

04 | 导航流程:从输入URL到页面展示,这中间发生了什么?

该思维导图由 AI 生成,仅供参考
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

本文深入探讨了浏览器导航过程中的关键阶段,包括URL请求过程、重定向、响应数据类型处理、渲染进程准备和文档提交。通过详细分析用户输入URL后的页面加载状态,读者可以了解浏览器多进程架构、导航过程中的关键阶段,以及浏览器如何处理用户输入的URL请求。文章内容涵盖了网络、操作系统和Web等多方面的知识,适合技术人员深入学习和了解。 在文章中,作者以技术细节为主线,通过实例和命令行展示,生动地解释了浏览器导航过程中的重要环节,使读者能够快速了解浏览器导航的技术特点。从服务器控制浏览器行为到浏览器导航流程的重要性,本文为读者呈现了浏览器工作原理的精华。 此外,文章还提出了思考问题,引导读者思考并总结自己对于浏览器导航过程的理解,为读者提供了更深入的思考和学习空间。 总之,本文内容丰富,技术性强,适合对浏览器工作原理感兴趣的读者阅读学习。
《浏览器工作原理与实践》,新⼈⾸单¥59

全部留言(146)
- 最新
- 精选
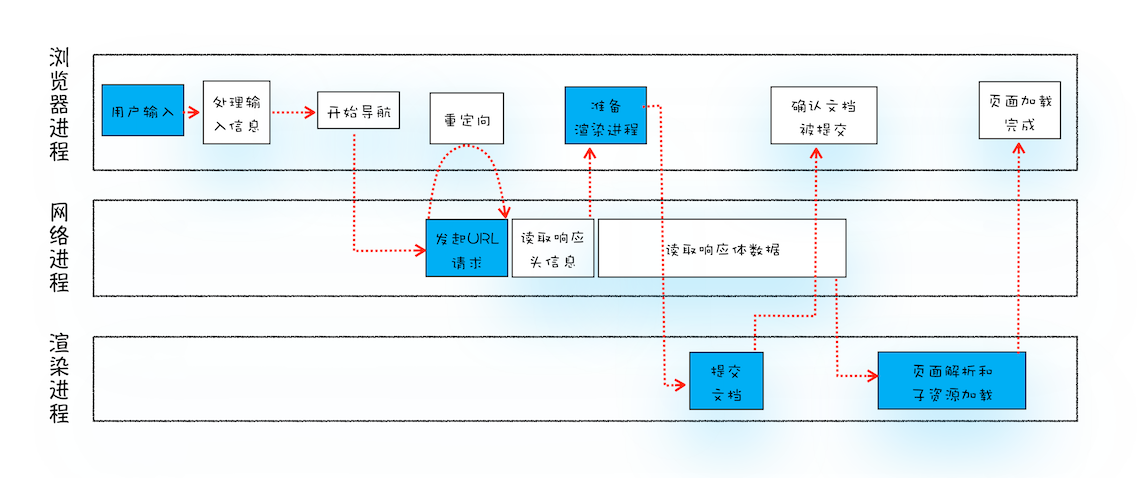
 ytd结合老师的讲义,自己总结了下,不考虑用户输入搜索关键字的情况: 1,用户输入url并回车 2,浏览器进程检查url,组装协议,构成完整的url 3,浏览器进程通过进程间通信(IPC)把url请求发送给网络进程 4,网络进程接收到url请求后检查本地缓存是否缓存了该请求资源,如果有则将该资源返回给浏览器进程 5,如果没有,网络进程向web服务器发起http请求(网络请求),请求流程如下: 5.1 进行DNS解析,获取服务器ip地址,端口(端口是通过dns解析获取的吗?这里有个疑问) 5.2 利用ip地址和服务器建立tcp连接 5.3 构建请求头信息 5.4 发送请求头信息 5.5 服务器响应后,网络进程接收响应头和响应信息,并解析响应内容 6,网络进程解析响应流程; 6.1 检查状态码,如果是301/302,则需要重定向,从Location自动中读取地址,重新进行第4步 (301/302跳转也会读取本地缓存吗?这里有个疑问),如果是200,则继续处理请求。 6.2 200响应处理: 检查响应类型Content-Type,如果是字节流类型,则将该请求提交给下载管理器,该导航流程结束,不再进行 后续的渲染,如果是html则通知浏览器进程准备渲染进程准备进行渲染。 7,准备渲染进程 7.1 浏览器进程检查当前url是否和之前打开的渲染进程根域名是否相同,如果相同,则复用原来的进程,如果不同,则开启新的渲染进程 8. 传输数据、更新状态 8.1 渲染进程准备好后,浏览器向渲染进程发起“提交文档”的消息,渲染进程接收到消息和网络进程建立传输数据的“管道” 8.2 渲染进程接收完数据后,向浏览器发送“确认提交” 8.3 浏览器进程接收到确认消息后更新浏览器界面状态:安全、地址栏url、前进后退的历史状态、更新web页面。
ytd结合老师的讲义,自己总结了下,不考虑用户输入搜索关键字的情况: 1,用户输入url并回车 2,浏览器进程检查url,组装协议,构成完整的url 3,浏览器进程通过进程间通信(IPC)把url请求发送给网络进程 4,网络进程接收到url请求后检查本地缓存是否缓存了该请求资源,如果有则将该资源返回给浏览器进程 5,如果没有,网络进程向web服务器发起http请求(网络请求),请求流程如下: 5.1 进行DNS解析,获取服务器ip地址,端口(端口是通过dns解析获取的吗?这里有个疑问) 5.2 利用ip地址和服务器建立tcp连接 5.3 构建请求头信息 5.4 发送请求头信息 5.5 服务器响应后,网络进程接收响应头和响应信息,并解析响应内容 6,网络进程解析响应流程; 6.1 检查状态码,如果是301/302,则需要重定向,从Location自动中读取地址,重新进行第4步 (301/302跳转也会读取本地缓存吗?这里有个疑问),如果是200,则继续处理请求。 6.2 200响应处理: 检查响应类型Content-Type,如果是字节流类型,则将该请求提交给下载管理器,该导航流程结束,不再进行 后续的渲染,如果是html则通知浏览器进程准备渲染进程准备进行渲染。 7,准备渲染进程 7.1 浏览器进程检查当前url是否和之前打开的渲染进程根域名是否相同,如果相同,则复用原来的进程,如果不同,则开启新的渲染进程 8. 传输数据、更新状态 8.1 渲染进程准备好后,浏览器向渲染进程发起“提交文档”的消息,渲染进程接收到消息和网络进程建立传输数据的“管道” 8.2 渲染进程接收完数据后,向浏览器发送“确认提交” 8.3 浏览器进程接收到确认消息后更新浏览器界面状态:安全、地址栏url、前进后退的历史状态、更新web页面。作者回复: 赞的,回头补上05-06节所讲的渲染流程,整个过程就完整了
2019-08-1329369 羽蝶曲1. 用户输入URL,浏览器会根据用户输入的信息判断是搜索还是网址,如果是搜索内容,就将搜索内容+默认搜索引擎合成新的URL;如果用户输入的内容符合URL规则,浏览器就会根据URL协议,在这段内容上加上协议合成合法的URL 2. 用户输入完内容,按下回车键,浏览器导航栏显示loading状态,但是页面还是呈现前一个页面,这是因为新页面的响应数据还没有获得 3. 浏览器进程浏览器构建请求行信息,会通过进程间通信(IPC)将URL请求发送给网络进程 GET /index.html HTTP1.1 4. 网络进程获取到URL,先去本地缓存中查找是否有缓存文件,如果有,拦截请求,直接200返回;否则,进入网络请求过程 5. 网络进程请求DNS返回域名对应的IP和端口号,如果之前DNS数据缓存服务缓存过当前域名信息,就会直接返回缓存信息;否则,发起请求获取根据域名解析出来的IP和端口号,如果没有端口号,http默认80,https默认443。如果是https请求,还需要建立TLS连接。 6. Chrome 有个机制,同一个域名同时最多只能建立 6 个TCP 连接,如果在同一个域名下同时有 10 个请求发生,那么其中 4 个请求会进入排队等待状态,直至进行中的请求完成。如果当前请求数量少于6个,会直接建立TCP连接。 7. TCP三次握手建立连接,http请求加上TCP头部——包括源端口号、目的程序端口号和用于校验数据完整性的序号,向下传输 8. 网络层在数据包上加上IP头部——包括源IP地址和目的IP地址,继续向下传输到底层 9. 底层通过物理网络传输给目的服务器主机 10. 目的服务器主机网络层接收到数据包,解析出IP头部,识别出数据部分,将解开的数据包向上传输到传输层 11. 目的服务器主机传输层获取到数据包,解析出TCP头部,识别端口,将解开的数据包向上传输到应用层 12. 应用层HTTP解析请求头和请求体,如果需要重定向,HTTP直接返回HTTP响应数据的状态code301或者302,同时在请求头的Location字段中附上重定向地址,浏览器会根据code和Location进行重定向操作;如果不是重定向,首先服务器会根据 请求头中的If-None-Match 的值来判断请求的资源是否被更新,如果没有更新,就返回304状态码,相当于告诉浏览器之前的缓存还可以使用,就不返回新数据了;否则,返回新数据,200的状态码,并且如果想要浏览器缓存数据的话,就在相应头中加入字段: Cache-Control:Max-age=2000 响应数据又顺着应用层——传输层——网络层——网络层——传输层——应用层的顺序返回到网络进程 13. 数据传输完成,TCP四次挥手断开连接。如果,浏览器或者服务器在HTTP头部加上如下信息,TCP就一直保持连接。保持TCP连接可以省下下次需要建立连接的时间,提示资源加载速度 Connection:Keep-Alive 14. 网络进程将获取到的数据包进行解析,根据响应头中的Content-type来判断响应数据的类型,如果是字节流类型,就将该请求交给下载管理器,该导航流程结束,不再进行;如果是text/html类型,就通知浏览器进程获取到文档准备渲染 15. 浏览器进程获取到通知,根据当前页面B是否是从页面A打开的并且和页面A是否是同一个站点(根域名和协议一样就被认为是同一个站点),如果满足上述条件,就复用之前网页的进程,否则,新创建一个单独的渲染进程 16. 浏览器会发出“提交文档”的消息给渲染进程,渲染进程收到消息后,会和网络进程建立传输数据的“管道”,文档数据传输完成后,渲染进程会返回“确认提交”的消息给浏览器进程 17. 浏览器收到“确认提交”的消息后,会更新浏览器的页面状态,包括了安全状态、地址栏的 URL、前进后退的历史状态,并更新web页面,此时的web页面是空白页 18. 渲染进程对文档进行页面解析和子资源加载,HTML 通过HTM 解析器转成DOM Tree(二叉树类似结构的东西),CSS按照CSS 规则和CSS解释器转成CSSOM TREE,两个tree结合,形成render tree(不包含HTML的具体元素和元素要画的具体位置),通过Layout可以计算出每个元素具体的宽高颜色位置,结合起来,开始绘制,最后显示在屏幕中新页面显示出来
羽蝶曲1. 用户输入URL,浏览器会根据用户输入的信息判断是搜索还是网址,如果是搜索内容,就将搜索内容+默认搜索引擎合成新的URL;如果用户输入的内容符合URL规则,浏览器就会根据URL协议,在这段内容上加上协议合成合法的URL 2. 用户输入完内容,按下回车键,浏览器导航栏显示loading状态,但是页面还是呈现前一个页面,这是因为新页面的响应数据还没有获得 3. 浏览器进程浏览器构建请求行信息,会通过进程间通信(IPC)将URL请求发送给网络进程 GET /index.html HTTP1.1 4. 网络进程获取到URL,先去本地缓存中查找是否有缓存文件,如果有,拦截请求,直接200返回;否则,进入网络请求过程 5. 网络进程请求DNS返回域名对应的IP和端口号,如果之前DNS数据缓存服务缓存过当前域名信息,就会直接返回缓存信息;否则,发起请求获取根据域名解析出来的IP和端口号,如果没有端口号,http默认80,https默认443。如果是https请求,还需要建立TLS连接。 6. Chrome 有个机制,同一个域名同时最多只能建立 6 个TCP 连接,如果在同一个域名下同时有 10 个请求发生,那么其中 4 个请求会进入排队等待状态,直至进行中的请求完成。如果当前请求数量少于6个,会直接建立TCP连接。 7. TCP三次握手建立连接,http请求加上TCP头部——包括源端口号、目的程序端口号和用于校验数据完整性的序号,向下传输 8. 网络层在数据包上加上IP头部——包括源IP地址和目的IP地址,继续向下传输到底层 9. 底层通过物理网络传输给目的服务器主机 10. 目的服务器主机网络层接收到数据包,解析出IP头部,识别出数据部分,将解开的数据包向上传输到传输层 11. 目的服务器主机传输层获取到数据包,解析出TCP头部,识别端口,将解开的数据包向上传输到应用层 12. 应用层HTTP解析请求头和请求体,如果需要重定向,HTTP直接返回HTTP响应数据的状态code301或者302,同时在请求头的Location字段中附上重定向地址,浏览器会根据code和Location进行重定向操作;如果不是重定向,首先服务器会根据 请求头中的If-None-Match 的值来判断请求的资源是否被更新,如果没有更新,就返回304状态码,相当于告诉浏览器之前的缓存还可以使用,就不返回新数据了;否则,返回新数据,200的状态码,并且如果想要浏览器缓存数据的话,就在相应头中加入字段: Cache-Control:Max-age=2000 响应数据又顺着应用层——传输层——网络层——网络层——传输层——应用层的顺序返回到网络进程 13. 数据传输完成,TCP四次挥手断开连接。如果,浏览器或者服务器在HTTP头部加上如下信息,TCP就一直保持连接。保持TCP连接可以省下下次需要建立连接的时间,提示资源加载速度 Connection:Keep-Alive 14. 网络进程将获取到的数据包进行解析,根据响应头中的Content-type来判断响应数据的类型,如果是字节流类型,就将该请求交给下载管理器,该导航流程结束,不再进行;如果是text/html类型,就通知浏览器进程获取到文档准备渲染 15. 浏览器进程获取到通知,根据当前页面B是否是从页面A打开的并且和页面A是否是同一个站点(根域名和协议一样就被认为是同一个站点),如果满足上述条件,就复用之前网页的进程,否则,新创建一个单独的渲染进程 16. 浏览器会发出“提交文档”的消息给渲染进程,渲染进程收到消息后,会和网络进程建立传输数据的“管道”,文档数据传输完成后,渲染进程会返回“确认提交”的消息给浏览器进程 17. 浏览器收到“确认提交”的消息后,会更新浏览器的页面状态,包括了安全状态、地址栏的 URL、前进后退的历史状态,并更新web页面,此时的web页面是空白页 18. 渲染进程对文档进行页面解析和子资源加载,HTML 通过HTM 解析器转成DOM Tree(二叉树类似结构的东西),CSS按照CSS 规则和CSS解释器转成CSSOM TREE,两个tree结合,形成render tree(不包含HTML的具体元素和元素要画的具体位置),通过Layout可以计算出每个元素具体的宽高颜色位置,结合起来,开始绘制,最后显示在屏幕中新页面显示出来作者回复: 总结的很详细,用心了!
2019-08-1317229 芳华年月请问老师,https://linkmarket.aliyun.com内新开的页面都是新开一个渲染进程,能帮忙解释下吗
芳华年月请问老师,https://linkmarket.aliyun.com内新开的页面都是新开一个渲染进程,能帮忙解释下吗作者回复: 我看了下代码,因为连接里面使用了 rel="noopener noreferrer"这个属性。 这个涉及到安全了,要完整解释起来就话长了,我长话短说,先看阿里这个网站的连接是下面这种形式: <a target="_blank" rel="noopener noreferrer" class="hover" href="https://linkmarket.aliyun.com/hardware_store?spm=a2c3t.11219538.iot-navBar.62.4b5a51e7u2sXtw" data-spm-anchor-id="a2c3t.11219538.iot-navBar.62">硬件商城</a> 使用noopener noreferrer就是告诉浏览器,新打开的子窗口不需要访问父窗口的任何内容,这是为了防止一些钓鱼网站窃取父窗口的信息。 浏览器在打开新页面时,解析到含有noopener noreferrer时,就知道他们不需要共享页面内容,所以这时候浏览器就会让新链接在一个新页面中打开了。
2019-08-153131- Geek_East参考google官方文档,貌似提交文档的原文是commit navigation, 提交是从浏览器进程发起,至渲染进程,渲染进程确认导航,然后开始正式渲染;Now that the data and the renderer process is ready, an IPC is sent from the browser process to the renderer process to commit the navigation. It also passes on the data stream so the renderer process can keep receiving HTML data. Once the browser process hears confirmation that the commit has happened in the renderer process, the navigation is complete and the document loading phase begins.
作者回复: 多谢,看了你的提示,我重新看了一遍源码的执行过程,原文的确有两个地方描述不妥当,我现在评论区做下修订,稍后更正原文。 1:浏览器进程发出URL请求给网络进程 2:网络进程接收到URL请求之后,便发起网络请求,然后服务器返回HTTP数据到网络进程,网络进程解析HTTP出来响应头数据,并将其转发给浏览器进程 3:浏览器进程接收到网络进程的响应头数据之后,发送CommitNavigation消息到渲染进程,发送CommitNavigation时会携带响应头、等基本信息。 4:渲染进程接收到CommitNavigation消息之后,便开始准备接收HTML数据,接收数据的方式是直接和网络进程建立数据管道 5:最后渲染进程会像浏览器进程“确认提交”,这是告诉浏览器进程,说我已经准备好接受和解析页面数据了 6:最后浏览器进程更新页面状态
2019-11-281591 - ヾ(◍°∇°◍)ノ゙那么浏览器的http的keepalive的connection是什么粒度复用的呢?也是域名加协议头级别吗?
作者回复: 由于正文篇幅有限,无法对keep-alive做详细解释,刚好借着这个问题,我把keep-alive讲清楚。 首先keep-alive是为了解决连接效率不高的问题,http1.0时代,http请求都是短连接的形式,也即是每次请求一个资源都需要和服务器建立连接+传输数据+断开连接,通常,建立连接和断开连接的时间就有可能超过传输数据的时间了,这种短连接的效率是异常的低效。 针对短连接低效的问题,后面就出现了长连接,也就是这里要讲的keep-alive。 你可以把长连接看成是一个管道,一个http请求结束之后,不会关闭连接,下个请求可以复用该连接,这样就省去建立连接和断开连接的时间了,但是他们请求是按照顺序,也就是符合IP+端口规则的资源都可以复用该连接,这就回答了上面提的这个问题。 但是,使用keep-alive同样存在问题,比如一个页面可能有100张图片素材,假设这些图片素材都保存在同一个域名下面,如果只复用一个http管道的话,那么传输100张图片的素材也是非常耗时间的,这就出现了同一时刻并发连接服务器的需求,也就是文中提到同一时刻,对同一域名下面,只能可以发起6个请求,这样就可以大大提升请求效率了。 为什么是6个请求而不是更多了,这是为了服务器性能考虑,如果同一时刻无限制连接,那么可能会导致服务器忙不过来。
2019-08-14965  JawQ_同一站点共用一个渲染进程,那假设有2个标签页是同一站点,我在A标签页面写个死循环,导致页面卡死,B页面是否也是卡死了呢?
JawQ_同一站点共用一个渲染进程,那假设有2个标签页是同一站点,我在A标签页面写个死循环,导致页面卡死,B页面是否也是卡死了呢?作者回复: 你能想到这个问题,说明你已经快思考到最核心的---事件循环机制了,非常好。 多个页面公用一个渲染进程,也就意味着多个页面公用同一个主线程,所有页面的任务都是在同一个主线程上执行,这些任务包括渲染流程,JavaScript执行,用户交互的事件的响应等等,@@@但是@@@ 如果一个标签页里面执行一个死循环,那么意味着该JavaScript代码会一直霸占主线程,这样就导致了其它的页面无法使用该主线程,从而让所有页面都失去响应! 关于循环系统,我会在后续章节做详细分析!
2019-08-15551 前端队长1、用户输入关键词,地址栏判断是搜索内容还是url地址。 如果是搜索内容,会使用浏览器默认搜索引擎加上搜索内容合成url; 如果是域名会加上协议(如https)合成完整的url。 2、然后按下回车。浏览器进程通过IPC(进程间通信)把url传给网络进程(网络进程接收到url才发起真正的网络请求)。 3、网络进程接收到url后,先查找有没有缓存。 有缓存,直接返回缓存的资源。 没有缓存。(进入真正的网络请求)。首先获取域名的IP,系统会首先自动从hosts文件中寻找域名对应的 IP 地址,一旦找到,和服务器建立TCP连接;如果没有找到,则系统会将网址提交 DNS 域名解析服务器进行 IP 地址的解析。 4、利用IP地址和服务器建立TCP连接(3次握手)。 5、建立连接后,浏览器构建数据包(包含请求行,请求头,请求正文,并把该域名相关Cookie等数据附加到请求头),然后向服务器发送请求消息。 6、服务器接收到消息后根据请求信息构建响应数据(包括响应行,响应头,响应正文),然后发送回网络进程。 7、网络进程接收到响应数据后进行解析。 如果发现响应行的返回的状态码为301,302,说明服务器要我们去找别人要数据,找谁呢?找响应头中的Location字段要,Location的内容是需要重定向的地址url。获取到这个url一切重新来过。 如果返回的状态码为200,说明服务器返回了数据。 8、好了,获取到数据以什么方式打开呢?打开的方式不对的话也不行。打开的方式就是 Content-Type。这个属性告诉浏览器服务器返回的数据是什么类型的。如果返回的是网页类型则为 text/html,如果是下载文件类型则为 application/octet-stream 等等。打开的方式不对,则得到的结果也不对。 如果是下载类型,则该请求会被提交给浏览器的下载管理器,同时该请求的流程到此结束。 如果是网页类型,那么浏览器就要准备渲染页面了。 9、渲染页面开始。浏览器进程发出“提交文档”(文档是响应体数据)消息给渲染进程,渲染进程接收到消息后会和网络进程建立传输数据的通道,网络进程将“文档”传输给渲染进程。 10、一旦开始传输,渲染进程便开始渲染界面(详细渲染过程待续。。。) 11、传输完毕,渲染进程会发出“确认提交”消息给浏览器进程。 12、浏览器在接收到“确认提交”消息后,更新浏览器界面状态(包括地址栏信息,仟前进后退历史,web页面和网站安全状态)。 13、页面此时可能还没有渲染完毕,而一旦渲染完毕,渲染进程会发送一个消息给浏览器进程,浏览器接收到这个消息后会停止标签图标的加载动画。 自此,一个完整的页面形成了。
前端队长1、用户输入关键词,地址栏判断是搜索内容还是url地址。 如果是搜索内容,会使用浏览器默认搜索引擎加上搜索内容合成url; 如果是域名会加上协议(如https)合成完整的url。 2、然后按下回车。浏览器进程通过IPC(进程间通信)把url传给网络进程(网络进程接收到url才发起真正的网络请求)。 3、网络进程接收到url后,先查找有没有缓存。 有缓存,直接返回缓存的资源。 没有缓存。(进入真正的网络请求)。首先获取域名的IP,系统会首先自动从hosts文件中寻找域名对应的 IP 地址,一旦找到,和服务器建立TCP连接;如果没有找到,则系统会将网址提交 DNS 域名解析服务器进行 IP 地址的解析。 4、利用IP地址和服务器建立TCP连接(3次握手)。 5、建立连接后,浏览器构建数据包(包含请求行,请求头,请求正文,并把该域名相关Cookie等数据附加到请求头),然后向服务器发送请求消息。 6、服务器接收到消息后根据请求信息构建响应数据(包括响应行,响应头,响应正文),然后发送回网络进程。 7、网络进程接收到响应数据后进行解析。 如果发现响应行的返回的状态码为301,302,说明服务器要我们去找别人要数据,找谁呢?找响应头中的Location字段要,Location的内容是需要重定向的地址url。获取到这个url一切重新来过。 如果返回的状态码为200,说明服务器返回了数据。 8、好了,获取到数据以什么方式打开呢?打开的方式不对的话也不行。打开的方式就是 Content-Type。这个属性告诉浏览器服务器返回的数据是什么类型的。如果返回的是网页类型则为 text/html,如果是下载文件类型则为 application/octet-stream 等等。打开的方式不对,则得到的结果也不对。 如果是下载类型,则该请求会被提交给浏览器的下载管理器,同时该请求的流程到此结束。 如果是网页类型,那么浏览器就要准备渲染页面了。 9、渲染页面开始。浏览器进程发出“提交文档”(文档是响应体数据)消息给渲染进程,渲染进程接收到消息后会和网络进程建立传输数据的通道,网络进程将“文档”传输给渲染进程。 10、一旦开始传输,渲染进程便开始渲染界面(详细渲染过程待续。。。) 11、传输完毕,渲染进程会发出“确认提交”消息给浏览器进程。 12、浏览器在接收到“确认提交”消息后,更新浏览器界面状态(包括地址栏信息,仟前进后退历史,web页面和网站安全状态)。 13、页面此时可能还没有渲染完毕,而一旦渲染完毕,渲染进程会发送一个消息给浏览器进程,浏览器接收到这个消息后会停止标签图标的加载动画。 自此,一个完整的页面形成了。作者回复: 超级赞
2019-08-151240 Oliver这也就解释了为什么在浏览器的地址栏里面输入了一个地址后,之前的页面没有立马消失,而是要加载一会儿才会更新页面。 第一步应该是触发当前页的卸载事件和收集需要释放内存,这也占用了一些时间,但大头应该是请求新的url时的返回
Oliver这也就解释了为什么在浏览器的地址栏里面输入了一个地址后,之前的页面没有立马消失,而是要加载一会儿才会更新页面。 第一步应该是触发当前页的卸载事件和收集需要释放内存,这也占用了一些时间,但大头应该是请求新的url时的返回作者回复: 补充的好 👍
2019-08-13226- tokey老师!如果一个页面发出请求后就关闭了,那么这个页面的进程就关闭了吧?那么 tcp 的连接还会不会有(请求能不能到达服务端),如果连接成功服务端处理过后 tcp 断开需要四次挥手,此时服务器收不到客户端的断开确认消息,服务器会处于什么状态(一直等待么)?
作者回复: 页面进程关闭后,浏览器进程会接收到关闭的消息,然后浏览器进程会通知网络进程主动断开该页面的所有tcp连接。 所以你不用担心页面关闭会导致网络问题!
2019-09-03222  Mr. Cheng作为一个从其他行业跳到web前端的,网络方面的知识欠缺太多,虽然在其他地方也看了很多,但这个专栏讲的清晰易懂,大赞
Mr. Cheng作为一个从其他行业跳到web前端的,网络方面的知识欠缺太多,虽然在其他地方也看了很多,但这个专栏讲的清晰易懂,大赞作者回复: 谢谢,这也让我很开心
2019-08-1416