

36 | HTTPS:让数据传输更安全

该思维导图由 AI 生成,仅供参考
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

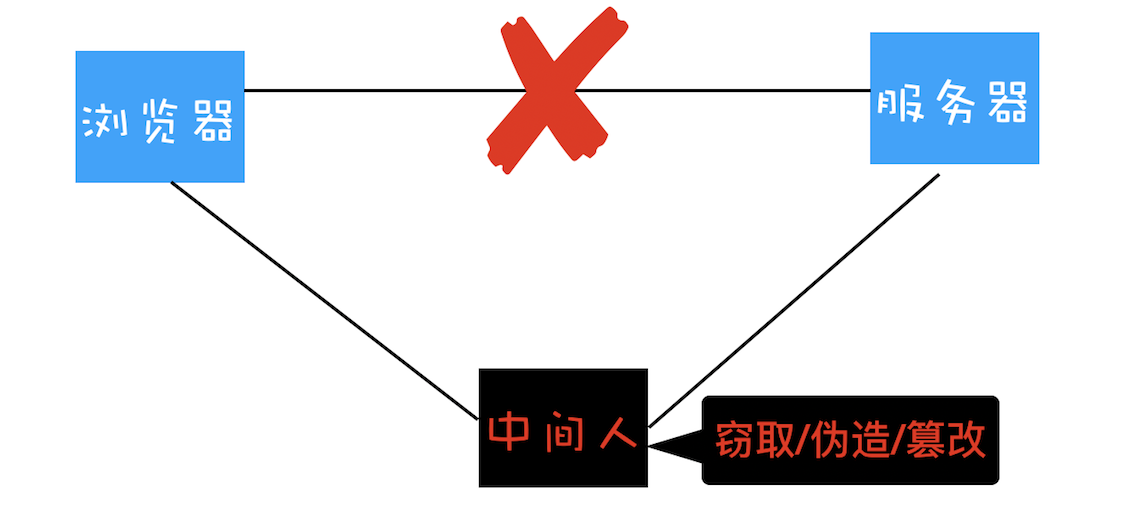
HTTPS协议的发展历程和技术原理是本文的重点。文章首先指出了HTTP明文传输的安全隐患,引出了中间人攻击的问题。随后详细介绍了HTTPS的工作原理,包括使用对称加密和非对称加密的不同版本。通过对称加密、非对称加密和混合加密的讲解,读者可以了解到HTTPS如何在保证数据传输安全的同时提高效率。文章以图文并茂的方式生动展示了HTTPS协议的演进过程,使读者对HTTPS的技术特点有了更深入的了解。 在HTTPS的发展过程中,通过引入数字证书,实现了服务器的身份认证功能,从而防止了黑客的欺骗。数字证书的申请和验证过程也得到了详细的解释,包括向CA申请证书的流程和浏览器如何验证数字证书的过程。最后,文章鼓励读者亲手搭建一个HTTPS的站点,并提供了免费证书申请的链接。 总之,HTTPS协议通过不断的改进和完善,解决了HTTP明文传输的安全问题,保证了数据传输的安全性和可靠性。同时,文章还留下了思考时间,要求读者结合前文和本文,总结HTTPS的握手过程,为读者提供了进一步思考和学习的机会。
《浏览器工作原理与实践》,新⼈⾸单¥59

全部留言(55)
- 最新
- 精选
 3Spiders我有一个地方不是很理解。CA的公钥,浏览器是怎么拿到的。是浏览器第一次请求服务器的时候,CA机构给浏览器的吗?求大神或者老师解答
3Spiders我有一个地方不是很理解。CA的公钥,浏览器是怎么拿到的。是浏览器第一次请求服务器的时候,CA机构给浏览器的吗?求大神或者老师解答作者回复: 我们先从证书类型开始: 我们知道CA是一个机构,它的职责是给一些公司或者个人颁发数字证书,在颁发证书之前,有一个重要的环节,就是审核申请者所提交资料的合法性和合规性。 不过申请者的类型有很多: 如果申请者是个人,CA只需要审核所域名的所有权就行了,审核域名所有权有很多中方法,在常用的方法是让申请者在域名上放一个文件,然后CA验证该文件是否存在,即可证明该域名是否是申请者的。我们把这类数字证书称为DV,审核这种个人域名信息是最简单的,因此CA收取的费用也是最低的,有些CA甚至免费为个人颁发数字证书。 如果申请者是普通公司,那么CA除了验证域名的所有权之外,还需要验证公司公司的合法性,这类证书通常称为OV。由于需要验证公司的信息,所有需要额外的资料,而且审核过程也更加复杂,申请OV证书的价格也更高,主要是由于验证公司的合法性是需要人工成本的。 如果申请者是一些金融机构、银行、电商平台等,所以还需额外的要验证一些经营资质是否合法合规,这类证书称为EV。申请EV的价格非常高,甚至达到好几万一年,因为需要人工验证更多的内容。 好了,我们了解了证书有很多种不同的类型,DV这种就可以自动审核,不过OV、EV这种类型的证书就需要人工验证了,而每个地方的验证方式又可能不同,比如你是一家美国本地的CA公司,要给中国的一些金融公司发放数字证书,这过程种验证证书就会遇到问题,因此就需要本地的CA机构,他们验证会更加容易。 因此,就全球就有很多家CA机构,然后就出现了一个问题,这些CA是怎么证明它自己是安全的?如果一个恶意的公司也成立了一个CA机构,然后给自己颁发证书,那么这就非常危险了,因此我们必须还要实现一个机制,让CA证明它自己是安全无公害的。 这就涉及到数字证书链了。 要讲数字证书链,就要了解我们的CA机构也是分两种类型的,中间CA(Intermediates CAs)和根CA(Root CAs),通常申请者都是向中间CA去申请证书的,而根CA作用就是给中间CA做认证,通常,一个根CA会认证很多中间的CA,而这些中间CA又可以去认证其它的中间CA。 比如你可以在Chrome上打开极客时间的官网,然后点击地址栏前面的那把小锁,你就可以看到*.geekbang,org的证书是由中间CA GeoTrust RSA CA2018颁发的,而中间CA GeoTrust RSA CA2018又是由根CA DigiCert Global Root CA颁发的,所以这个证书链就是:*.geekbang,org--->GeoTrust RSA CA2018-->DigiCert Global Root CA。 因此浏览器验证极客时间的证书时,会先验证*.geekbang,org的证书,如果合法在验证中间CA的证书,如果中间CA也是合法的,那么浏览器会继续验证这个中间CA的根证书。 这时候问题又来了,怎么证明根证书是合法的? 浏览器的做法很简单,它会查找系统的根证书,如果这个根证书在操作系统里面,那么浏览器就认为这个根证书是合法的,如果验证的根证书不在操作系统里面,那么就是不合法的。 而操作系统里面这些内置的根证书也不是随便内置的,这些根CA都是通过WebTrust国际安全审计认证。 那么什么又是WebTrust认证? WebTrust(网络信任)认证是电子认证服务行业中唯一的国际性认证标准,主要对互联网服务商的系统及业务运作的商业惯例和信息隐私,交易完整性和安全性。WebTrust认证是各大主流的浏览器、微软等大厂商支持的标准,是规范CA机构运营服务的国际标准。在浏览器厂商根证书植入项目中,必要的条件就是要通过WebTrust认证,才能实现浏览器与数字证书的无缝嵌入。 目前通过WebTrust认证的根CA有 Comodo,geotrust,rapidssl,symantec,thawte,digicert等。也就是说,这些根CA机构的根证书都内置在个大操作系统中,只要能从数字证书链往上追溯到这几个根证书,浏览器会认为使用者的证书是合法的。 这也同时回答了你上面的问题。
2019-10-2613159 mfist1. 首先是tcp的三次握手建立连接 2. client发送random1+支持的加密算法集合(clientHello) 3. server收到信息,返回选择一个加密算法+random2(serverHello)+ 证书+ 确认 4. clent验证证书有效性,并用random1+random2生成pre-master通过服务器公钥加密 发送给server 5. server收到premaster,根据约定的加密算法对random1+random2+premaster(解密)生成master-secret,然后发送预定成功 6. client收到生成同样的master-secert,对称加密秘钥传输完毕 今日总结 浏览器安全主要包括页面安全、系统安全、传输安全三个部分。https主要保证传输过程的安全,从防止中间人窃取修改伪造的角度循序渐进的介绍了https的实现过程。 1. 对称加密传输(协商秘钥的过程容易被窃取) 2. 非对称加密传输(服务端用私钥加密的内容,可以通过它的公钥进行解密) 3. 非对称加密交换秘钥、对称加密传输内容(DNS劫持 如何保证服务器是可信的) 4. 引入CA权威机构保证服务器可信性。 数字证书的申请过程:服务器生成一对公钥和私钥,私钥自己保存,通过公钥+企业+网站信息去CA机构申请证书。CA机构通过全方位的验证给这个网站颁发证书,证书内容包括企业信息、证书有效期、证书编号,以及自己私钥加密上述信息的摘要、网站的公钥。服务器就获得了CA的认证。 浏览器认证证书过程:浏览器从服务器拿到网站的证书,通过CA的公钥解密证书信息的摘要跟使用摘要算法计算企业信息等的摘要对比,如果一致则证明证书有效。如果证书CA是可靠的呢,通过给CA颁发证书的根CA验证,通常操作系统中包括顶级CA证书(它们自己给自己签名称为自签名证书,我们自己生成证书也是自签名证书 只是它不是操作系统内置的)
mfist1. 首先是tcp的三次握手建立连接 2. client发送random1+支持的加密算法集合(clientHello) 3. server收到信息,返回选择一个加密算法+random2(serverHello)+ 证书+ 确认 4. clent验证证书有效性,并用random1+random2生成pre-master通过服务器公钥加密 发送给server 5. server收到premaster,根据约定的加密算法对random1+random2+premaster(解密)生成master-secret,然后发送预定成功 6. client收到生成同样的master-secert,对称加密秘钥传输完毕 今日总结 浏览器安全主要包括页面安全、系统安全、传输安全三个部分。https主要保证传输过程的安全,从防止中间人窃取修改伪造的角度循序渐进的介绍了https的实现过程。 1. 对称加密传输(协商秘钥的过程容易被窃取) 2. 非对称加密传输(服务端用私钥加密的内容,可以通过它的公钥进行解密) 3. 非对称加密交换秘钥、对称加密传输内容(DNS劫持 如何保证服务器是可信的) 4. 引入CA权威机构保证服务器可信性。 数字证书的申请过程:服务器生成一对公钥和私钥,私钥自己保存,通过公钥+企业+网站信息去CA机构申请证书。CA机构通过全方位的验证给这个网站颁发证书,证书内容包括企业信息、证书有效期、证书编号,以及自己私钥加密上述信息的摘要、网站的公钥。服务器就获得了CA的认证。 浏览器认证证书过程:浏览器从服务器拿到网站的证书,通过CA的公钥解密证书信息的摘要跟使用摘要算法计算企业信息等的摘要对比,如果一致则证明证书有效。如果证书CA是可靠的呢,通过给CA颁发证书的根CA验证,通常操作系统中包括顶级CA证书(它们自己给自己签名称为自签名证书,我们自己生成证书也是自签名证书 只是它不是操作系统内置的)作者回复: 这可以做标准参考答案了
2019-10-26973 GY问了很多次,一直没有回复,想请问下老师,专栏中一直说的主线程和渲染引擎线程、js引擎线程之间有什么关系,渲染引擎和js引擎互斥,两个引擎是都运行在主线程中吗,这个主线程到底是什么啊?
GY问了很多次,一直没有回复,想请问下老师,专栏中一直说的主线程和渲染引擎线程、js引擎线程之间有什么关系,渲染引擎和js引擎互斥,两个引擎是都运行在主线程中吗,这个主线程到底是什么啊?作者回复: 首先,渲染进程有个主线程,DOM解析,样式计算,执行JavaScript,执行垃圾回收等等操作都是在这个主线程上执行的, 没有所谓的渲染引擎线程和js引擎线程的概念,你可以把渲染和执行JavaScript是一种功能,如果要执行这些功能的话,需要在一个线程上执行,在chrome中,他们都是执行在渲染进程的主线程上。 正是因为他们都是执行在同一个线程之上的,所以同一时刻只能运行一个功能,也就是你说的互斥。 不知道这样解释你明白没有,如果还有疑惑欢迎继续提问。
2019-10-28232 蓝配鸡HTTPS握手过程: 1. 建立TCP链接 2. 获取服务器证书并检查证实真实性 3. 通过证书里服务器的公钥发送自己的公钥以及协商对称加密需要的信息给服务器. 4. 服务器返回协商结果 5. 双方生成对称密钥 6. 开始通信 第二步证明了服务器就是服务器, 其实已经可以愉快的沟通了(通过非对称加密), 后面交换对称加密信息的步骤其实可以算是优化吧? 我记得是TLS1.2才引入的? 有个问题: 根证书是信任的根源, 老师说它是被系统内核管理的并且自签名,那如果系统内核被黑了岂不是黑客就可以作假了? 根证书是不是就是一个躺在内核中(用户无法访问到)的文件? 有没有什么机制或者技术去发现根证书是假的? 还是说等到用户出现损失之后系统级别的更新来去除对这个根CA的信任? 给李兵老师: 不知不觉最后一节了, 本人由于工作原因对前端以及chrome需要加深理解。 老师的专栏每天上下班的时候都会听,反复的听。 不管是内容,还是文字结构梳理,都不难发现老师花了大量的精力和时间去思考如何讲透某一个知识点。 老师对知识的颗粒度把握的很好, 既不是泛泛而谈, 又不会太细以至于难以理解。 使得我对前端,以及chrome产生了浓厚的兴趣! 虽然现在整个前端, 或者chrome浏览器对我来说可能还是打着码的, 但相比之前, 我相信我已经看到一个大致的轮廓了, 今后一定会更花时间在前端领域中, 把这些码去掉,成为前端大神! 表达能力可能有限...总而言之, 谢谢老师🙏!虽然这是最后一篇了, 但是如果老师想做几篇加餐,我想同学们也是很欢迎的 😂
蓝配鸡HTTPS握手过程: 1. 建立TCP链接 2. 获取服务器证书并检查证实真实性 3. 通过证书里服务器的公钥发送自己的公钥以及协商对称加密需要的信息给服务器. 4. 服务器返回协商结果 5. 双方生成对称密钥 6. 开始通信 第二步证明了服务器就是服务器, 其实已经可以愉快的沟通了(通过非对称加密), 后面交换对称加密信息的步骤其实可以算是优化吧? 我记得是TLS1.2才引入的? 有个问题: 根证书是信任的根源, 老师说它是被系统内核管理的并且自签名,那如果系统内核被黑了岂不是黑客就可以作假了? 根证书是不是就是一个躺在内核中(用户无法访问到)的文件? 有没有什么机制或者技术去发现根证书是假的? 还是说等到用户出现损失之后系统级别的更新来去除对这个根CA的信任? 给李兵老师: 不知不觉最后一节了, 本人由于工作原因对前端以及chrome需要加深理解。 老师的专栏每天上下班的时候都会听,反复的听。 不管是内容,还是文字结构梳理,都不难发现老师花了大量的精力和时间去思考如何讲透某一个知识点。 老师对知识的颗粒度把握的很好, 既不是泛泛而谈, 又不会太细以至于难以理解。 使得我对前端,以及chrome产生了浓厚的兴趣! 虽然现在整个前端, 或者chrome浏览器对我来说可能还是打着码的, 但相比之前, 我相信我已经看到一个大致的轮廓了, 今后一定会更花时间在前端领域中, 把这些码去掉,成为前端大神! 表达能力可能有限...总而言之, 谢谢老师🙏!虽然这是最后一篇了, 但是如果老师想做几篇加餐,我想同学们也是很欢迎的 😂作者回复: 只要拿到系统权限,就能随意安装根证书,这种我见过很多! 之前百度升级到https最后,很多劫持就是采用这种方式来干的,在操作系统安装假的根证书,然后劫持整个站点! 所以让黑客在你电脑上安装了根证书,https也会变得不安全了! 最后感谢你一路陪伴和提的问题,也让我能更好的改进专栏
2019-10-2623- 3Spiders这篇文章是我看过最好的https总结的文章,拆解很到位。
作者回复: 🤝
2019-10-2612 - 早起不吃虫老师好,您前面说随机数加密算法是公开透明的,后面又说利用 client-random 和 service-random 计算出来 pre-master,然后利用公钥对 pre-master 加密,并向服务器发送加密后的数据,。 。这样的话,premaster不是也是可以计算出来了吗,有必要用公钥加密吗?
作者回复: 不好意思,这个我写错了,这个pre-master是随机生成的,没有用到client-random和service-random。 内容已经改正了
2019-10-2649  大前端洞见>虽然浏览器端可以使用公钥来加密,但是服务器端只能采用私钥来加密,私钥加密只有公钥能解密,但黑客也是可以获取得到公钥的,这样就不能保证服务器端数据的安全了。 老师,这里不是很明白。浏览器使用公钥加密,服务器端不是用私钥解密吗?怎么你这里说“服务器端只能采用私钥来加密”呢?
大前端洞见>虽然浏览器端可以使用公钥来加密,但是服务器端只能采用私钥来加密,私钥加密只有公钥能解密,但黑客也是可以获取得到公钥的,这样就不能保证服务器端数据的安全了。 老师,这里不是很明白。浏览器使用公钥加密,服务器端不是用私钥解密吗?怎么你这里说“服务器端只能采用私钥来加密”呢?作者回复: 这个要分开两部分来看: 1:浏览器发送数据给服务器 2:服务器发送数据给浏览器 浏览器发送数据给服务器时,是采用服务器发送给浏览器的公钥加密的,然后服务器可以拿它的私钥来解密。这个我们理解没问题的! 如果是服务器发送数据给浏览器,由于浏览器只有服务器的公钥,所以服务器只能用它的私钥来加密数据,然后将加密的数据发送给浏览器,浏览器使用公钥匙解密! 但是这个公钥是公开的,所以服务器发送给浏览器的数据也就没有安全性可言了! 不知道这样解释你能明白吗?
2019-10-2637
 Ming请问老师: (1)非对称加密部分,当浏览器的公钥给了服务器,服务器不就可以给浏览器安全传输数据了吗? (2)混合加密部分,“浏览器保存公钥,并利用 client-random 和 service-random 计算出来 pre-master”,经揣摩,pre-master是生成对称加密密钥的重要且唯一安全的参数,但是在浏览器端,计算出来的pre-master是安全的吗?因为考虑到client-random 和 service-random是可以被拦截的,是否pre-master可以在传输前就被知晓了? (3)混合加密方式有个漏洞,这种情况是服务器向浏览器发送公钥过程中被伪装篡改,导致浏览器不是与真正的“对话人”即服务器进行对话,因而出现了数字证书对公钥的身份进行公证。
Ming请问老师: (1)非对称加密部分,当浏览器的公钥给了服务器,服务器不就可以给浏览器安全传输数据了吗? (2)混合加密部分,“浏览器保存公钥,并利用 client-random 和 service-random 计算出来 pre-master”,经揣摩,pre-master是生成对称加密密钥的重要且唯一安全的参数,但是在浏览器端,计算出来的pre-master是安全的吗?因为考虑到client-random 和 service-random是可以被拦截的,是否pre-master可以在传输前就被知晓了? (3)混合加密方式有个漏洞,这种情况是服务器向浏览器发送公钥过程中被伪装篡改,导致浏览器不是与真正的“对话人”即服务器进行对话,因而出现了数字证书对公钥的身份进行公证。作者回复: 第一个问题: 通常浏览器是没有自己的证书的,也没有自己的公钥和私钥。 不过有一种情况,那就是服务器需要验证浏览器的身份,比如银行转账啥的,这种情况下,银行会给浏览器一个证书,通常是U盘的形式提供的,这种叫双向认证,不过不常见。 2:浏览器端计算pre-master是相对安全的,想攻破难度是非常高的,因为要攻击浏览器系统,做各种逆向,不是简单地截获下网络数据就行了。 3:公钥是和数字证书一起发动的,如果公钥改了,那么数字证书就会验证失败的,验证失败了浏览器也就不会继续下一步的请求了。
2019-10-264 Angus这是我在极客时间认真看完并总结的第一篇专栏,并且在最后将自己的网站升级了HTTPS。整体来说受益匪浅,后续还会反复查阅的,感谢!
Angus这是我在极客时间认真看完并总结的第一篇专栏,并且在最后将自己的网站升级了HTTPS。整体来说受益匪浅,后续还会反复查阅的,感谢!作者回复: 🤝
2019-10-282 填期待大佬以后有机会继续发布这么高质量的系列,很感谢这段时间的输出
填期待大佬以后有机会继续发布这么高质量的系列,很感谢这段时间的输出作者回复: 🤝
2019-10-262