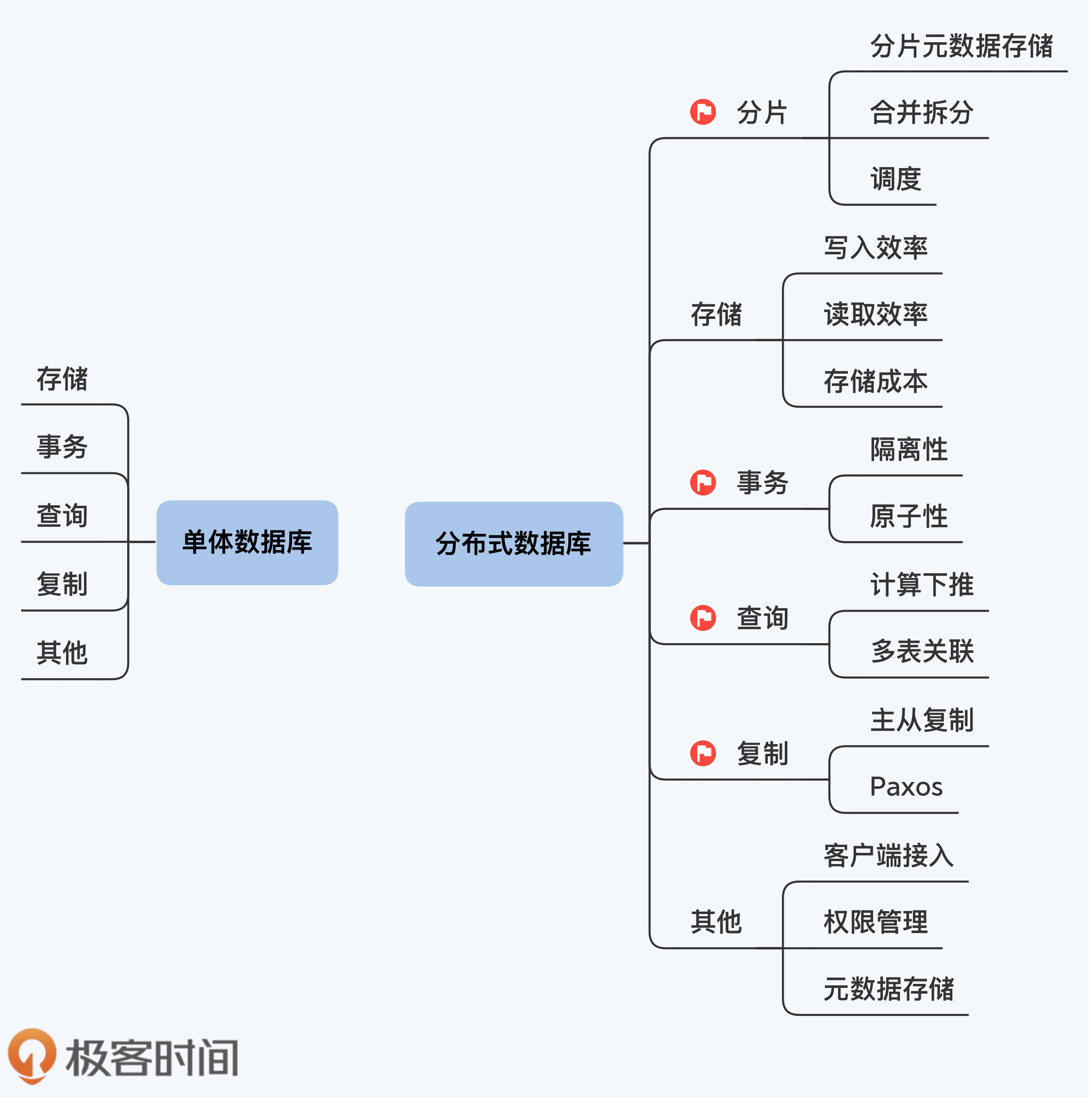
分布式数据库的重要性在于解决性能和可靠性问题,已成为技术潮流和新基建的一部分。国内公司和开源软件在这个领域崭露头角,供应商不再局限于国外商业巨头。文章介绍了一系列分布式数据库产品,如阿里巴巴的OceanBase、TiDB、GoldenDB等,以及其在互联网和金融领域的应用案例。学习分布式数据库的设计思想有助于提高架构设计水平和代码能力,是学术研究与工业实践的完美结合。核心内容包括存储、事务、查询、复制、分片等方面的知识点。课程设计思路为帮助读者低门槛地学习,只需具备一定的编程基础、数据库使用经验和对SQL运行优化的直观感受。作者具有超过15年的数据领域工作经验,曾服务于多家大型金融机构,推动了光大银行的大数据生态转型,并深度参与了分布式数据库选型工作。希望通过课程带领读者开启一场与大师的对话之旅,鼓励读者分享课程并留言互相交流。
2020-08-1079人觉得很赞给文章提建议
《分布式数据库 30 讲》,新⼈⾸单¥59

全部留言(23)
- 最新
- 精选
 yeyuliunian赞。 有个问题请教一下: 在数据库选型上,分布式关系型数据库和云原生数据库比如polardb ,在这两者中选择需要考虑哪些方面.
yeyuliunian赞。 有个问题请教一下: 在数据库选型上,分布式关系型数据库和云原生数据库比如polardb ,在这两者中选择需要考虑哪些方面.作者回复: 你好,PolarDB与Aurora都属于云原生数据库,腾讯、华为也都推出了类似的产品。这类架构的特点是计算存储分离,计算节点垂直扩展,存储节点水平扩展。特别适合云厂商的商业模式,Aurora也取得了很大的商业成功。相比MySQL,PolarDB性能上有一定提升,但仍然存在是单点上限,写入可不扩展,备节点的读取有极短的延迟。但是,这类数据库一般不适合企业私有化部署。至于我们课程所说的分布式数据库是指什么,你可以继续学习01讲,相信会找到答案。
2020-08-10521
 长脖子树来一门如何从零实现一个简单的分布式数据库, 那就爽了 哈哈
长脖子树来一门如何从零实现一个简单的分布式数据库, 那就爽了 哈哈作者回复: 嗯,做一个系统的实现确实会让印象更深刻。其实,像MIT6.824就会安排一些实验,例如Raft协议,但是门槛有些高,不一定适合多数同学。也许我们以后可以搞个简单的原型系统开发,带大家走一遍。
2020-08-11419 Geek_lucky_brian我们团队开发的GoldenDB上榜了,开心,感谢老师的认可
Geek_lucky_brian我们团队开发的GoldenDB上榜了,开心,感谢老师的认可作者回复: 欢迎GoldenDB的同学,我们一起讨论哈
2020-08-21212 龙海峰前几天同行交流,梳理关于数据复制/主备切换场景涉及到考虑的问题: 一:事前 1、如何做好监控?(如何监控主库异常?如何监控数据延迟?) 2、如何做好演练?(一主一从如何做演练切换?一主多从做演练?自动切换还是手动切?) 3、如何校验主备数据一致性,完整性? 二:事中 1、出了事故的最重要的事情是什么?体现什么核心素质? 2、如何切换?(自动与手动分别如何决策实施?场景与优缺点是什么?) 3、如何缩短处理事故时间?还有没有更快更合理的办法? 三:事后 1、复盘事故 2、修复问题 这是个大课题,不只是技术,更有方法论、组织结构、业务形态的共同保障结果,很期待后面能吸收更多关于这方面的分享。
龙海峰前几天同行交流,梳理关于数据复制/主备切换场景涉及到考虑的问题: 一:事前 1、如何做好监控?(如何监控主库异常?如何监控数据延迟?) 2、如何做好演练?(一主一从如何做演练切换?一主多从做演练?自动切换还是手动切?) 3、如何校验主备数据一致性,完整性? 二:事中 1、出了事故的最重要的事情是什么?体现什么核心素质? 2、如何切换?(自动与手动分别如何决策实施?场景与优缺点是什么?) 3、如何缩短处理事故时间?还有没有更快更合理的办法? 三:事后 1、复盘事故 2、修复问题 这是个大课题,不只是技术,更有方法论、组织结构、业务形态的共同保障结果,很期待后面能吸收更多关于这方面的分享。作者回复: 非常同意你的观点,系统的监控、演练和处置确实是个大问题。金融行业历来也是非常重视系统的平稳运行的。其实,分布式数据库的技术发展也是朝着简化人工操作的方向去的,降低人为因素的影响,毕竟很多时候人就是风险的来源。类似的技术,包括多副本的自动选主切换,机房级别的容灾等。但是,因为分布式架构固有的复杂性,整个运维体系肯定要做出不少调整,另外还需要一些辅助工具、周边生态的跟进。我在第24讲会和大家探讨一下部署及运行方面的话题。最后我想说,作为一个技术人员,我们既要能够结硬寨打呆仗,啃硬骨头,也要勇于接受改变,尝试创新,力争更巧妙和优雅的解决问题。
2020-08-157 神经旷野舞者为什么流行造轮子,都改进一个开源库不是更节约资源吗
神经旷野舞者为什么流行造轮子,都改进一个开源库不是更节约资源吗作者回复: 很多开源项目背后都有商业公司主导,有各自的利益诉求。只靠情怀做项目,多数走不远。
2020-10-106 南国复制部分不仅仅是Paxos可以做到,Raft,ZAB,Bully这类共识算法都可以实现呀。还有不仅仅是主从复制可以用,有时链式复制也是一种好的方法。很期待后面课程中的内容,作者加油!
南国复制部分不仅仅是Paxos可以做到,Raft,ZAB,Bully这类共识算法都可以实现呀。还有不仅仅是主从复制可以用,有时链式复制也是一种好的方法。很期待后面课程中的内容,作者加油!作者回复: 你好,Paxos是指代了这类共识算法,实际工程实现中采用Raft的更多些
2020-08-1325 wylvan老师能否提供一些一手资料的链接或者名字作为知识补充
wylvan老师能否提供一些一手资料的链接或者名字作为知识补充作者回复: 你好,在每一讲的末尾有注明相关论文和其他学习资料。
2020-09-221 wangweiping课程来的真及时,正好要了解这方面的知识
wangweiping课程来的真及时,正好要了解这方面的知识作者回复: 欢迎一起讨论:)
2020-08-111 张运康想请教下现在要求国产化,分布式数据库现在主流的国产DB能够很好的做到sql语句兼容吗比如TIDB,会不会出现写的稍微复杂的sql语句就不支持的情况呢?
张运康想请教下现在要求国产化,分布式数据库现在主流的国产DB能够很好的做到sql语句兼容吗比如TIDB,会不会出现写的稍微复杂的sql语句就不支持的情况呢?作者回复: 这位同学台多虑了,复杂SQL的能力通常都是具备的,兼容性方面,通常对开源产品兼容更好,比如MySQL/PostgreSQL。
2022-06-16归属地:北京 征服天堂马上入职中兴研发GoldenDB组,对数据库挺感兴趣的,希望以后可以转DBA。
征服天堂马上入职中兴研发GoldenDB组,对数据库挺感兴趣的,希望以后可以转DBA。作者回复: 加油
2021-04-292

